
1/n-1 split to circumvent BEAST posted November 2016
A lot of attacks are theorized only to become practical years or decades later. This was the case with Bleichenbacher's and Vaudenay's padding oracle attacks, but also BEAST.
Realizing that Chosen-plaintext attacks were do-able on TLS -- because browsers would execute untrusted code on demand (javascript) -- a myriad of cryptanalysts decided to knock down on TLS.
POODLE was the first vulnerability that made us deprecate SSL 3.0. It broke the protocol in such a critical way that even a RFC was published about it.
BEAST was the one that made us move away from TLS 1.0. But a lot of embedded devices and products still use these lower versions and it would be unfair not to say that an easy patch can be applied to implementations of TLS 1.0 to counter this vulnerability.
BEAST comes from the fact that in TLS 1.0 the next message being encrypted with CBC will use the previous ciphertext's last block as IV. This makes the IV predictable and allow you to decrypt ciphertexts by sending many chosen plaintexts.
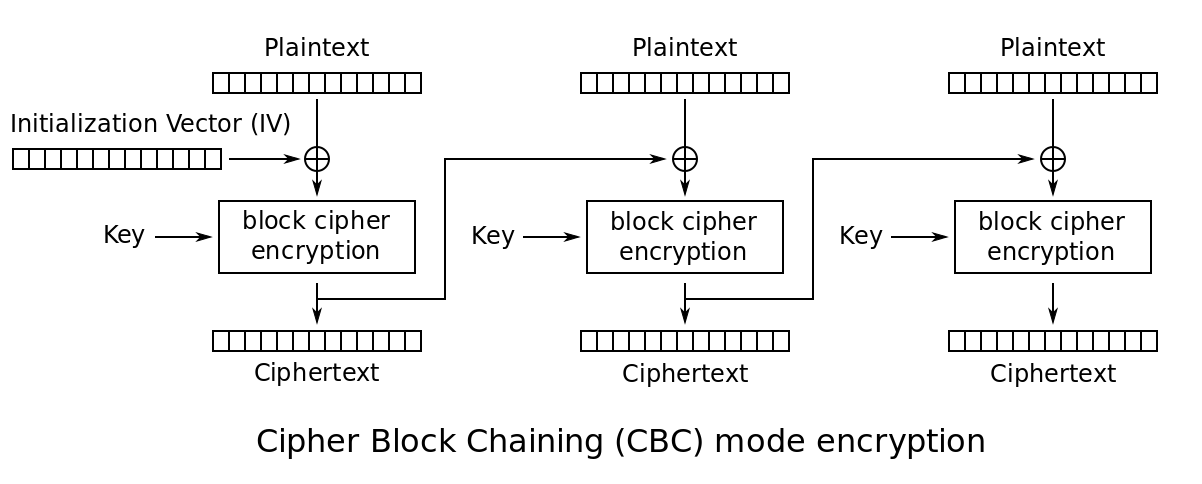
the diagram of CBC for encryption taken from wikipedia. Here imagine that the IV is the previous ciphertext's last block.
The counter measures server-side are well known: move to greater versions of TLS. But if the server cannot fix this, one simple counter measure can be applied on the client-side (remember, this is a client-side vulnerability, it allows a MITM attacker to recover session IDs, cookies, etc...).
Again: BEAST works because the MITM attacker can predict the next IV. He can just observe the previous ciphertext block and craft the plaintext based on it. It's an interactive attack.
One way of preventing this is to send an empty message before sending each message. The empty message will produce a ciphertext (of essentially the MAC), which the attacker will not be able to predict. The message that the attacker asked the browser to encrypt will thus be encrypted with this unpredictable IV. The attacked is circumvented.
This counter measure is called a 0/n split.
