I’m giving a talk about smart contract security at the IT Camp conference of Cluj Napoca, Romania on Thursday. If anyone is there and wants to talk about crypto while drinking beer, contact me!
suggested reads:
cryptography, security, and random thoughts
Hey! I'm David, cofounder of zkSecurity, advisor at Archetype, and author of the Real-World Cryptography book. I was previously a cryptography architect of Mina at O(1) Labs, the security lead for Libra/Diem at Facebook, and a security engineer at the Cryptography Services of NCC Group. Welcome to my blog about cryptography, security, and other related topics.
I’m giving a talk about smart contract security at the IT Camp conference of Cluj Napoca, Romania on Thursday. If anyone is there and wants to talk about crypto while drinking beer, contact me!
Last month I was in Singapore with Mason to talk about vulnerabilities in Ethereum smart contracts at Black Hat Asia. As part of the talk we released the DASP, a top 10 of the most damaging or surprising security vulnerabilities that we have observed in the wild or in private during audits we perform as part of our jobs.
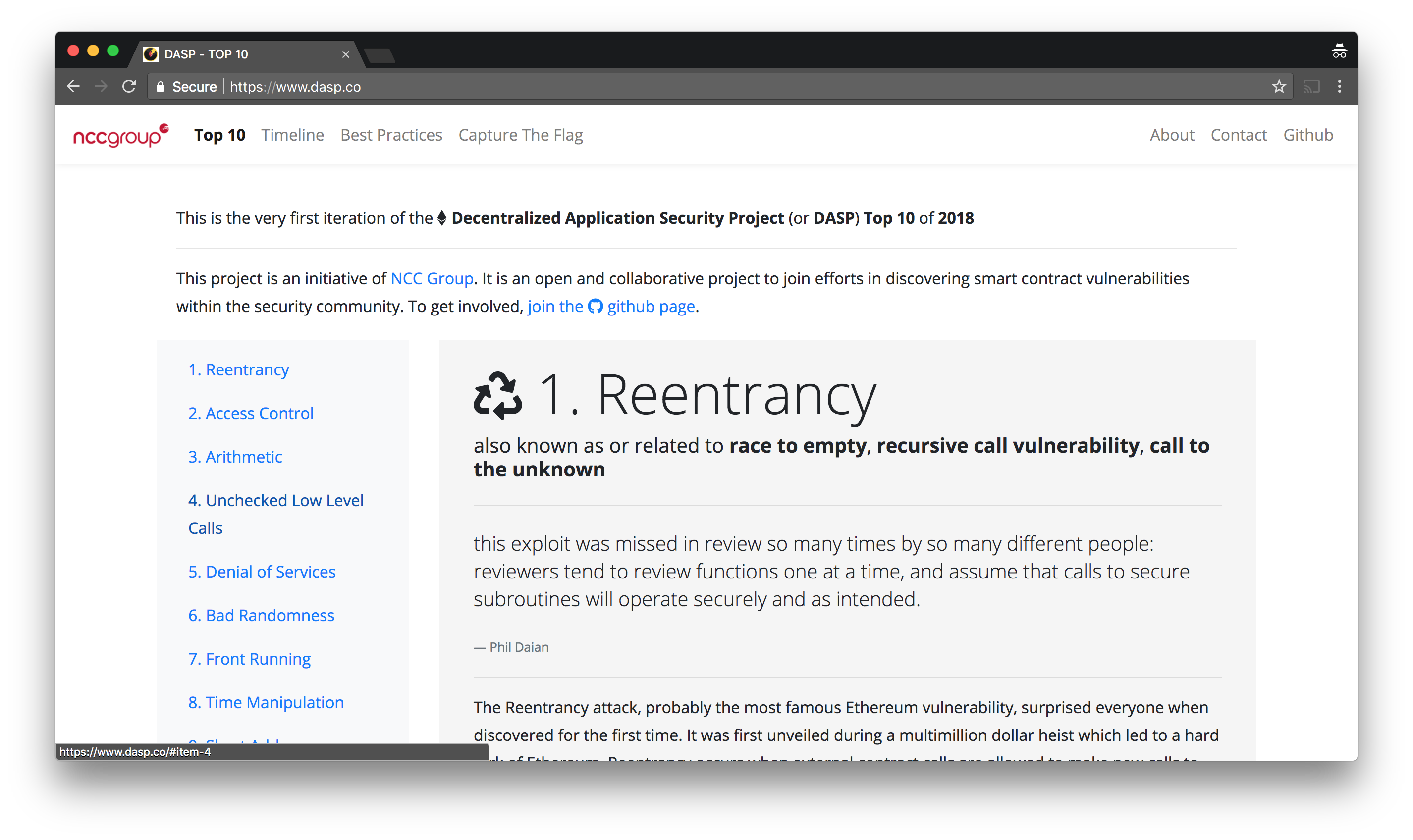
The page is on github as well and we welcome contributions to the top 10 and the list of known exploits. In addition we’re looking to host more projects related to the Ethereum space there, if you are looking for research projects or are looking to contribute on tools or anything that can make smart contracts development more secure, file an issue on github!
Note that I will be giving the talk again at IT Camp in Cluj-Napoca in a few months.
I gave a talk at Black Hat Europe last year and the recording has finally been uploaded.
I gave a summary of the talk here. You can also directly check out the specification of Disco or the libdisco library on www.discocrypto.com.
I’ll be giving a talk at Black Hat Asia with Mason in a few months, and thus I was given two tickets for students to come attend the conference for free.
Anyone interested?
EDIT: these have been given away.
Paul Rösler and Christian Mainka and Jörg Schwenk released More is Less: On the End-to-End Security of Group Chats in Signal, WhatsApp, and Threema in July 2017.
Today Paul Rösler came to Real World Crypto to talk about the results, which is a good thing.
