
KangarooTwelve posted May 2017

In late 2008, 64 candidates took part in NIST's hashing competition, fighting to replace the SHA-2 family of hash functions.
Keccak won the SHA-3 competition, and became the FIPS 202 standard on August 5, 2015.
All the other contenders lost. The final round included Skein, JH, Grøstl and BLAKE.
Interestingly in 2012, right in the middle of the competition, BLAKE2 was released. Being too late to take part in the fight to become SHA-3, it just stood on its own awkwardly.
Fast forward to this day, you can now read an impressive list of applications, libraries and standards making use of BLAKE2. Argon2 the winner of the Password Hashing Competition, the Noise protocol framework, libsodium, ...
On their page you can read:
BLAKE2 is a cryptographic hash function faster than MD5, SHA-1, SHA-2, and SHA-3, yet is at least as secure as the latest standard SHA-3. BLAKE2 has been adopted by many projects due to its high speed, security, and simplicity.
And it is indeed for the speed that BLAKE2 is praised. But what exactly is BLAKE2?
BLAKE2 relies on (essentially) the same core algorithm as BLAKE, which has been intensively analyzed since 2008 within the SHA-3 competition, and which was one of the 5 finalists. NIST's final report writes that BLAKE has a "very large security margin", and that the the cryptanalysis performed on it has "a great deal of depth". The best academic attack on BLAKE (and BLAKE2) works on a reduced version with 2.5 rounds, whereas BLAKE2b does 12 rounds, and BLAKE2s does 10 rounds. But even this attack is not practical: it only shows for example that with 2.5 rounds, the preimage security of BLAKE2b is downgraded from 512 bits to 481 bits, or that the collision security of BLAKE2s is downgraded from 128 bits to 112 bits (which is similar to the security of 2048-bit RSA).
And that's where BLAKE2 shines. It's a modern and secure hash function that performs better than SHA-3 in software. SHA-3 is fast in hardware, this is true, but Intel does not have a good track record of quickly implementing cryptography in hardware. It is only in 2013 that SHA-2 joined Intel's set of instructions, along with SHA-1...
What is being done about it?
Some people are recommending SHAKE. Here is what the Go SHA-3 library says on the subject:
If you aren't sure what function you need, use SHAKE256 with at least 64 bytes of output. The SHAKE instances are faster than the SHA3 instances; the latter have to allocate memory to conform to the hash.Hash interface.
But why is SHA-3 slow in software? How can SHAKE be faster?
This is because SHA-3's parameters are weirdly big. It is hard to know exactly why. The NIST provided some vague explanations. Other reasons might include:
- Not to be less secure than SHA-2. SHA-2 had 256-bit security against pre-image attacks so SHA-3 had to provide the same (or at least a minimum of) 256-bit security against these attacks. (Thanks to Krisztián Pintér for pointing this out.)
- To be more secure than SHA-2. Since SHA-2 revealed itself to be more secure than we previously thought, there was no reason to develop a similar replacement.
- To give some credits to the NIST. In view of people's concerns with NIST's ties with the NSA, they could not afford to act lightly around security parameters.
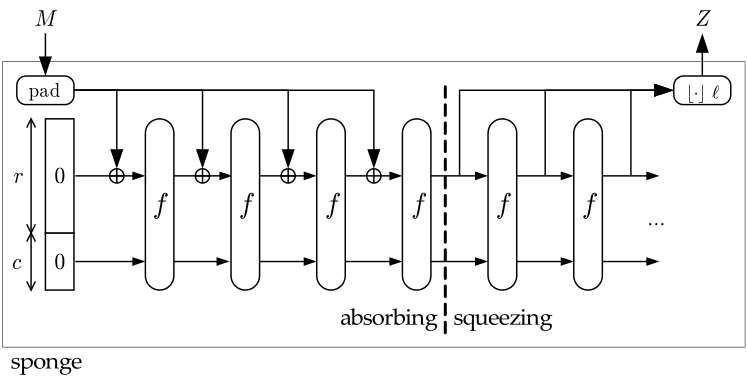
The following table shows the parameters of the SHAKE and SHA-3 constructions. To understand them, you need to understand two of the parameters:
- The rate (
r): it is the block size of the hash function. The smaller, the more computation will have to be done to process the whole input (more calls to the permutation (f)). - The capacity (
c): it is the secret part of the hash function. You never reveal this! The bigger the better, but the bigger the smaller is your rate :)
| algorithm | rate | capacity | mode (d) | output length (bits) | security level (bits) |
| SHAKE128 | 1344 | 256 | 0x1F | unlimited | 128 |
| SHAKE256 | 1088 | 512 | 0x1F | unlimited | 256 |
| SHA3-224 | 1152 | 448 | 0x06 | 224 | 112 |
| SHA3-256 | 1088 | 512 | 0x06 | 256 | 128 |
| SHA3-384 | 832 | 768 | 0x06 | 384 | 192 |
| SHA3-512 | 576 | 1024 | 0x06 | 512 | 256 |
The problem here is that SHA-3's capacities is way bigger than it has to be.
