
SIMD instructions in crypto posted June 2017
The Keccak Code Package repository contains all of the Keccak team's constructions, including for example SHA-3, SHAKE, cSHAKE, ParallelHash, TupleHash, KMAC, Keyak, Ketje and KangarooTwelve. ParallelHash and KangarooTwelve are two hash functions based on the same basis of SHA-3, but that can be sped up with parallelization. This makes these two hash functions really interesting, especially when hashing big files.
MMX, SSE, SSE2, AVX, AVX2, AVX-512
To support parallelization, a common way is to use SIMD instructions, a set of instructions generally available on any modern 64-bit architecture that allows computation on large blocks of data (64, 128, 256 or 512 bits). Using them to operate in blocks of data is what we often call vector/array programming, the compiler will sometimes optimize your code by automatically using these large SIMD registers.
SIMD instructions have been here since the 70s, and have become really common. This is one of the reason why image, sound, video and games all work so well nowadays. Generally, if you're on a 64-bit architecture your CPU will support SIMD instructions.
There are several versions of these instructions. On Intel's side these are called MMX, SSE and AVX instructions. AMD has SSE and AVX instructions as well. On ARM these are called NEON instructions.
MMX allows you to operate on 64-bit registers at once (called MM registers). SSE, SSE2, SSE3 and SSE4 all allow you to use 128-bit registers (XMM registers). AVX and AVX2 introduced 256-bit registers (YMM registers) and the more recent AVX-512 supports 512-bit registers (ZMM registers).
How To Compile?
OK, looking back at the Keccak Code Package, I need to choose what architecture to compile my Keccak code with to take advantage of the parallelization. I have a macbook pro, but have no idea what kind version of SSE or AVX my CPU model supports. One way to find out is to use www.everymac.com → I have an Intel CPU Broadwell which seems to support AVX2!