Interestingly, in the middle of the talk Wired released a worrying article untitled WhatsApp Security Flaws Could Allow Snoops to Slide Into Group Chats.
Interestingly as well, at some point during the day Matthew Green also wrote about it in Attack of the Week: Group Messaging in WhatsApp and Signal.
They make it seem really worrisome, but should we really be scared about the findings?
Traceable delivery is the first thing that came up in the presentation. What is it? It’s the check marks that appear when your recipient receives a message you sent. It’s mostly a UI feature but the fact that no security is tied to it allows a server to fake them while dropping messages, making you think that your recipient has wrongly received the message. This was never a security feature to begin with, and nobody never claimed it was one.
Closeness is the fact that the WhatsApp servers can add a new participant into your private group chat without your consent (assuming you’re the admin). This could lead people to share messages to the group including to a rogue participant. The caveat is that:
previous messages cannot be decrypted by the newcomer because a new key is generated when someone new joins the mix
everybody is receiving a notification that somebody joined, at this point everyone can choose to willingly send messages to the group
Again, I do not see this as a security vulnerability. Maybe because I’ve understood how group chats can work (or miswork) from growing up with shady websites and applications. But I see this more as a UI/UX problem.
The paper is not bad though, and I think they’re right to point out these issues. Actually, they do something very interesting in it, they start it up with a nice security model that they use to analyse several messaging applications:
Intuitively, a secure group communication protocol should provide a level of security comparable to when a group of people communicates in an isolated room: everyone in the room hears the communication (traceable delivery), everyone knows who spoke (authenticity) and how often words have been said (no duplication), nobody outside the room can either speak into the room (no creation) or hear the communication inside (confidentiality), and the door to the room is only opened for invited persons (closeness).
Following this security model, you could rightfully think that we haven’t reached the best state in secure messaging. But the fuss about it could also wrongfully make you think that these are worrisome attacks that need to be dealt with.
The facts are here though, this paper has been blown out of proportion. Moxie (one of the creator of Signal) reacts on hackernews:
To me, this article reads as a better example of the problems with the security industry and the way security research is done today, because I think the lesson to anyone watching is clear: don’t build security into your products, because that makes you a target for researchers, even if you make the right decisions, and regardless of whether their research is practically important or not.
I’d say the problem is in the reaction, not in the published analysis. But it’s a sad reaction indeed.
Good night.
Early in 2016, I published a whitepaper (here on eprint) on how to backdoor the Diffie-Hellman key agreement algorithm. Inside the whitepaper, I discussed three different ways to construct such a backdoor; two of these were considered nobody-but-us (NOBUS) backdoors.
A NOBUS backdoor is a backdoor accessible only to those who have the knowledge of some secret (a number, a passphrase, …). Making a NOBUS backdoor irreversible without the knowledge of the secret.
In October 2016, Dorey et al. from Western University (Canada) published a white paper called Indiscreet Logs: Persistent Diffie-Hellman Backdoors in TLS. The research pointed out that one of my NOBUS construction was reversible, while the other NOBUS construction was more dangerous than expected.
I wrote this blogpost resuming their discoveries a long time ago, but never took the time to publish it here. In the rest of this post, I’ll expect you to have an understanding of the two NOBUS backdoors introduced in my paper. You can find a summary of the ideas here as well.
For those who have attended my talk at Defcon, Toorcon or a meetup; I should assure you that I did not talk about the first (now-known reversible) NOBUS construction. It was left out of the story because it was not such a nice backdoor in the first place. Its security margins were weaker (at the time) compared to the second construction, and it was also harder to implement.
The attack Dorey et al. wrote about comes from a 2005 white paper, where Coron et al. published an attack on a construction based on Diffie-Hellman. But before I can tell you about the attack, I need to refresh your memory on how the baby-step giant-step (BSGS) algorithm works.
Imagine that a generator \(g\) generates a group \(G\) in \(\mathbb{Z}_p\), and that we want to find the order of that group \(|G| = p_1\).
Now what we could do if we have a good idea of the size of that order \(p_1\), is to split that length in two right in the middle: \(p_1 = a + b \cdot 2^{\lceil \frac{l}{2} \rceil}\), where \( l \) is the bitlength of \(p_1\).
This allows us to write two different lists:
Now imagine that you compute these two lists, and that you then stumble upon a collision between elements from these two sets. This would entail that for some \(i\) and \(j\) you have:
We found \(p_1\) in time quasi-linear (via sorting, searching trees, etc…) in \(\sqrt{p_1}\)!
Now let’s review our first NOBUS construction, detailed in section 4 of my paper.

Here \(p - 1 = 2 p_1 p_2 \) with \( p_1 \) our small-enough subgroup generated by \(g\) in \(\mathbb{Z}_p\), and \(p_2\) our big-enough subgroup that makes the factorization of our modulus near-impossible. The factor \(q\) is generated in the same way.
At this point, we could try to reverse the construction using BSGS by creating these two lists and hopping for a collision:
Unfortunately, remember that \(p\) is hidden inside of \( n = p q \). We have no knowledge of that factor. Instead, we could calculate these two lists:
And this time, we can test for a collision between two elements of these lists “mod \(p\)” via the \(gcd\) function:
Hopefully this will yield \(p\), one of the factor of \(n\). If you do not understand why, it works because if \(g^i\) and \(g^{-j \cdot 2^{\lceil \frac{l}{2} \rceil}}\) collide “mod \(p\)”, then we have:
Since we also know that \( p | n \), it results that the \(gcd\) of the two returns our hidden \(p\)!
Unfortunately at this point, the persnickety reader will have noticed that this cannot be done in the same complexity as the original BSGS attack. Indeed, we need to compute the \(gcd\) for all pairs and this increases our complexity to \(\mathcal{O}(p_1)\), the same complexity as the attack I pointed out in my paper.