512 bits of capacity (secret) for SHA3-256 provides the square root of security against (second pre-image attacks (that is 256-bit security, assuming that the output used is long enough). SHA3-256's output is 256 bits in length, which gives us the square root of security (128-bit) against collision attacks (birthday bound). We end up with the same theoretical security properties of SHA-256, which is questionably large for most applications.
Keccak even has a page to tune its security requirements which doesn't advise such capacities.
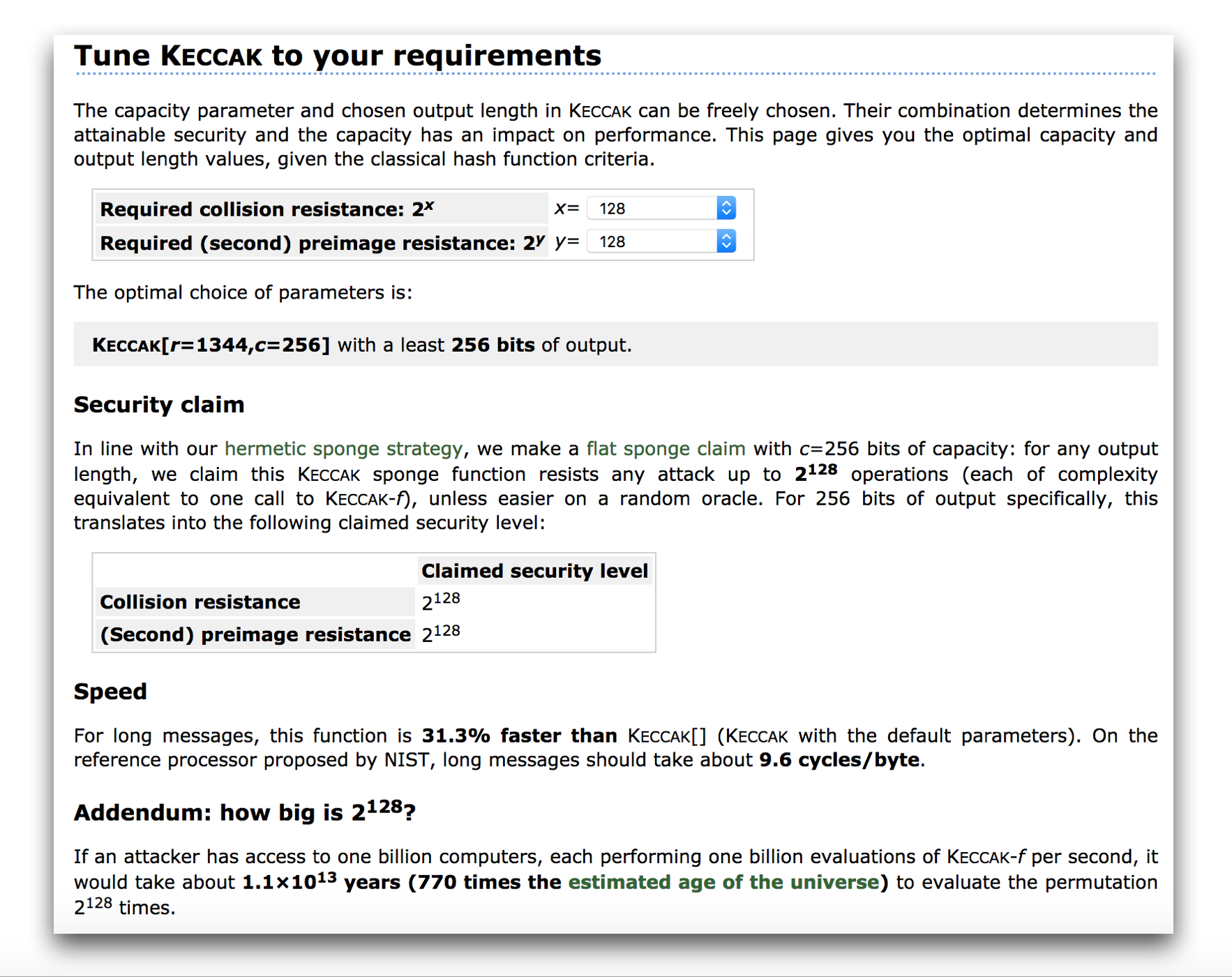
Is this really the end?
