
Security Proofs for Embedded Systems (PROOFS) posted August 2016
Crypto and CHES are now over. As always, a tiny conference takes place the day after CHES: the Security Proofs for Embedded Systems or PROOFS.
Yuval Yarom - Thwarting cache-based side-channel attacks
Microarchitectures implement a specification called the instruction set architecture (ISA), and lots of the time it's about a lot more than the ISA!

There is contention at one place, the cache! Since it's shared (because it's smaller than the memory), if we know where the victim's memory is mapped in the cache, you have an attack!

(slides from hardware secrets)
Yarom explained the Prime+Probe attack as well, where you load a cache-sized buffer from the memory and see what the victim is replacing there. This attack is possible on the L1 cache as well as the LLC cache. For more information on these attacks check my notes on the CHES tutorial. He also talked about the Flush+Reload. The whole point was to explain that constant-time is one way to circumvent the problem.
You can look at these attacks in code with Yarom's tool Mastik. The Prime+Probe is implemented on the L1 cache just by filling the whole cache with a calloc (check L1-capture.c). It's on the whole cache because it's the L1 cache that we're sharing with the victim process on a single core, the LLC attack is quite different (check L3-capture.c).
Note that I don't agree here because constant-time doesn't mean same operations done/calls accessed. For example see "padding time" techniques by boneh, braun and jana.
But the 3-rules definition of Yarom for constant-time programming is quite different from mine:
- no instructions with data-dependent execution time
- no secret-dependent flow control
- no secret-dependent memory access
To test for constant-time dynamically, we can use ctgrind, a modified valgrind by Adam Langley. We can also do some static source analysis with FlowTracker, but doesn't always work since the compiler might completely change expected results. The last way of doing it is binary analysis with CacheAudit, not perfect either.
Interestingly, there were also some questions from Michael Hamburg about fooling the branch predictor and the branch predictor target.
Stjepan Picek - Template Attack vs. Bayes Classifier
Profiled Attacks are one of the most powerful side-channel attacks we can do. One of them is Template Attack, the most powerful attack from the information theoretic point of view. Machine Learning (ML) is used heavily for these attacks.
What's a template attack? Found a good definition in Practical Template Attacks
The method used in the template attack is as follows: First a strategy to build a model of all possible operations is carried out. The term “all possible operations” usually refers to the cryptographic algorithm (or a part of it) being executed using all possible key values. The model of captured side-channel information for one operation is called template and consists of information about the typical signal to expect as well as a noise-characterization for that particular case. After that, the attack is started and the trace of a single operation (e.g. the key-scheduling of an algorithm) is captured. Using the templates created before which represent all key-values, the side-channel information of the attacked device is classified and assigned to one or more of the templates. The goal is to significantly reduce the number of possible keys or even come up with the used key
Someone else explained to me with an example. You encrypt many known plaintext with AES, with many different keys (you only change the first byte, so 256 possible ones), then you obtain traces and statistics on that. Then you do the real attack, obtain the traces, compare to find the first byte of the key.
The simplest ML attack you can do is Naive Bayes where there is no dependency (so the opposite of a template attacks). Between Naive Bayes and Template attacks, right in the middle, you have Averaged One-Dependence Estimators (A0DE)

Stjepan also talked about Probably approximately correct learning (PAC learning) but said that although it's great you couldn't use it all the time.
Sylvain Guilley - Optimal Side-Channel Attacks for Multivariate Leakages and Multiple Models
In real life, leakages are multi-variate (we have traces with many points) as well as multi-model (we can use the hamming weight and other ways of finding bias).