Now here is the that trick Coron et al. found out. They could optimize calls to \(gcd\) down to \(\mathcal{O}(\sqrt{p_1})\), which would make the reversing as easy as using the backdoor. The trick is as follow:
It’s pretty easy to see that the \(gcd\) will still yield a factor, as before. Except that this time we only need to call it at most \(2^{\lceil \frac{l}{2} \rceil}\) times, which is \(\approx \sqrt{p_1}\) times by definition.
The second NOBUS backdoor construction received a different treatment. If you do not know how this backdoor works I urge you to first watch my talk on the subject.
Let’s ask ourselves the question: what happens if the client and the server do not negotiate an ephemeral Diffie-Hellman key exchange, and instead use RSA or Elliptic Curve Diffie-Hellman to perform the key exchange?
This could be because the client did not list a DHE (ephemeral
Diffie-Hellman) cipher suite in priority, or because the server decided
to pick a different kind of key agreement algorithm.
If this is the case, we would observe an exchange that we could not spy on or tamper with via our DHE backdoor.
Dorey et al. discovered that an active man-in-the-middle could
change that by tampering with the original client’s ClientHello
message to single-out a DHE cipher suite (removing the rest of the
non-DHE cipher suites) and forcing the key exchange to happen by way
of the Diffie-Hellman algorithm.
This works because there are no countermeasures in TLS 1.2 (or prior) to prevent this to happen.
My original white paper has been updated to reflect Dorey et al.’s developments while minimally changing its structure (to retain chronology of the discoveries). You can obtain it here.
Furthermore, let me mention that the new version of TLS —TLS 1.3— will fix all of these issues in two ways:
ClientHello message as the client can verify the signature and
make sure that no active man-in-the-middle has tampered with the
handshake.Hello hello,
Merry christmas and happy new year. We’re done for the year and so it is time for me to write this blog post (I did the same last year by the way).
I’ll copy verbatim what I wrote last year about what makes a good blog post:
Without further adue, here is the list!
building lattice reduction (LLL) intuition from Kelby Ludwig is a must read if you want to understand how lattices and lattice reductions work. By the way, this post is the perfect example of a blogpost that fits all my criteria of a good blog post. Make sure to check Kelby’s blog post of last year as well.
Introducing Miscreant: a multi-language misuse resistant encryption library from Tony Arcieri is the perfect introduction to key wrapping and SIV modes. AES-GCM-SIV from Adam Langley is a good addition.
How I implemented my own crypto is a trip report from Loup Vaillant about implementing his own cryptographic library.
Why TLS 1.3 isn’t in browsers yet by Nick Sullivan is a good summary of the mess that TLS 1.3 is (specifically because it needs to support so many legacy versions). For more lolz, make sure to read Matthew Green’s The strange story of “Extended Random”.
Cloudflare has a lot more good blogposts: Privacy Pass - “The Math” from Alex Davidson goes through the math of one of the most crypto-y feature ever seen from a “normal” company, SIDH in Go for quantum-resistant TLS 1.3 by Henry de Valence does the same for the SIDH post-quantum key exchange. (A good addition to this is SIDH a quantum resistant algorithm for DH exchange by Shevek).
HTTPS on Stack Overflow: The End of a Long Road is a huge post from Nick Craver going into depth about the troubles of migrating towards HTTPS for large infrastructures. In addition, be sure to check Jan Schaumann’s work on doing the same thing for yahoo: The Razor’s Edge - Cutting Your TLS Baggage.
SSL Certificate Exchange from Joshua Davies is a really useful walkthrough of a TLS certificate. If you don’t know much about TLS certificates and need to know more, it’s a really good read.
Is SHA-3 slow?, Keccak: open-source cryptography and Why Keccak is not ARX . The Keccak team made an excellent job this year of talking (and debunking critics) about the new SHA-3 hash function. You can learn about the different concepts surrounding SHA-3 through these posts.
Why Replace SHA-1 with BLAKE2? on the other hand, written by JP Aumasson, tells you to replace your SHA-1 instances with his hash function BLAKE2. JP writes a lot of very good blog post, so check this one on Should Curve25519 keys be validated? (that launched the debate on Curve25519 key validation) or the ones on his submission to NIST’s PQ crypto not-a-competition thingy: Improving the SPHINCS post-quantum signature scheme, part 1.
Cryptographic vulnerabilities in IOTA by Neha Narula and the follow up Our response to “A Cryptocurrency Without a Blockchain Has Been Built to Outperform Bitcoin” by Joi Ito (both from the Digital Currency medialab of MIT) because it shows you how hilariously bad some cryptocurrencies are (interestingly IOTA reached and lost to 4th place (in terms of market cap) in the cryptocurrency world a few months ago).
Confidential Transactions from Basic Principles from Michael Rosenberg is a pedogagical intro to ring signatures, range proofs and other cryptographic concepts. This is useful to dig into especially if you’re keen on anonimity inside of cryptocurrencies. For an exploit of these, be sure to check Exploiting Low Order Generators in One-Time Ring Signatures from Jonas Nick.
What are zk-SNARKs?. Zcash has a series of articles about its underlying technology (anonimity inside of a cryptocurrency), it seems well written (like a lot of things on their website).
Survey of Discrete Log Algorithms is a good intro to the discrete logarithm problem.
Walking through an F* proof by Santiago Zanella-Beguelin seems like a good way to get yourself into F*.
That’s it!
Have I missed something? Please tell me in the comments.
If you want more links like these, be sure to subscribe to my link section here on this website.
See you in 2018!
I’ve talked about the SHA-3 standard FIPS 202 quite a lot, but haven’t talked too much about the second function the standard introduces: SHAKE.