Of course not. In the end, SHA-3 is a big name, people will use it because they hear about it being the standard. It's a good thing! SHA-3 is a good hash function. People who know what they are doing, and who care about speed, will use BLAKE2 which is equally as good of a choice.
But these are not the last words of the Keccak's team, and not the last one of this blog post either. Keccak is indeed a surprisingly well thought construction relying on a single permutation. Used in the right way it HAS to be fast.
Mid-2016, the Keccak team came back with a new algorithm called KangarooTwelve. And you might have guessed, it is to SHA-3 what BLAKE2 is to BLAKE.
It came with 12 rounds instead of 24 (which is still a huge number compared to current cryptanalysis) and some sane parameters: a capacity of 256 bits like the SHAKE functions.
Tree hashing, a feature allowing you to parallelize hashing of large files, was also added to the mix! Although sc00bz says that they do not provide a "tree hashing" construction but rather a" leaves stapled to a pole" construction.
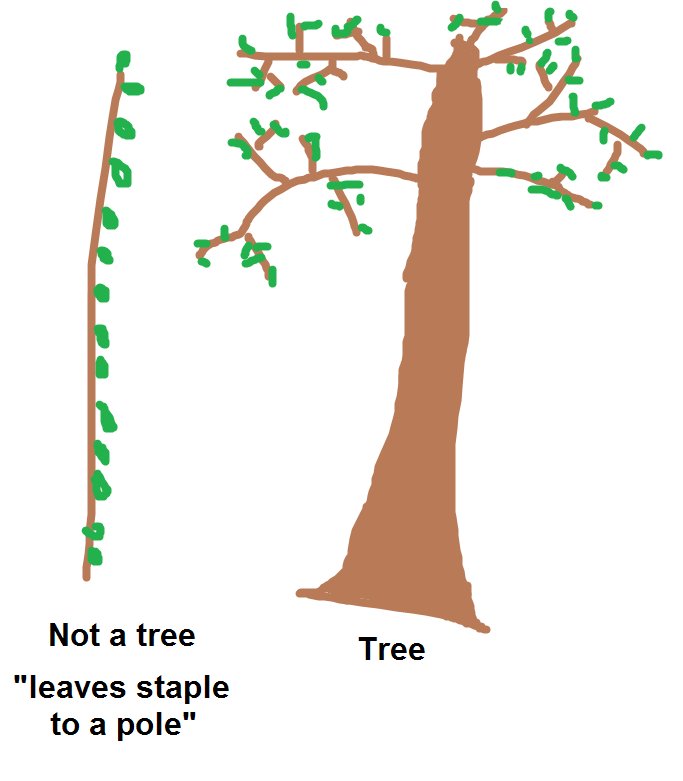
credit: sc00bz
Alright, how does KangarooTwelve work?