You acquire traces (usually called an acquisition campaign), and then make a guess on the bytes of the key: it will give you the output of the first Sbox. If we look at traces, we want to get all the information out of it so we uses matrices to do the template attack.
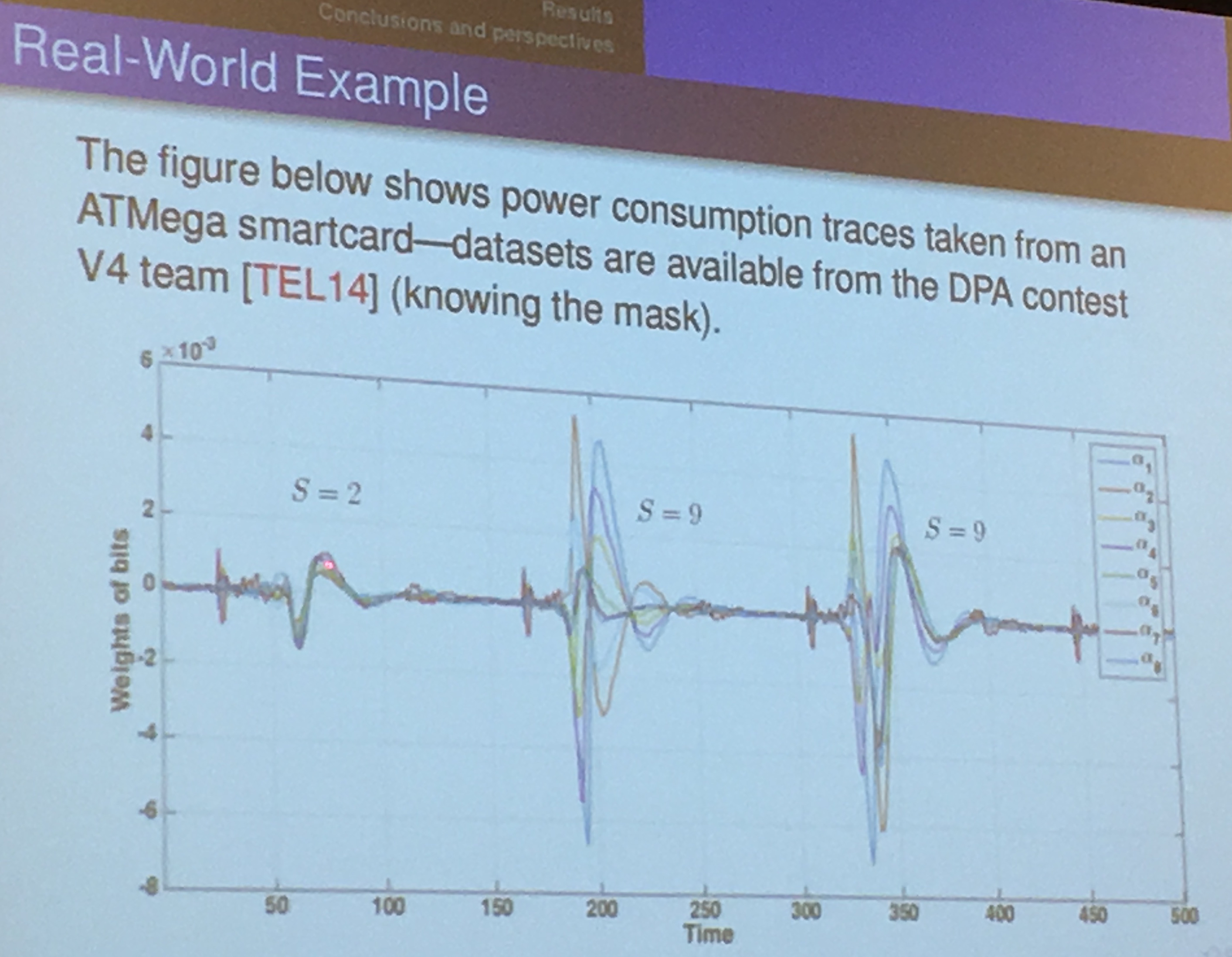
you find the \(\alpha\) by doing many measurements (profiling), the matrix will be well-conditioned and not ill-conditioned (unless you have redundant data, which never happens in practice).
In the field of numerical analysis, the condition number of a function with respect to an argument measures how much the output value of the function can change for a small change in the input argument. This is used to measure how sensitive a function is to changes or errors in the input, and how much error in the output results from an error in the input.
Jakub Breier - Mistakes Are Proof That You Are Trying: On Verifying Software Encoding Schemes' Resistance to Fault Injection Attacks
The first software information hiding scheme was done in 2001: dual-rail precharge logic (DPL) to reduce the dependence of the power consumption on the data. It's also done on software and that's what they looked at.