SHAKE is not a hash function, but an Extendable Output Function (or XOF). It behaves like a normal hash function except for the fact that it produces an “infinite” output. So you could decide to generate an output of one million bytes or an output of one byte. Obviously don’t do the one byte output thing because it’s not really secure. The other particularity of SHAKE is that it uses saner parameters that allow it to achieve the desired targets of 128-bit (for SHAKE128) or 256-bit (for SHAKE256) for security. This makes it a faster alternative than SHA-3 while being a more flexible and versatile function.
SHAKE is intriguing enough that just a year following the standardization of SHA-3 (2016) another standard is released from the NIST’s factory: Special Publication 800-185. Inside of it a new customizable version of SHAKE (named cSHAKE) is defined, the novelty: it takes an additional “customization string” as argument. This string can be anything from an empty string to the name of your protocol, but the slightest change will produce entirely different outputs for the same inputs. This customization string is mostly used as domain separation for the other functions defined in the new document: KMAC, TupleHash and ParallelHash. The rest of this blogpost explains what these new functions are for.
Imagine that you want to send a message to your good friend Bob. You do not care about encrypting your message, but to make sure that nobody modifies the message in transit, you hash it with SHA-256 (the variant of SHA-2 with an output length of 256-bit) and append the hash to the message you’re sending.
message || SHA-256(message)
On the other side, Bob detaches the last 256-bit of the message (the hash), and computes SHA-256 himself on the message. If the obtained result is different from the received hash, Bob will know that someone has modified the message.
Does this work? Is this secure?
Of course not, I hope you know that. A hash function is public, there are no secrets involved, someone who can modify the message can also recompute the hash and replace the original one with the new one.
Alright, so you might think that doing the following might work then:
message || SHA-256(key || message)
Both you and Bob now share that symmetric key which should prevent any man-in-the-middle attacker to recompute that hash.
Do you really think this is working?
Nope it doesn’t. The reason, not always known, is that SHA-256 (and most variants of SHA-2) are vulnerable to what is called a length extension attack.
You see, unlike the sponge construction that releases just a part of its state as final output, SHA-256 is based on the Merkle–Damgård construction which outputs the entirity of its state as final output. If an attacker observes that hash, and pretends that the absorption of the input hasn’t finished, he can continue hashing and obtain the hash of message || more (pretty much, I’m omitting some details like padding). This would allow the attacker to add more stuff to the original message without being detected by Bob:
message || more || SHA-256(key || message || more)
Fortunately, every SHA-3 participants (including the SHA-3 winner) were required to be resistant to these kind of attacks. Thus, KMAC is a Message Authentication Code leveraging the resistance of SHA-3 to length-extension attacks. The construction HASH(key || message) is now possible and the simplified idea of KMAC is to perform the following computation:
cSHAKE(custom_string=“KMAC”, input=“key || message”)
KMAC also uses a trick to allow pre-computation of the keyed-state: it pads the key up to the block size of cSHAKE. For that reason I would recommend not to come up with your own SHAKE-based MAC construction but to just use KMAC if you need such a function.
TupleHash is a construction allowing you to hash a structure in an non-ambiguous way. In the following example, concatenating together the parts of an RSA public key allows you to obtain a fingerprint.

A malicious attacker could compute a second public key, using the bits of the first one, that would compute to the same fingerprint.
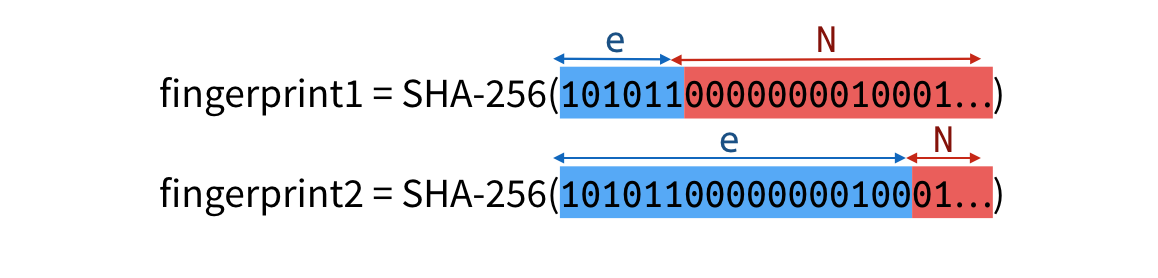
Ways to fix this issue are to include the type and length of each element, or just the length, which is what TupleHash does. Simplified, the idea is to compute:
cSHAKE(custom_string=“TupleHash”,
input=“len_1 || data_1 || len_2 || data_2 || len_3 || data_3 || ..."
)
Where len_i is the length of data_i.
ParallelHash makes use of a tree hashing construction to allow
faster processing of big inputs and large files. The input is first
divided in several chunks of B bytes (where B is an argument of your
choice), each chunk is then separately hashed with
cSHAKE(custom_string=“”, . ) producing as many 256-bit output as
there are chunks. This step can be parallelized with SIMD instructions
or other techniques available on your architecture. Finally each output
is concatenated and hashed a final time with
cSHAKE(custom_string=“ParallelHash”, . ). Again, details have
been omitted.
Real World Crypto, the best crypto/security conference, will start next January in Zurich. It is about to sell out so grab a ticket quickly!
Register for @RealWorldCrypto 2018 soon or be disappointed. We are reaching our capacity.
— Nigel Smart (@SmartCryptology) December 11, 2017
You might think it’s too crypto-y for you, or not real-world enough. Think again. I’m not the only one who think this conference is awesome.
I will be at RWC. ‘nuff said.
— Thomas Pornin (@BearSSLnews) December 11, 2017
My favorite conference of the year, Real World Crypto, is coming up, and it’s in Zurich!