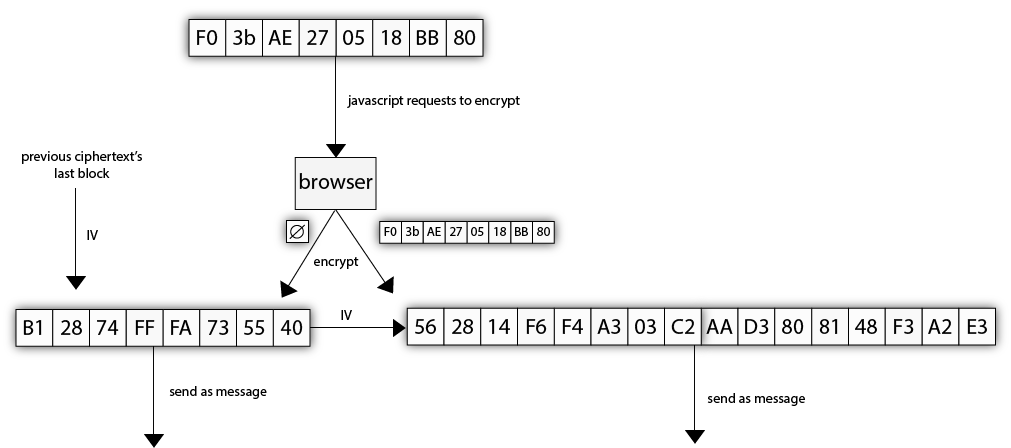
Unfortunately a lot of servers did not like this countermeasures too much. Chrome pushed that first and kind of broke the web for some users. Adam Langley talks about them paying the price for fixing this "too soon". Presumably this "no data" message would be seen by some implementations as a EOF (End Of File value).
One significant drawback of the current proposed countermeasure (sending empty application data packets) is that the empty packet might be rejected by the TLS peer (see comments #30/#50/others: MSIE does not accept empty fragments, Oracle application server (non-JSSE) cannot accept empty fragments, etc.)
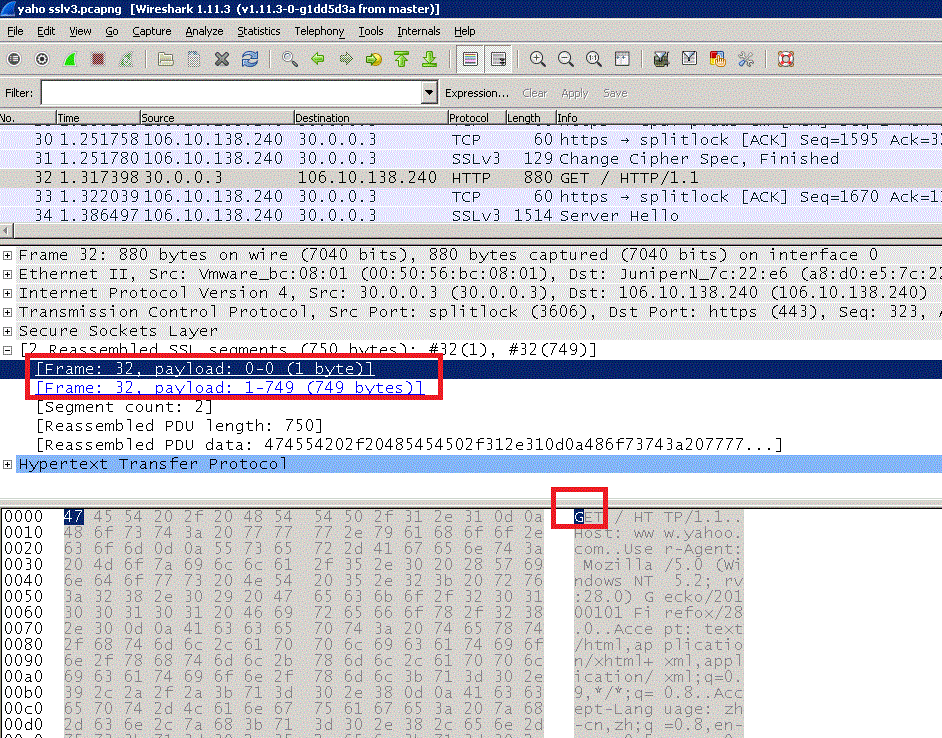
To fix this, Firefox pushed a patch called a 1/n-1 split, where the message to be sent would be split into two messages, the first one containing only 1 byte of the plaintext, and the second one containing the rest.
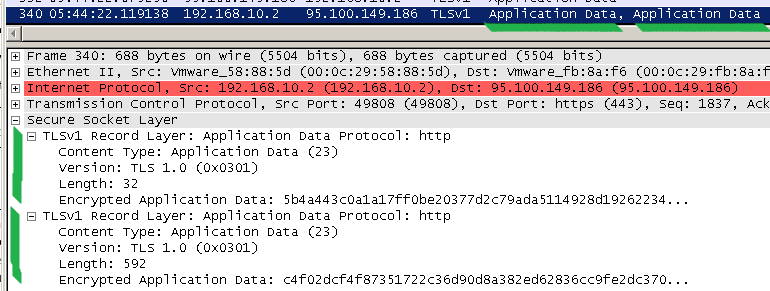
If you look at a fixed client implementation sending messages over a negotiated TLS 1.0 connection, you will see that first it will send the first byte (in the screenshot below, the "G" letter), and then send the rest in a different TLS message.
