
The Strobe Protocol Framework posted August 2017
Introduction
The Strobe Protocol Framework is a specification, available here, which you can use to implement a primitive called the Strobe Duplex Construction. The implemented Strobe object should respond to a dozen of calls that can be combined together to allow you to generate random numbers, derive keys, hash, encrypt, authenticate, and even build complex symmetric protocols.
The thing is sexy for several reasons:
- you only use a single primitive to do all of your symmetric crypto
- it makes the code size of your library extremely small, easy to fit in embedded devices and easy to audit
- on top of that it allows you to create TLS-like protocols
- every message/operation of your protocol depends on all the previous messages/operations
The last one might remind you of Noise which is a protocol framework as well that mostly focus on the asymmetric part (handshake). More on that later :)
Overview
From a high level point of view, here is a very simple example of using it to hash a string:
myHash = Strobe_init("hash")
myHash.AD("something to be hashed")
hash = myHash.PRF(outputLen=16)You can see that you first instantiate a Strobe object with a custom name. I chose "hash" here but it could have been anything. The point is to personalize the result to your own protocol/system: initializing Strobe with a different name would give you a different hash function.
Here two functions are used: AD and PRF. The first one to insert the data you're about to hash, the second one to obtain a digest of 16 bytes. Easy right?
Another example to derive keys:
KDF = Strobe_init("deriving keys for something")
KDF.KEY(keyInput)
key1 = KDF.PRF(outputLen=16)
key2 = KDF.PRF(outputLen=16)Here we use a new call KEY which is similar to AD but provides forward-secrecy as well. It is not needed here but it looks nicer and so I'll use it. We then split the output in two in order to form two new keys out of our first one.
Let me now give you a more complex example. So far we've only used Strobe to create primitives, what if I wanted to create a protocol? For example on the client side I could write:
myProtocol = Strobe_init("my protocol v1.0")
myProtocol.KEY(sharedSecret)
buffer += myProtocol.send_ENC("GET /")
buffer += myProtocol.send_MAC(len=16)
// send the buffer
// receive a ciphertext
message = myProtocol.recv_ENC(ciphertext[:-16])
ok = myProtocol.recv_MAC(ciphertext[-16:])
if !ok {
// reset the connection
}Since this is a symmetric protocol, something similar should be done on the server side. The code above initializes an instance of Strobe called "my protocol v1.0", and then keys it with a pre-shared secret or some key exchange output. Whatever you like to put in there. Then it encrypts the GET request and sends the ciphertext along with an authentication tag of 16 bytes (should be enough). The client then receives some reply and uses the inverse operations to decrypt and verify the integrity of the message. This is what the server must have done when it received the GET request as well. This is pretty simple right?
There's so much more Strobe can do, it is up to you to build your own protocol using the different calls Strobe provides. Here is the full list:
- AD: Absorbs data to authenticate.
- KEY: Absorbs a key.
- PRF: Generates a random output (forward secure).
- send_CLR: Sends non-encrypted data.
- recv_CLR: Receives non-encrypted data.
- send_ENC: Encrypts data.
- recv_ENC: Decrypts data.
- send_MAC: Produces an authentication tag.
- recv_MAC: Verifies an authentication tag.
- RATCHET: Introduce forward secrecy.
There are also meta variants of some of these operations which allow you to specify that what you're operating on is some frame data and not the real data itself. But this is just a detail.
How does it work?
Under its surface, Strobe is a duplex construction. Before I can explain that, let me first explain the sponge construction.