— Filippo Valsorda (@FiloSottile) December 10, 2017
If you (broadly speaking) study crypto and wouldn’t attend because money, DM me something you made (a cryptopals solution, blog post, uni assignment…) and I’ll pay your registration.
I met the Tor team and started the design that would become PrivacyPass at @RealWorldCrypto in 2016 https://t.co/dkijEvmh8M https://t.co/MBPvD11mns
— George Tankersley (@gtank__) December 6, 2017
RWC 2018: less rugby, more crypto(graphy). If you don't go, someone else will.
— Santiago Zanella (@xEFFFFFFF) December 11, 2017
I can't make it to RWC2018 so I'll match Filippo's offer. Promise to send me a write-up of the best talk you attended at RWC and I'll pay for your registration. https://t.co/Da8eNuNVUB
— yan (@bcrypt) December 11, 2017
Preference goes to students and underrepresented groups in cryptography. https://t.co/ZWTapi7Pva
Yesterday I gave a talk at Black Hat about my recent research with Disco. (Thanks Bytemare for the picture.)
I’ve introduced both the Strobe protocol framework and the Noise protocol framework in the past. So I won’t go over them again, but I advise you to read these two blog posts before reading this one (if you care about the technical details).
As a recap:
1. The Strobe protocol framework is a framework to build symmetric protocols. It’s all based on the SHA-3 permutation (keccak-f) and the duplex construction. Codebase is tiny (~1000LOC) and it can also be used to build simple cryptographic operations.
2. The Noise protocol framework is a framework to build things like TLS. It’s very simple and flexible, and I believe a good TLS alternative for today.
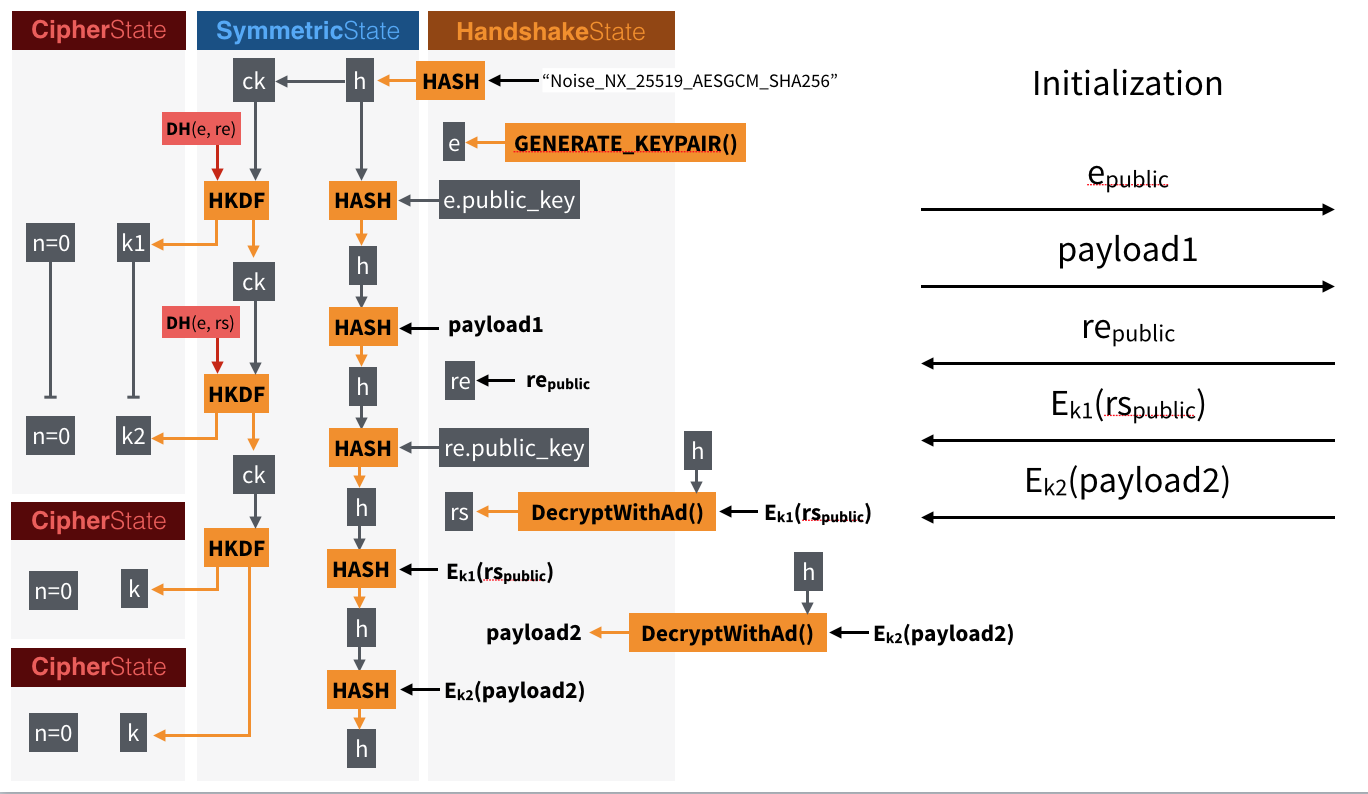
Looking at the previous diagram representing the NX handshake pattern of Noise (where a client is not authenticated and a server sends its long-term static key as part of the handshake) I thought to myself: I can simplify this. For example, you can see:
h value absorbing every messages being sent and received, and being used to authenticate the transcript at some points in the handshake. ck value being used to derive keys from the different key exchanges happening during the handshake.These things can be simplified greatly by using Strobe to get rid of all the symmetric tricks, while at the same time getting rid of all the symmetric primitives in use (AES-GCM, SHA-256, HMAC and HKDF).
