
SHAKE and SP 800-185 posted December 2017
I've talked about the SHA-3 standard FIPS 202 quite a lot, but haven't talked too much about the second function the standard introduces: SHAKE.

SHAKE is not a hash function, but an Extendable Output Function (or XOF). It behaves like a normal hash function except for the fact that it produces an “infinite” output. So you could decide to generate an output of one million bytes or an output of one byte. Obviously don't do the one byte output thing because it's not really secure. The other particularity of SHAKE is that it uses saner parameters that allow it to achieve the desired targets of 128-bit (for SHAKE128) or 256-bit (for SHAKE256) for security. This makes it a faster alternative than SHA-3 while being a more flexible and versatile function.
SP 800-185
SHAKE is intriguing enough that just a year following the standardization of SHA-3 (2016) another standard is released from the NIST's factory: Special Publication 800-185. Inside of it a new customizable version of SHAKE (named cSHAKE) is defined, the novelty: it takes an additional "customization string" as argument. This string can be anything from an empty string to the name of your protocol, but the slightest change will produce entirely different outputs for the same inputs. This customization string is mostly used as domain separation for the other functions defined in the new document: KMAC, TupleHash and ParallelHash. The rest of this blogpost explains what these new functions are for.
KMAC
Imagine that you want to send a message to your good friend Bob. You do not care about encrypting your message, but to make sure that nobody modifies the message in transit, you hash it with SHA-256 (the variant of SHA-2 with an output length of 256-bit) and append the hash to the message you're sending.
message || SHA-256(message)On the other side, Bob detaches the last 256-bit of the message (the hash), and computes SHA-256 himself on the message. If the obtained result is different from the received hash, Bob will know that someone has modified the message.
Does this work? Is this secure?
Of course not, I hope you know that. A hash function is public, there are no secrets involved, someone who can modify the message can also recompute the hash and replace the original one with the new one.
Alright, so you might think that doing the following might work then:
message || SHA-256(key || message)Both you and Bob now share that symmetric key which should prevent any man-in-the-middle attacker to recompute that hash.
Do you really think this is working?
Nope it doesn't. The reason, not always known, is that SHA-256 (and most variants of SHA-2) are vulnerable to what is called a length extension attack.
You see, unlike the sponge construction that releases just a part of its state as final output, SHA-256 is based on the Merkle–Damgård construction which outputs the entirity of its state as final output. If an attacker observes that hash, and pretends that the absorption of the input hasn't finished, he can continue hashing and obtain the hash of message || more (pretty much, I'm omitting some details like padding). This would allow the attacker to add more stuff to the original message without being detected by Bob:
message || more || SHA-256(key || message || more)Fortunately, every SHA-3 participants (including the SHA-3 winner) were required to be resistant to these kind of attacks. Thus, KMAC is a Message Authentication Code leveraging the resistance of SHA-3 to length-extension attacks. The construction HASH(key || message) is now possible and the simplified idea of KMAC is to perform the following computation:
cSHAKE(custom_string=“KMAC”, input=“key || message”)KMAC also uses a trick to allow pre-computation of the keyed-state: it pads the key up to the block size of cSHAKE. For that reason I would recommend not to come up with your own SHAKE-based MAC construction but to just use KMAC if you need such a function.
TupleHash
TupleHash is a construction allowing you to hash a structure in an non-ambiguous way. In the following example, concatenating together the parts of an RSA public key allows you to obtain a fingerprint.

A malicious attacker could compute a second public key, using the bits of the first one, that would compute to the same fingerprint.
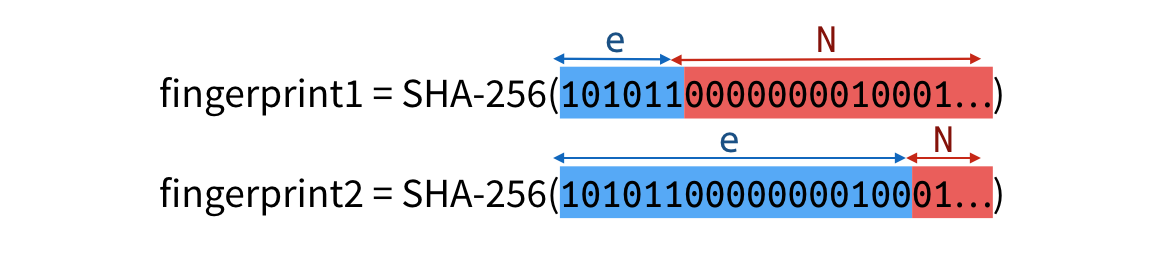
Ways to fix this issue are to include the type and length of each element, or just the length, which is what TupleHash does. Simplified, the idea is to compute:
cSHAKE(custom_string=“TupleHash”,
input=“len_1 || data_1 || len_2 || data_2 || len_3 || data_3 || ..."
)Where len_i is the length of data_i.
ParallelHash
ParallelHash makes use of a tree hashing construction to allow
faster processing of big inputs and large files. The input is first
divided in several chunks of B bytes (where B is an argument of your
choice), each chunk is then separately hashed with
cSHAKE(custom_string=“”, . ) producing as many 256-bit output as
there are chunks. This step can be parallelized with SIMD instructions
or other techniques available on your architecture. Finally each output
is concatenated and hashed a final time with
cSHAKE(custom_string=“ParallelHash”, . ). Again, details have
been omitted.

Comments
leave a comment...