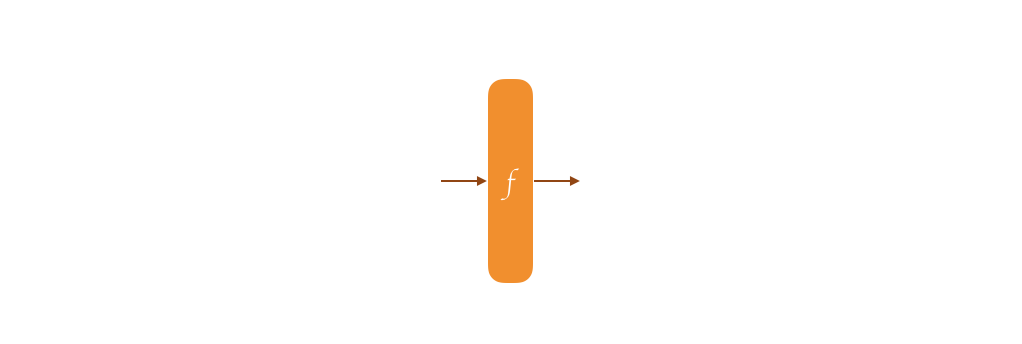
A sponge belongs to a field in cryptography called permutation-based cryptography. This is because at its core, it works on top of a permutation. The whole security of the thing is proven as long as your permutation is secure, meaning that it behaves like a random oracle. What's a permutation? Oh sorry, well, imagine the AES block cipher with a fixed key of 00000000000000000. It takes all the possible inputs of 128-bit, and it will give you all the possible outputs of 128-bit. It's a one-to-one mapping, for one plaintext there is always one ciphertext. That's a permutation.
SHA-3 is based on the sponge construction by the way, and it uses the keccak-f[1600] permutation at its core. Its security was assessed by long years of cryptanalysis (read: people trying to break it) and it works very similarly as AES: it has a series of steps that modify an input, and these steps are repeated many many times in what we call rounds. AES-128 has 10 rounds, Keccak-f[1600] has 24 rounds. The 1600 part of the name means that it has an input/ouput size of 1600 bits.
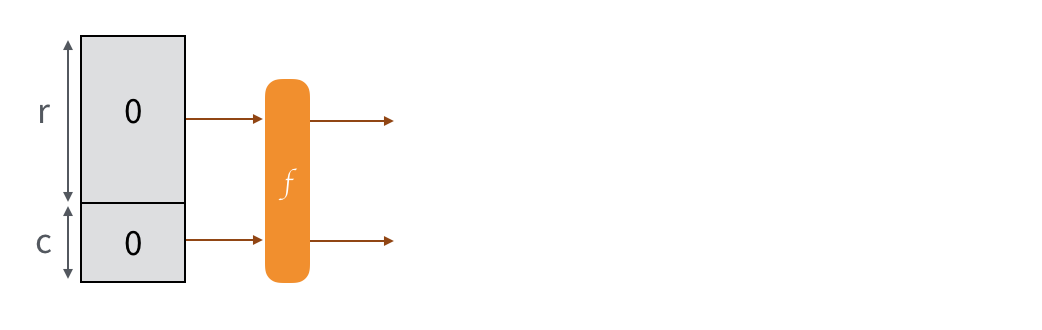
So here our permutation is Keccak-f[1600], and we imagine that our input/output is divided into two parts: the public part (rate) and the secret part (capacity). Intuitively we'll say that the bigger the secret part is, the more secure the construction is. And indeed, SHA-3 has several flavors that will use different sizes according to the security advertised.
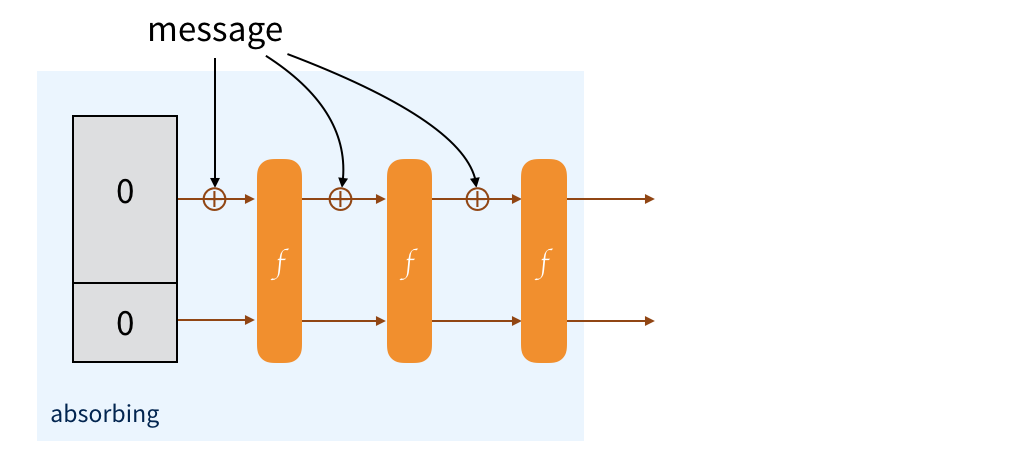
The message is padded and split into multiple blocks of the same size as the public part. To absorb them into our sponge, we just XOR each blocks with the public part of the state, then we permute the state.