Static-DPL XOR uses look-up tables to implement all the logical gates. Bit Slicing is used as well, and 1 is encoded as 01, and 0 encoded as 10.
Bit slicing is a technique for constructing a processor from modules of smaller bit width. Each of these components processes one bit field or "slice" of an operand. The grouped processing components would then have the capability to process the chosen full word-length of a particular software design.
for example, bitslicing AES would mean convert all operations to operations like AND, OR, XOR, NOT that take two bits at most as input, and parallelize them all.
The static-DPL XOR's advantage is that any intermediate value at any point of time has a Hamming weight of 4. It is apparently explained further in the Prince cipher paper
Device-specific encoding XOR is minimizing the variance of the encoded intermediate values.
They wrote a fault simulator in java, doing bit flips, random byte fault, instruction skip and stuck-at fault. It seems that according to their tests only the Static-Encoding XOR would propagate faults.
Margaux Dugardin - Using Modular Extension to Provably Protect Edwards Curves Against Fault Attacks
Fault attacks can be
- safe-error attacks if it's done on a dummy operation
- cryptosystems parameters alteration
- aiming for Differential Fault Analysis DFA (bellcore attack, sign-change attacks)
If you look at double and add for elliptic curves

countermeasure is to verify the input/ouput to see if it's on the right curve. But it's ineffective against sign-change faults (Blomer et al.)

A countermeasure for that is to use Shamir's countermeasure. You do another computation in a different field (In an integer ring actually, \(Z_{pr}\) in the picture).

BOS countermeasure: You can also do the other computation on another smaller curve (Blomer et all)

But this countermeasure is not working for Weierstrass curves. To correct BOS' countermeasure they defined the curve to be an edwards curve or a twisted edwards curve.
Ryan Kastner - Moving Hardware from “Security through Obscurity” to “Secure by Design”
For Ryan, the bigger iceberg (see Yarom's talk) is the hardware we don't think about when we want to design secure software.