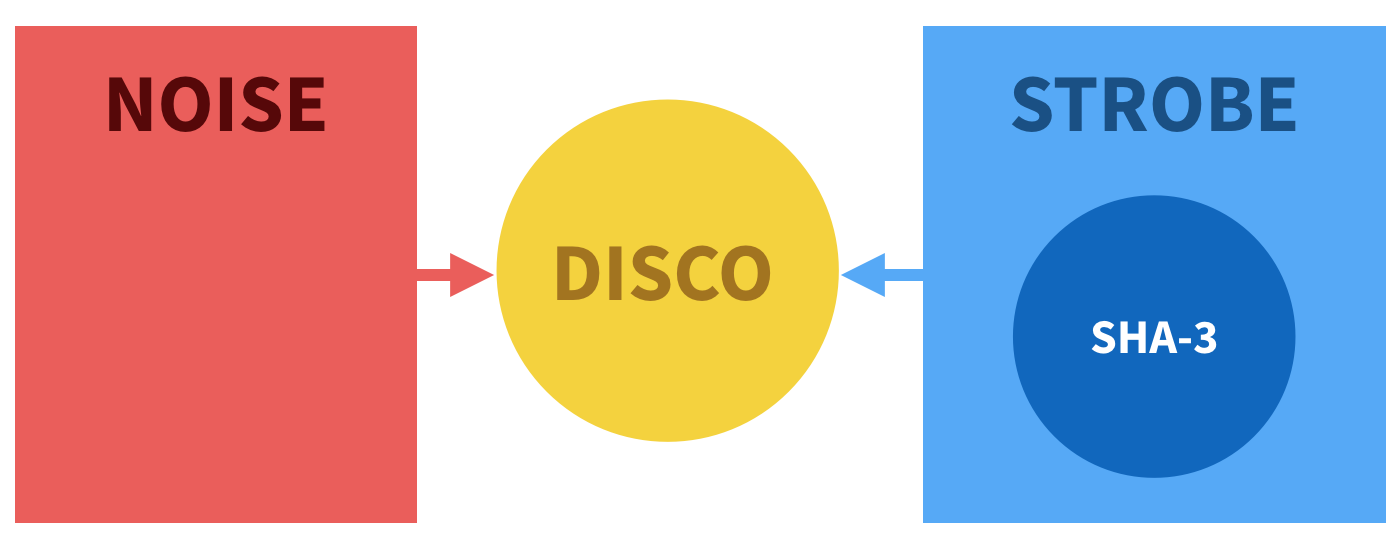
This is exactly how I came up with Disco, merging Noise and Strobe to simplify the former.
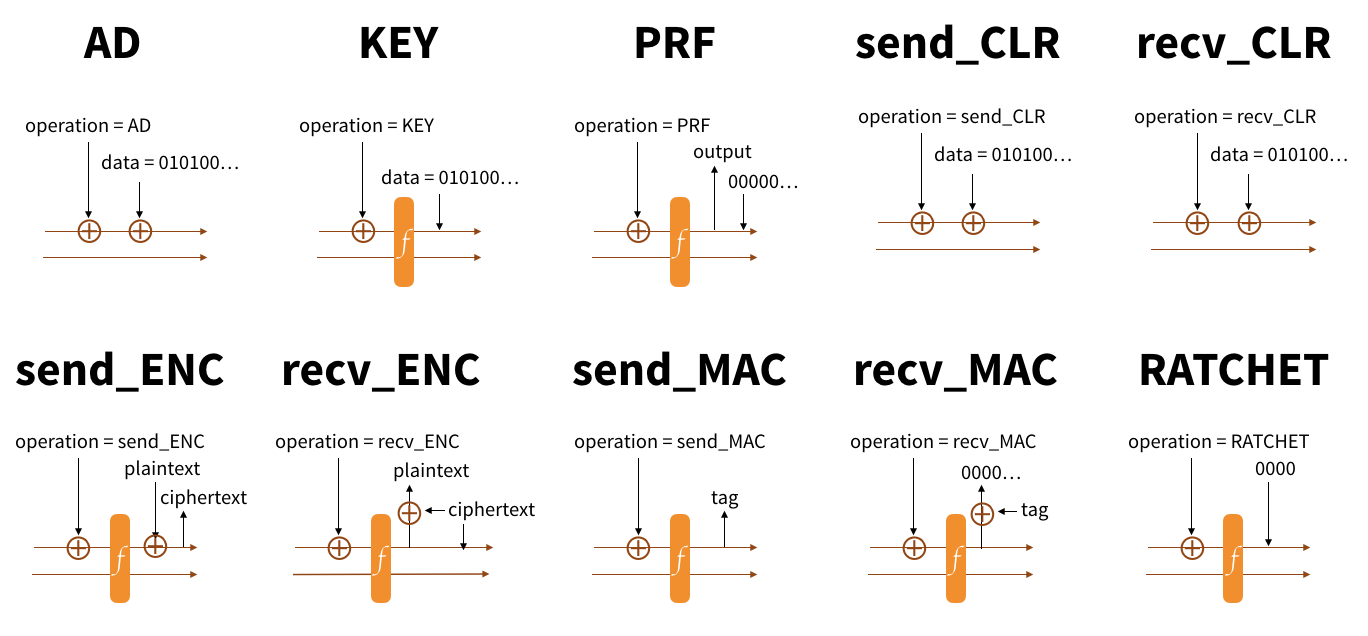
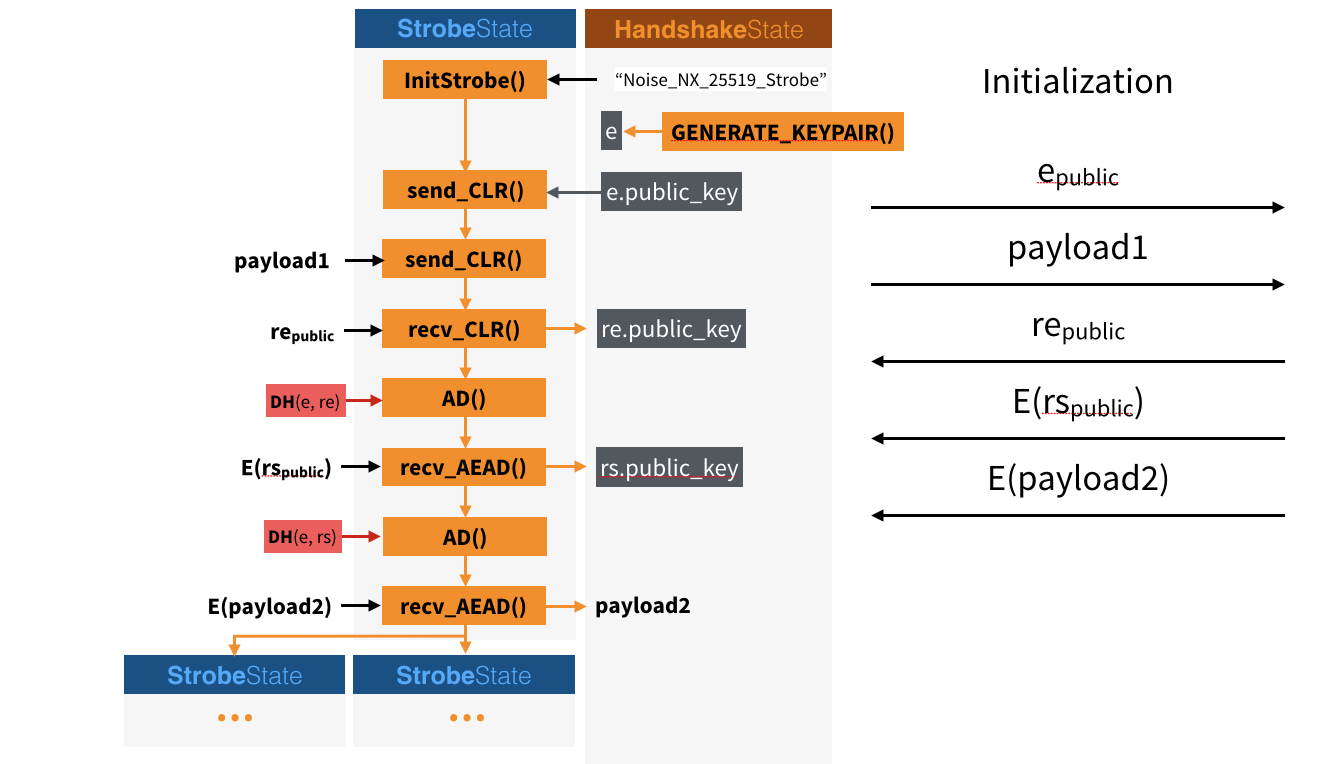
Here is the simplification I made of the previous diagram. We’re using Strobe’s functions like send_CLR, recv_CLR and AD to absorb messages being sent or received as well as the output of the different key exchanges. We’re also using send_AEAD and recv_AEAD to encrypt/decrypt and authenticate the whole transcript up to this point (these functions don’t exist in Strobe, but they are basically send/recv_ENC followed by send/recv_MAC).