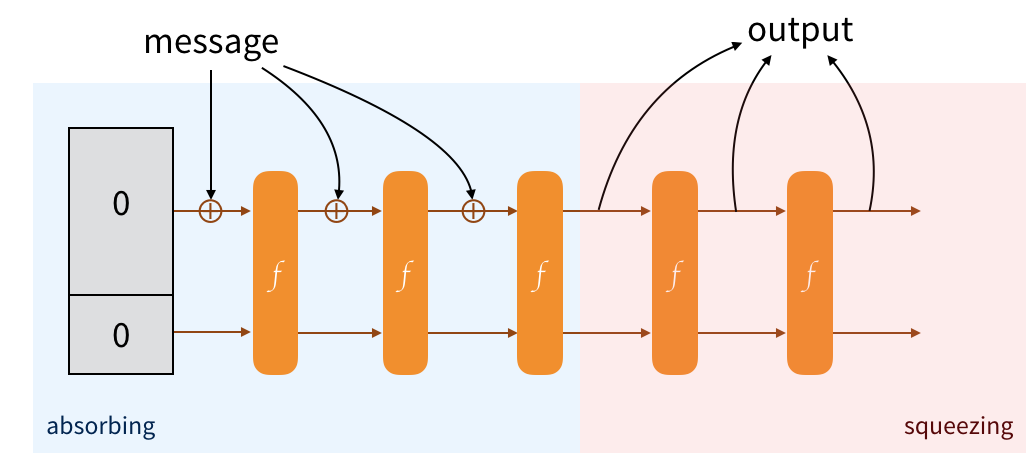
To obtain an output from this construction, we just retrieve the public part of our state. If it's not enough, we permute to modify the state of the sponge, then we collect the new public part so that it can be appended to the previous one. And we continue to do that until we have enough. If it's too much we truncate :)
And that's it! It's a sponge, we absorb and we squeeze. Makes sense right?
This is exactly how SHA-3 works, and the output is your hash.
What if we're not done though? What if we want to continue absorbing, then squeeze again, then absorb again, etc... This would give us a nice property: everything that we squeeze will depend on everything that has been absorbed and squeezed so far. This provides us transcript consistency.
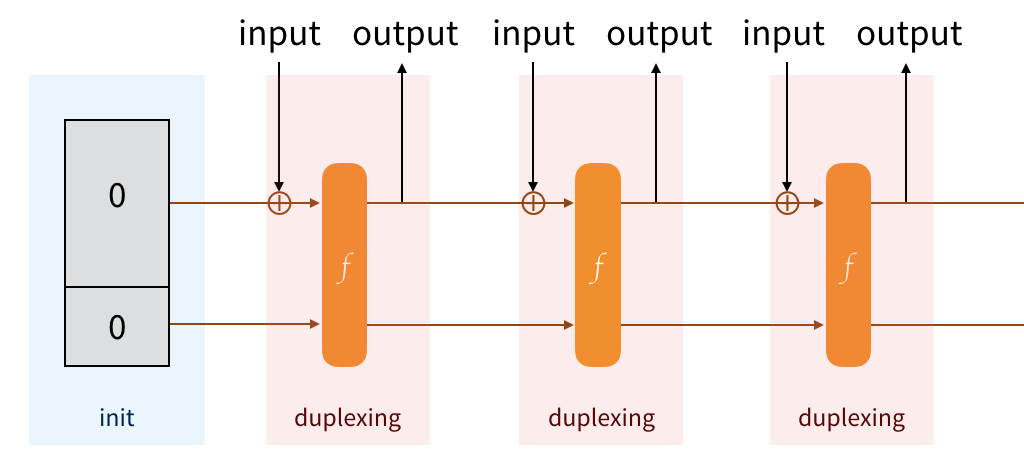
The Keccak team said we can, and they created the Duplex construction. It's just something that allows us to absorb, to squeeze, to absorb, to squeeze, and on and on...
Building Strobe
"How is Strobe constructed on top of the Duplex construction?" you may ask. And I will give you an intuition of an answer.