System of Chips design are extremely complex, we take years to develop them and we release them "forever". After that no patch. We need to get it right the first time.
Everything is becoming more and more complex. We used to be able to verify stuff "easily" with Verilog
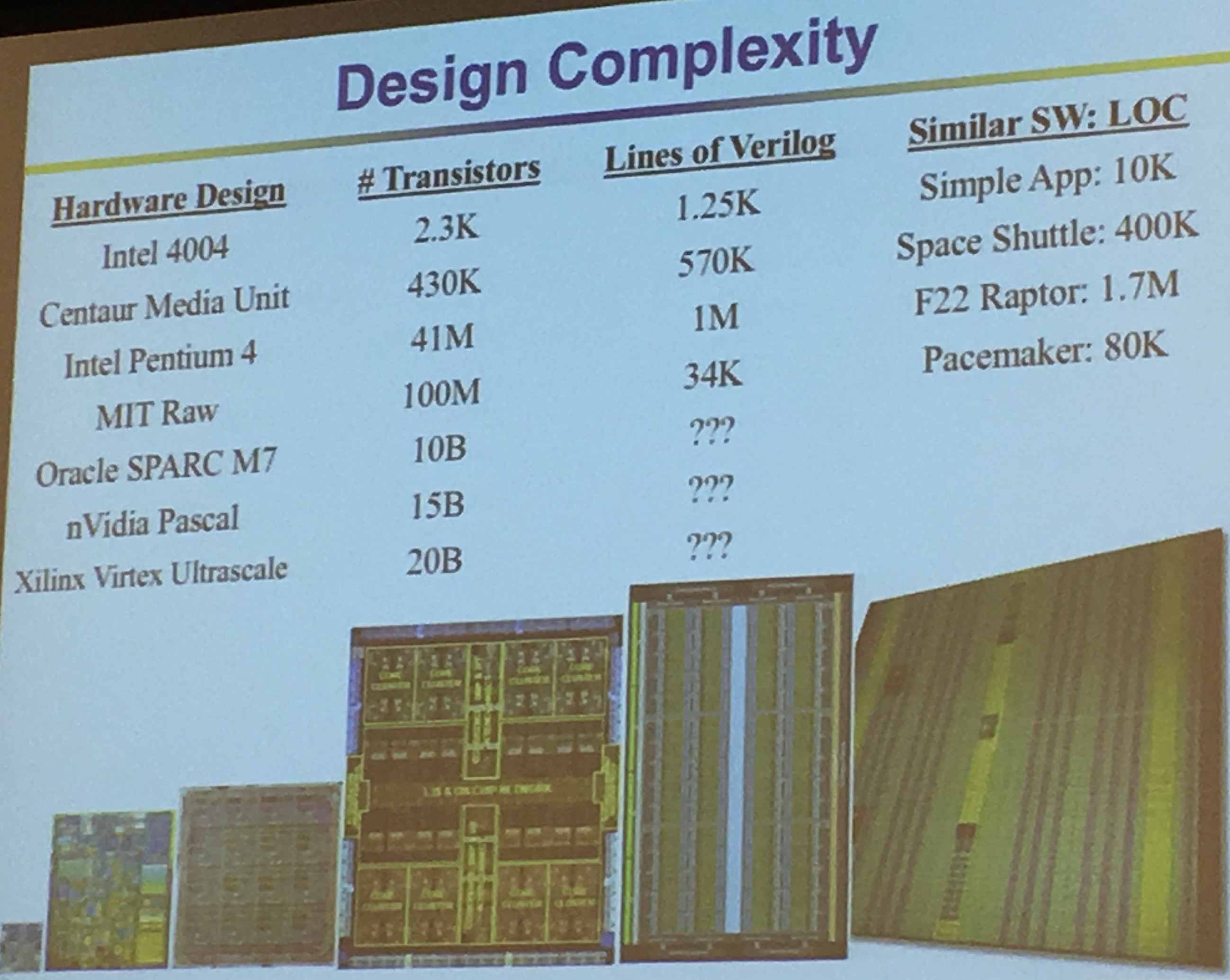
Mike Keating estimates that there is one bug for 10 lines of code in SoCs (from the art of good design). RedHat Linux has an evaluation thingy called Best Effort Safety (EAL 4+), it costs $30-$40 per LOC. Integrity RTOS: Design for Formal Evaluation (EAL 6+) is $10,000 for LOC. For big systems we can't really use them...
A lot of constructors do security through obfuscation (look at ARM, Intel, ...). It's to hard to get back the RTL, by appeal to authority (e.g. "we're Intel"), by hand waving (e.g. "we do design reviews")...
They look directly at gates, and one of the input bit is untrusted, the output is untrusted. Unless! If we have a trusted 0 input AND'ed with an untrusted input. The untrusted input won't influence the output so the output will be trusted (i.e. 0 & 1 = 0 and 0 & 0 = 0).
Looks likes they're using GLIFT to do that. But they're also looking to commercialize these ideas with Tortuga Logic.
Because they look at things from such a low perspective they can see timing leaks and key leaks and etc...