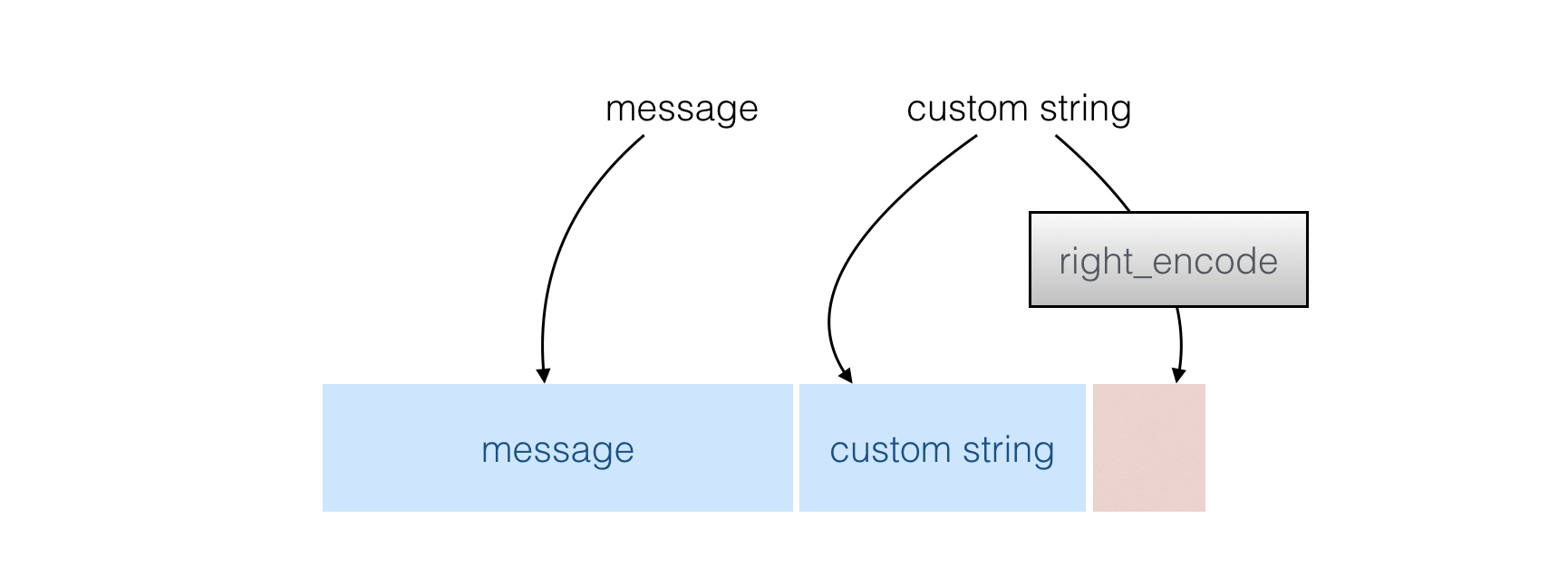
→ First your input is mixed with a "customization string" (which allows you to get different results in different contexts) and the encoding of the length of the customization string (done with right_encode())
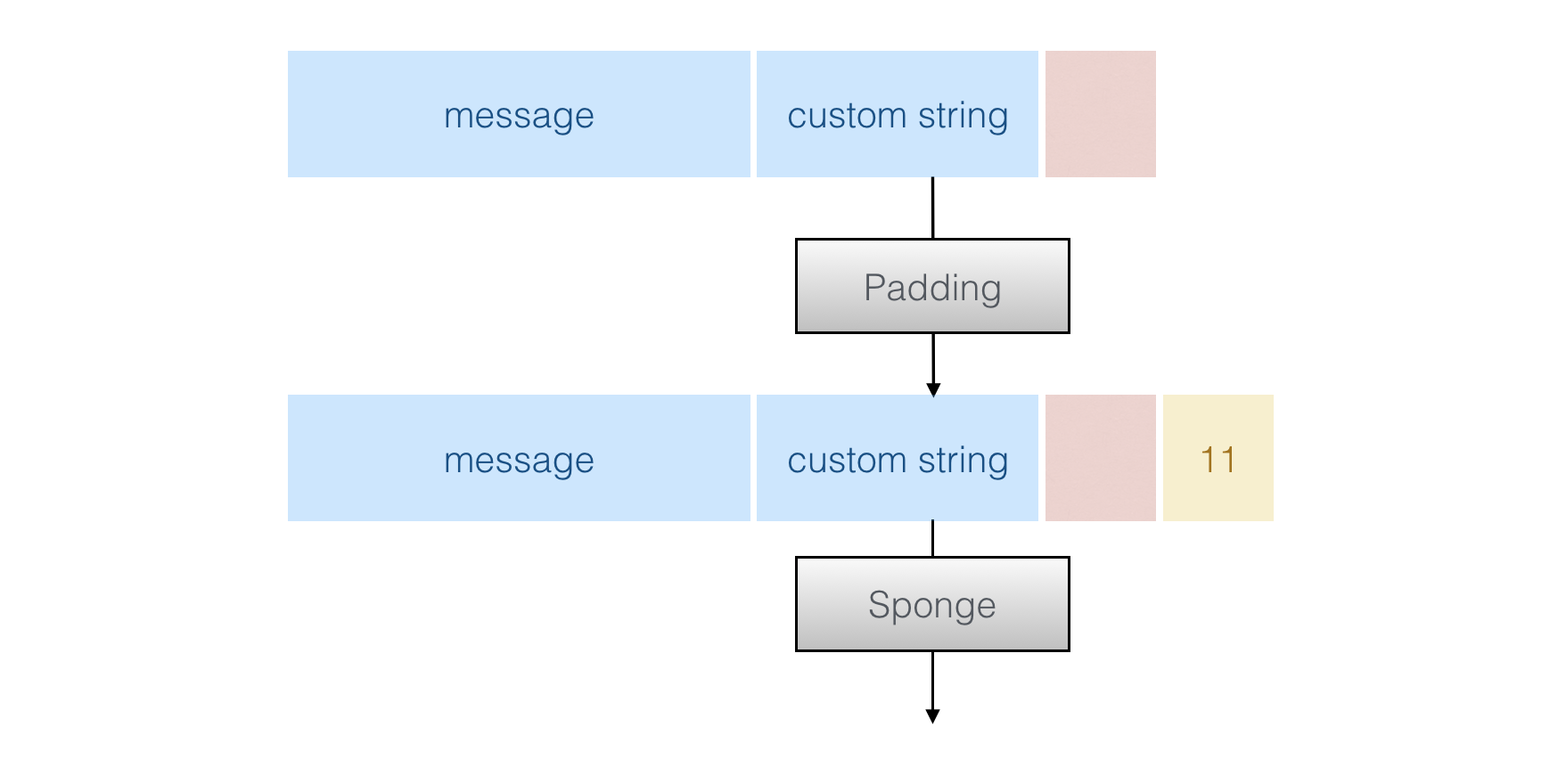
→ Second if the message is "short" (≤8192bytes), the tree hashing is not used. The previous blob is padded and permuted with the sponge. Here the sponge call is Keccak with its default multi-rate padding 101*. The output can be as long as you want like the SHAKE functions.
→ Third if the message is "long", it is divided into "chunks" of 8192 bytes. Each chunk (except the first one) is padded and permuted (so effectively hashed). The end result is structured/concatenated/padded and passed through the Sponge again.