Strobe has fundamentally 3 types of internal operations, that are used to build the operations we've previously saw (KEY, AD, Send_ENC, ...). They are the following:
- default:
state = input ⊕ state - cbefore:
state = input - cafter:
output, state = input ⊕ state
The default one simply absorbs the input with the state. This is useful for any kind of operation since we want them to affect the outcome of the next ones.
The cbefore internal operation allows you to replace the bits of the state with your input. This is useful when we want to provide forward-secrecy: if the state is later leaked, the attacker will not be able to recover a previous state since bits of the rate have been erased. This is used to construct the KEY, RATCHET and PRF operations. While KEY replaces the state with bits from a key, RATCHET and PRF replaces the state with zeros.
cafter is pretty much the same as the default operation, except that it also retrieves the output of the XOR. If you've seen how stream ciphers or one-time pads work, you might have recognized that this is how we can encrypt our plaintext. And if it wasn't more obvious to you, this is what will be used to construct the Send_ENC operations.
There is also one last thing: an internal flag called forceF that allows you to run the permutation before using any one of these internal operations. This is useful when you need to produce something from the Duplex construction: a ciphertext, a random number, a key, etc... Why? Because we want the result to depend on what happened previously, and since we can have many operations per block size we need to do this. You can imagine problems if we were not to do that: an encryption operation that would not depend on the previously inserted key for example.
Let's see some examples!
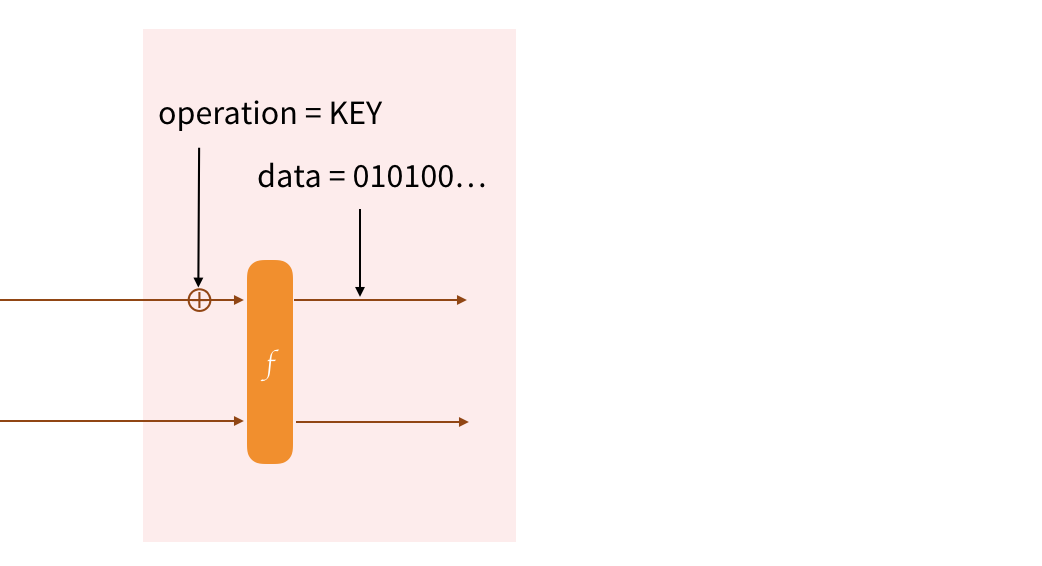
We'll start by keying our protocol. We first absorb the name of the operation (Strobe is verbose). We then permute (via the forceF flag) to start on a fresh block. Since the KEY operation also provides forward-secrecy, the cbefore internal operation is used to replace the bits of the state with the bits of the input (the key).