If you're curious, you can see that being done in code in the recent BearSSL TLS library of Thomas Porning.
static unsigned char *
cbc_encrypt(br_sslrec_out_cbc_context *cc,
int record_type, unsigned version, void *data, size_t *data_len)
{
unsigned char *buf, *rbuf;
size_t len, blen, plen;
unsigned char tmp[13];
br_hmac_context hc;
buf = data;
len = *data_len;
blen = cc->bc.vtable->block_size;
/*
* If using TLS 1.0, with more than one byte of plaintext, and
* the record is application data, then we need to compute
* a "split". We do not perform the split on other record types
* because it turned out that some existing, deployed
* implementations of SSL/TLS do not tolerate the splitting of
* some message types (in particular the Finished message).
*
* If using TLS 1.1+, then there is an explicit IV. We produce
* that IV by adding an extra initial plaintext block, whose
* value is computed with HMAC over the record sequence number.
*/
if (cc->explicit_IV) {
/*
* We use here the fact that all the HMAC variants we
* support can produce at least 16 bytes, while all the
* block ciphers we support have blocks of no more than
* 16 bytes. Thus, we can always truncate the HMAC output
* down to the block size.
*/
br_enc64be(tmp, cc->seq);
br_hmac_init(&hc, &cc->mac, blen);
br_hmac_update(&hc, tmp, 8);
br_hmac_out(&hc, buf - blen);
rbuf = buf - blen - 5;
} else {
if (len > 1 && record_type == BR_SSL_APPLICATION_DATA) {
/*
* To do the split, we use a recursive invocation;
* since we only give one byte to the inner call,
* the recursion stops there.
*
* We need to compute the exact size of the extra
* record, so that the two resulting records end up
* being sequential in RAM.
*
* We use here the fact that cbc_max_plaintext()
* adjusted the start offset to leave room for the
* initial fragment.
*/
size_t xlen;
rbuf = buf - 4 - ((cc->mac_len + blen + 1) & ~(blen - 1));
rbuf[0] = buf[0];
xlen = 1;
rbuf = cbc_encrypt(cc, record_type, version, rbuf, &xlen);
buf ++;
len --;
} else {
rbuf = buf - 5;
}
}
/*
* Compute MAC.
*/
br_enc64be(tmp, cc->seq ++);
tmp[8] = record_type;
br_enc16be(tmp + 9, version);
br_enc16be(tmp + 11, len);
br_hmac_init(&hc, &cc->mac, cc->mac_len);
br_hmac_update(&hc, tmp, 13);
br_hmac_update(&hc, buf, len);
br_hmac_out(&hc, buf + len);
len += cc->mac_len;
/*
* Add padding.
*/
plen = blen - (len & (blen - 1));
memset(buf + len, (unsigned)plen - 1, plen);
len += plen;
/*
* If an explicit IV is used, the corresponding extra block was
* already put in place earlier; we just have to account for it
* here.
*/
if (cc->explicit_IV) {
buf -= blen;
len += blen;
}
/*
* Encrypt the whole thing. If there is an explicit IV, we also
* encrypt it, which is fine (encryption of a uniformly random
* block is still a uniformly random block).
*/
cc->bc.vtable->run(&cc->bc.vtable, cc->iv, buf, len);
/*
* Add the header and return.
*/
buf[-5] = record_type;
br_enc16be(buf - 4, version);
br_enc16be(buf - 2, len);
*data_len = (size_t)((buf + len) - rbuf);
return rbuf;
}Note that this does not protect the very first byte we send. Is this an issue? Not for browsers. But the next time you encounter this in a different setting, think about it.

Comments
Robert Merget
I know this is an old post, but just in case someone else stumbles across this post... The last comment about the protection of the very first byte is actually not true. I am not sure why you would think that it would not be protected, as the attacker cannot choose enough chosen plaintext to perform the attack anymore.
leave a comment...