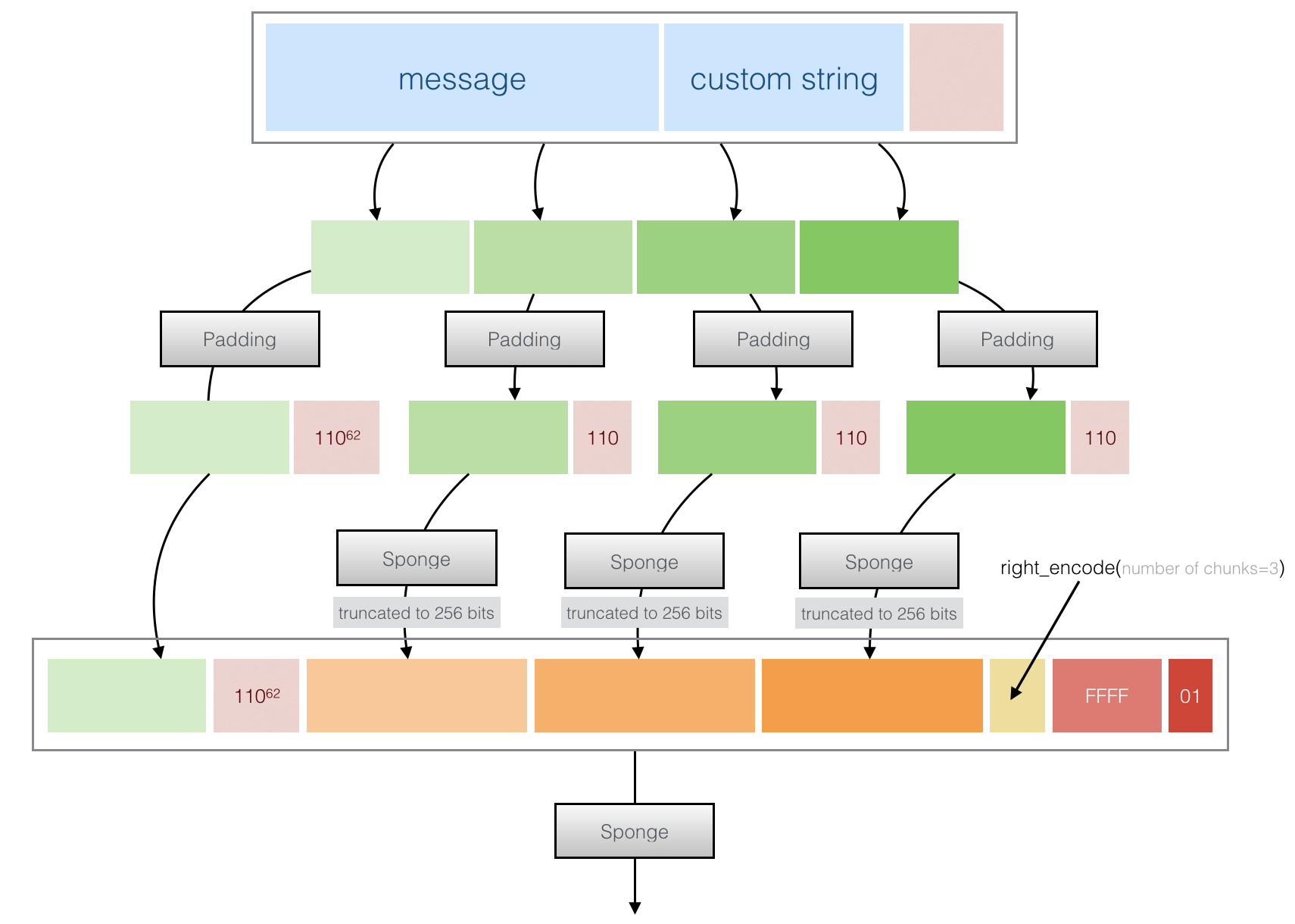
This allows each different chunk to be hashed in parallel on different cores or via some SIMD magic.
Before you go, here is a simple python implementation and the reference C implementation.
Daemen gave some performance estimations for KangarooTwelve during the rump session of Crypto 2016:
- Intel Core i5-4570 (Haswell) 4.15 c/b for short input and 1.44 c/b for long input
- Intel Core i5-6500 (Skylake) 3.72 c/b for short input and 1.22 c/b for long input
- Intel Xeon Phi 7250 (Knights Landing) 4.56 c/b for short input and 0.74 c/b for long input
Thank-you for reading!

Comments
Don
1. How about calling the construction "Vine Construction" or "Vitis Construction" instead due to its look?
2. What about other SHA3 competition finalists e.g. BLAKE2 and Skein in "vine" mode, has it been done before?
Don
3. What about reduced round and mutated Fugue, Hamsi and Luffa? Those are also sponge functions, is it not?
leave a comment...