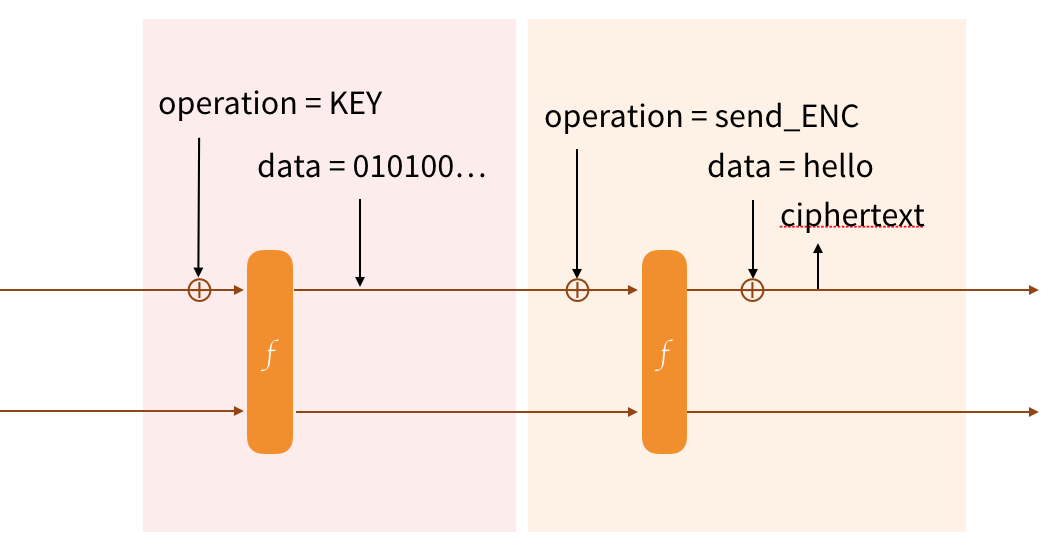
After that we want to encrypt some data. We'll absorb the name of the operation (send_ENC), we'll permute (forceF) and we'll XOR our plaintext with the state to encrypt it. We can then send that ciphertext, which is coincidentally also part of the new state of our duplex construction.
I'll give you two more examples. We can't just send encrypted data like that, we need to protect its integrity. And why not including some additional data that we want to authenticate:
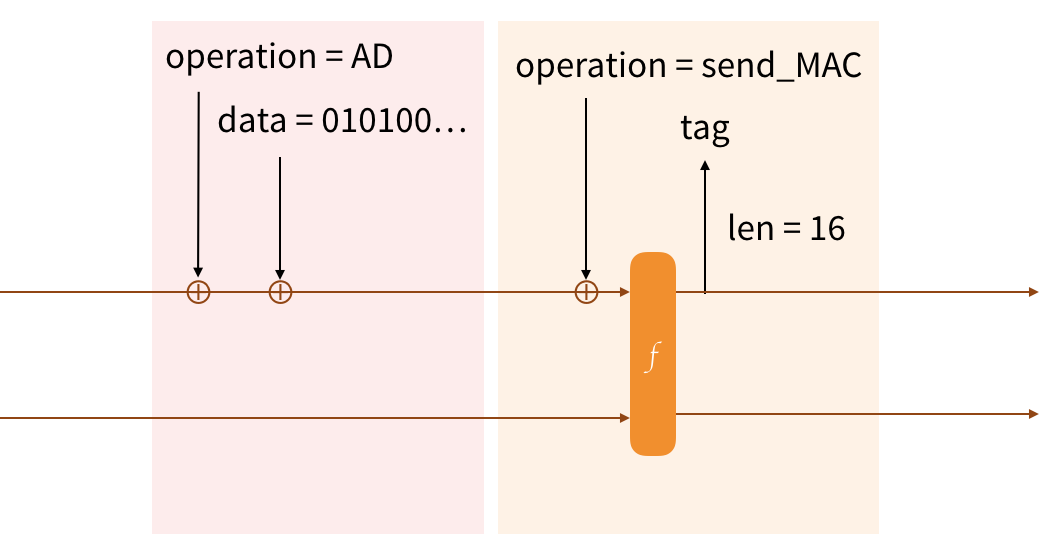
You'll notice, AD does not need to permute the Strobe state, this is because we're not sending anything (or obtaining an output from the construction) so we do not need to depend on what has happened previously yet. For the send_MAC operation we do need that though, and we'll use the cafter internal operation with an input of 16 zeros to obtain the first 16 bytes of the state.
In these description, I've simplified Strobe and omitted the padding. There is also a flag that is differently set depending on who sent the first message. All these details can be learned through the specification.
Now what?
Go play with it! Here is a list of things:
- the specification is here
- the white paper is here
- you can subscribe to the mailing lists here
- Mike Hamburg's talk at Real World Crypto
- the reference C and python implementations
- my readable Go implementation
Note that this is still a beta, and it's still experimental.

Comments
leave a comment...