It took them about 3 years to transform the theoretical research into a commercialized product.
Matthias Hiller - Algebraic Security Analysis of Key Generation with Physical Unclonable Functions
Physical Unclonable Functions (PUFs) allows you to derive a unique fingerprint, if you want to get a key out of that you need to derive it into the right format.
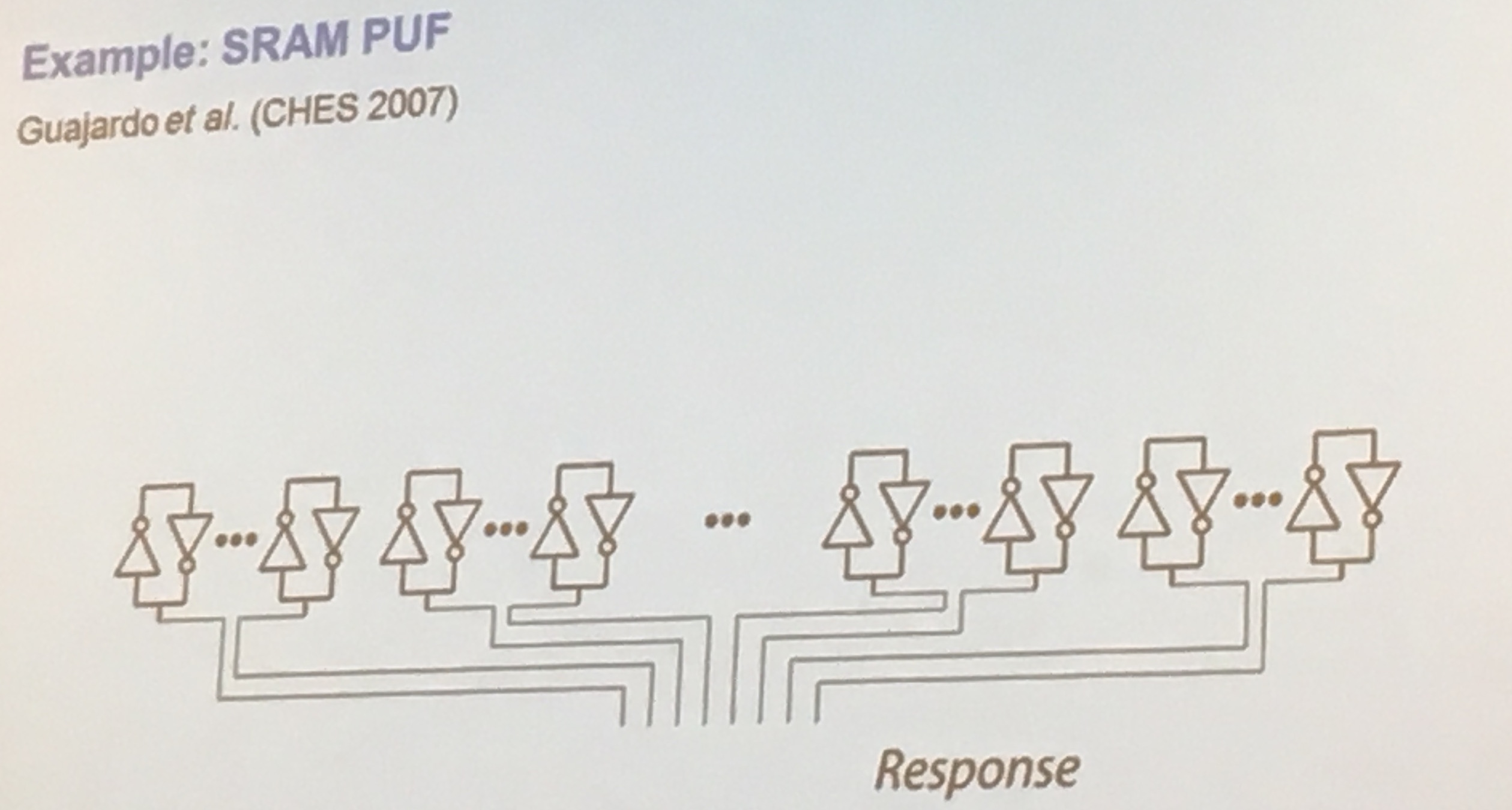
Static RAM (SRAM) is a way to build PUFs, if uninitialized the bits are set "randomly" which you can use to generate your first randomness.
Apparently some PUFs have 15% of errors. Others might have 1%. A lot of work needs to be done in error correction. But error correcting codes (ECC) can leak data about the key! Their work is to work on an upper bound on what is leaked by the ECC.
PUF works by giving you a response, more from wikipedia:
Rather than embodying a single cryptographic key, PUFs implement challenge–response authentication to evaluate this microstructure. When a physical stimulus is