You can see that everything looks suddenly much more simple to implement or understand. send_CLR, recv_CLR and AD are all functions that do the same thing: they XOR the input with the rate (public part) of our strobe state. It is so elegant that I made another diagram showing what is really happening in this diagram with Strobe. (Something that I obviously couldn’t have done with AES-GCM, SHA-256, HMAC and HKDF.)
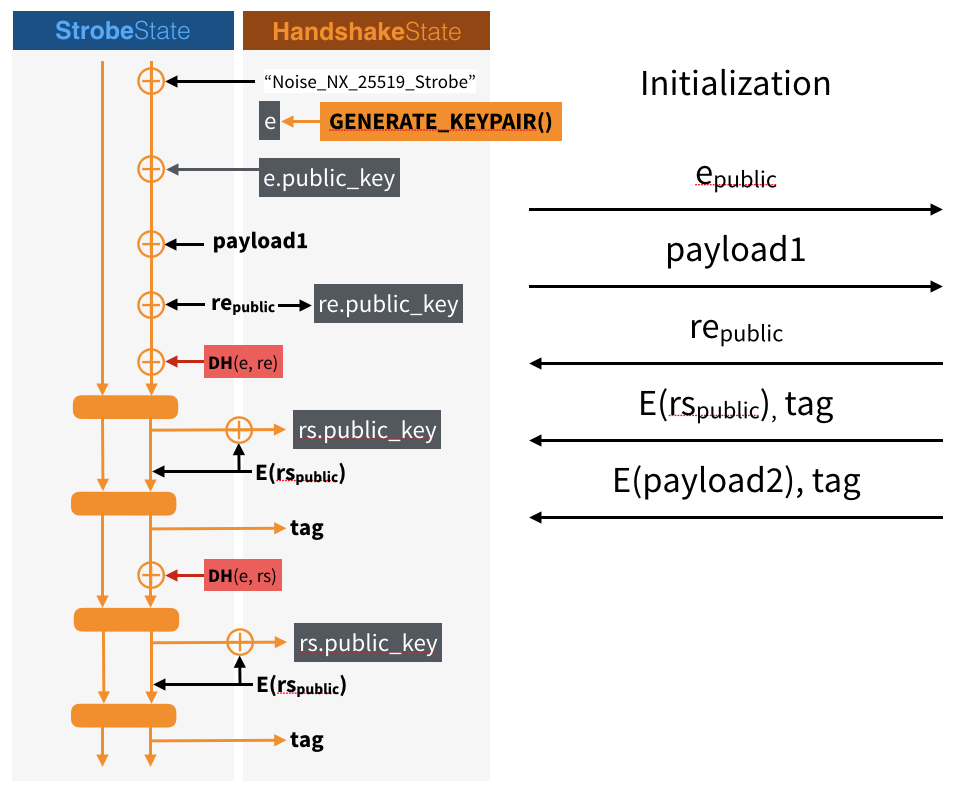
You can see two lines here in the StrobeState. The capacity (secret part) is on the left and the rate (public part) is on the right. Most things get absorbed by just XORing the input with the public part (of course if we reach the end of the public part, we would permute and start on a new block like we do for hashing with the sponge construction).