Looking at the list of architectures supported by the Keccak Code Package I see Haswell, which is of the same family and supports AVX2 as well. Compiling with it, I can run my KangarooTwelve code with AVX2 support, which parallelizes four runs of the Keccak permutation at the same time using these 256-bit registers!
In more details, the Keccak permutation goes through several rounds (12 for KangarooTwelve, 24 for ParallelHash) that need to serially operate on a succession of 64-bit lanes. AVX (no need for AVX2) 256-bit's registers allow four 64-bit lanes to be operated on at the same time. That's effectively four Keccak permutations running in parallel.
Intrisic Instructions
Intrisic functions are functions you can use directly in code, and that are later recognized and handled by the compiler.
Intel has an awesome guide on these here. You just need to find out which function to use, which is pretty straight forward looking at the documentation.
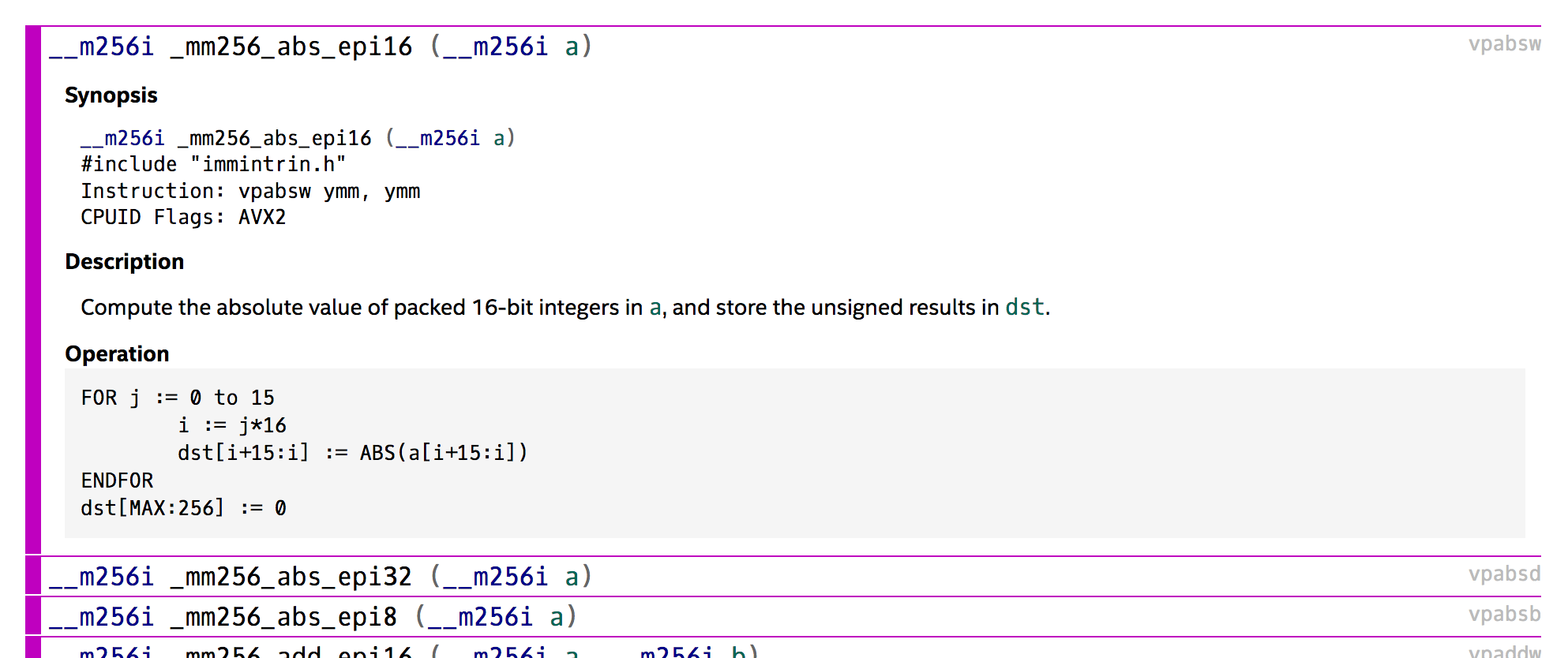
In C, if you're compiling with GCC on an Intel/AMD architecture you can start using intrisic functions for SIMD by including x86intrin.h. Or you can use this script to include the correct file for different combination of compilers and architectures:
#if defined(_MSC_VER)
/* Microsoft C/C++-compatible compiler */
#include <intrin.h>
#elif defined(__GNUC__) && (defined(__x86_64__) || defined(__i386__))
/* GCC-compatible compiler, targeting x86/x86-64 */
#include <x86intrin.h>
#elif defined(__GNUC__) && defined(__ARM_NEON__)
/* GCC-compatible compiler, targeting ARM with NEON */
#include <arm_neon.h>
#elif defined(__GNUC__) && defined(__IWMMXT__)
/* GCC-compatible compiler, targeting ARM with WMMX */
#include <mmintrin.h>
#elif (defined(__GNUC__) || defined(__xlC__)) && (defined(__VEC__) || defined(__ALTIVEC__))
/* XLC or GCC-compatible compiler, targeting PowerPC with VMX/VSX */