applied to the structure, it reacts in an unpredictable (but repeatable) way due to the complex interaction of the stimulus with the physical microstructure of the device. This exact microstructure depends on physical factors introduced during manufacture which are unpredictable (like a fair coin). The applied stimulus is called the challenge, and the reaction of the PUF is called the response. A specific challenge and its corresponding response together form a challenge–response pair or CRP. The device's identity is established by the properties of the microstructure itself. As this structure is not directly revealed by the challenge-response mechanism, such a device is resistant to spoofing attacks.
They algebraically transformed the properties of a PUF, using a matrix, to facilitate their proofs:
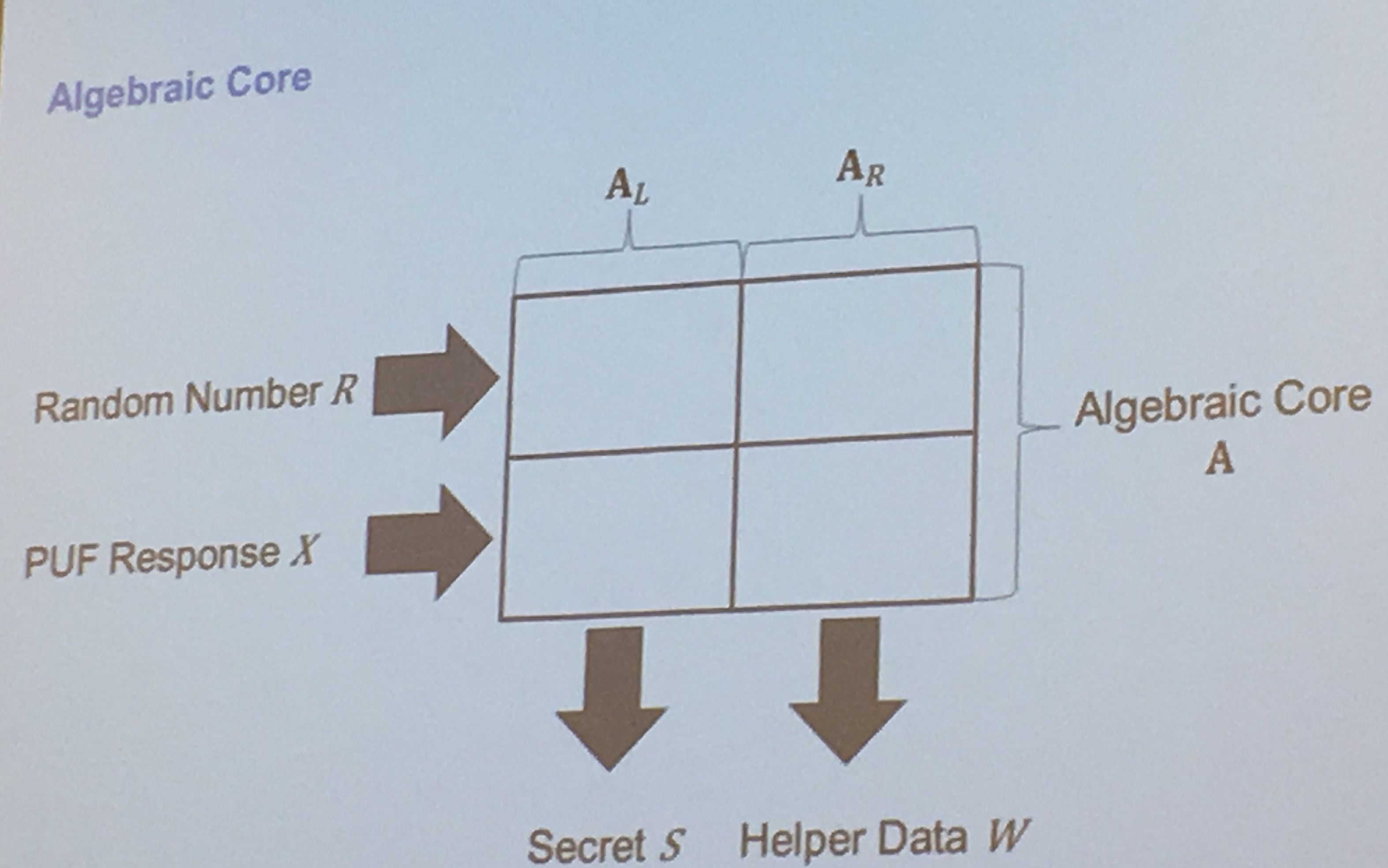
sometimes a PUF response is directly used as a key, here's how they get the algebraic representation of key generation for PUFs:


Comments
leave a comment...