#include <altivec.h>
#elif defined(__GNUC__) && defined(__SPE__)
/* GCC-compatible compiler, targeting PowerPC with SPE */
#include <spe.h>
#endifIf we look at the reference implementation of KangarooTwelve in C we can see how they decided to use the AVX2 instructions. They first define a __m256i variable which will hold 4 lanes at the same time.
typedef __m256i V256;They then declare a bunch of them. Some of them will be used as temporary registers.
They then use unrolling to write the 12 rounds of Keccak. Which are defined via relevant AVX2 instructions:
#define ANDnu256(a, b) _mm256_andnot_si256(a, b)
#define CONST256(a) _mm256_load_si256((const V256 *)&(a))
#define CONST256_64(a) (V256)_mm256_broadcast_sd((const double*)(&a))
#define LOAD256(a) _mm256_load_si256((const V256 *)&(a))
#define LOAD256u(a) _mm256_loadu_si256((const V256 *)&(a))
#define LOAD4_64(a, b, c, d) _mm256_set_epi64x((UINT64)(a), (UINT64)(b), (UINT64)(c), (UINT64)(d))
#define ROL64in256(d, a, o) d = _mm256_or_si256(_mm256_slli_epi64(a, o), _mm256_srli_epi64(a, 64-(o)))
#define ROL64in256_8(d, a) d = _mm256_shuffle_epi8(a, CONST256(rho8))
#define ROL64in256_56(d, a) d = _mm256_shuffle_epi8(a, CONST256(rho56))
#define STORE256(a, b) _mm256_store_si256((V256 *)&(a), b)
#define STORE256u(a, b) _mm256_storeu_si256((V256 *)&(a), b)
#define STORE2_128(ah, al, v) _mm256_storeu2_m128d((V128*)&(ah), (V128*)&(al), v)
#define XOR256(a, b) _mm256_xor_si256(a, b)
#define XOReq256(a, b) a = _mm256_xor_si256(a, b)
#define UNPACKL( a, b ) _mm256_unpacklo_epi64((a), (b))
#define UNPACKH( a, b ) _mm256_unpackhi_epi64((a), (b))
#define PERM128( a, b, c ) (V256)_mm256_permute2f128_ps((__m256)(a), (__m256)(b), c)
#define SHUFFLE64( a, b, c ) (V256)_mm256_shuffle_pd((__m256d)(a), (__m256d)(b), c)And if you're wondering how each of these _mm256 function is used, you can check the same Intel documentation
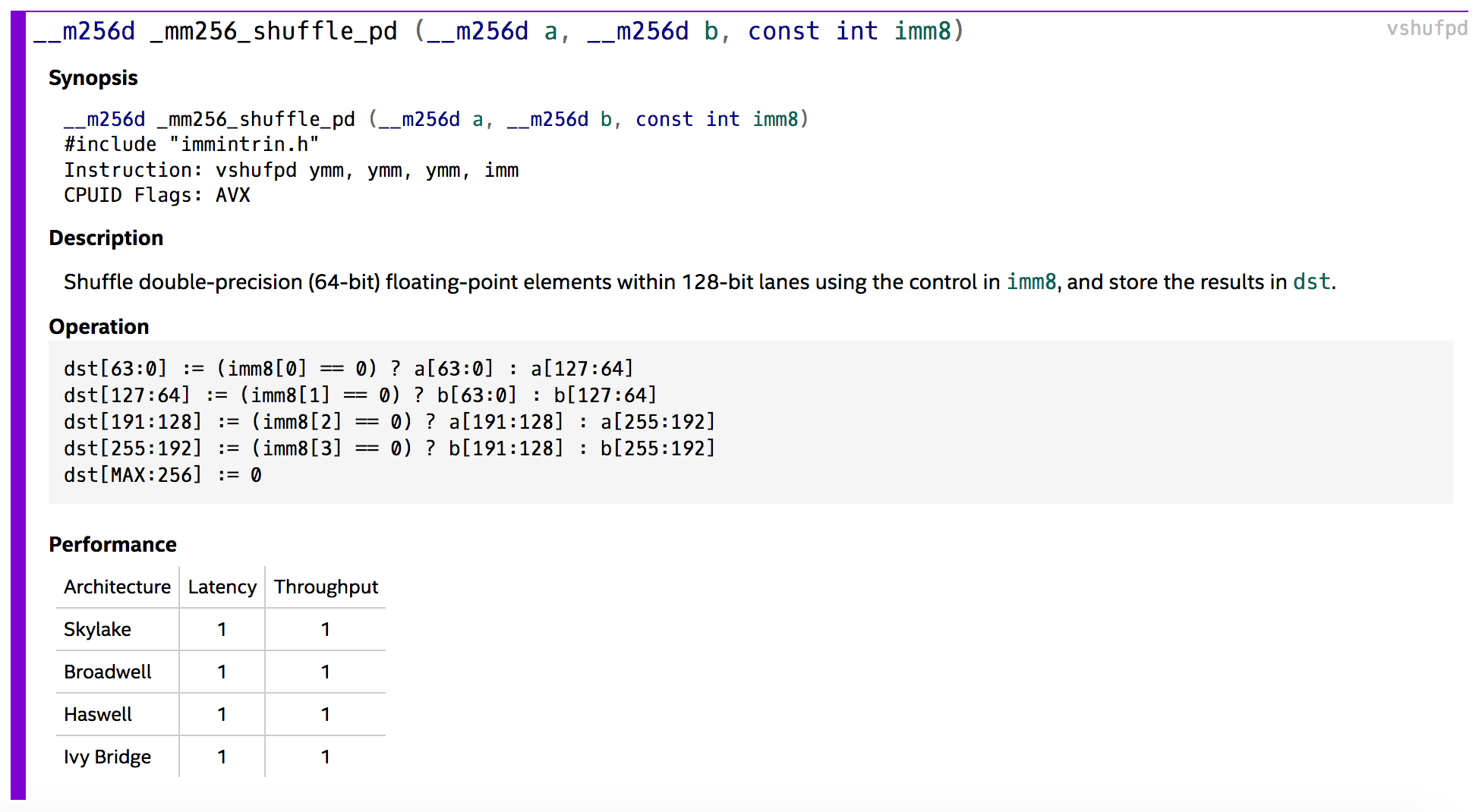
Voila!

Comments
leave a comment...