When we send or receive encrypted data, we also need to do a little dance and first permute the state to produce something based on all of the data we’ve previously absorbed (including outputs of diffie-hellman key exchanges). This output is random enough to allow us to encrypt (or decrypt) by just imitating one-time pads and stream ciphers: XORing the randomized public part with a plaintext (or a ciphertext).
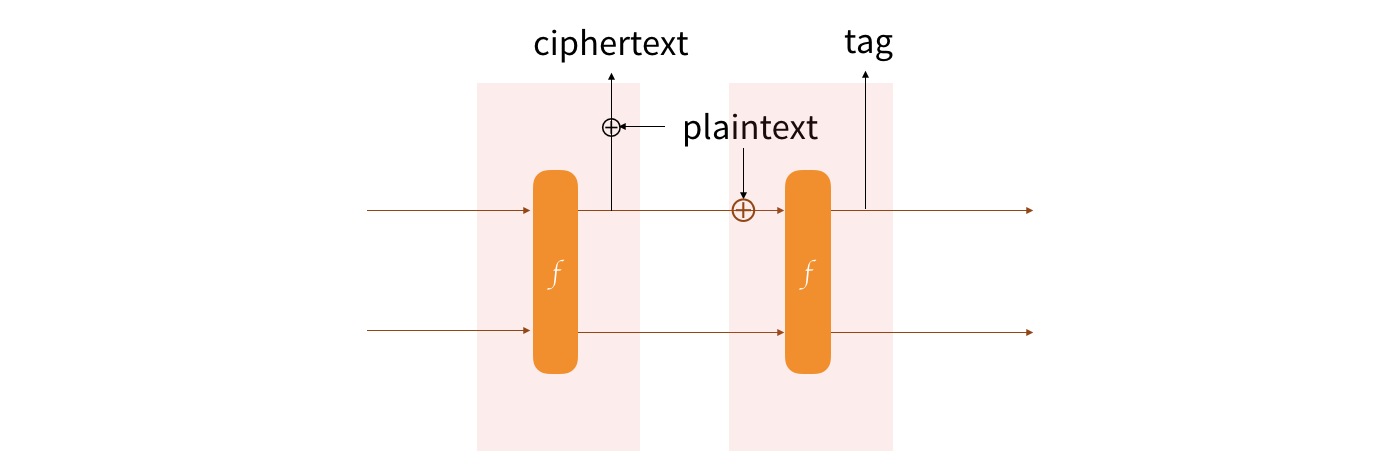
Once this is done, the state is permuted again to generate a new series of random numbers (in the public part) which will be the authentication tag, allowing us to authenticate everything that was absorbed previously.
After that the state can be cloned and differentiated to allow both sides to encrypt data on different channels (unless they want to use the same channel by taking turns). Strobe functions can continue to be used to continuously encrypt/decrypt application data and authenticate the whole transcript (starting from the first handshake message to the last message sent or received).
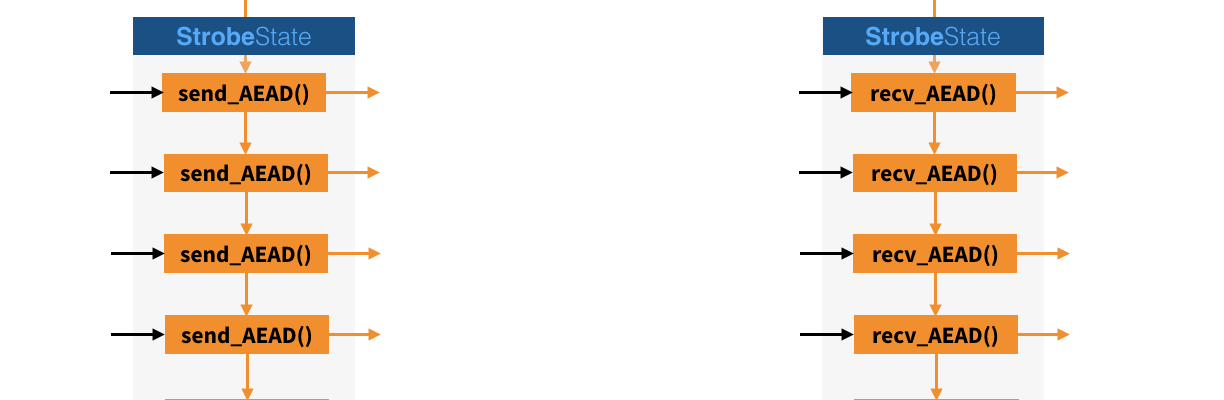
I thought the idea was worth exploring, and so I wrote a specification and proposed it as an extension to Noise. You can read it here). Details are still being actively discussed on the Noise mailing list. Major points of contention seem to be that the Strobe functions used do not introduce intra-handshake forward-secrecy, and that the post-handshake API does not mirror the Noise’s post-handshake API one (nonce-based) by default. The latter is on purpose to avoid having to setup nonces and keeping track of them if not needed (because messages are expected to arrive in order thanks to the transport protocol used underneath disco).
After all of that, I figured out that I would probably have to be the first one to implement Disco. So I went ahead and first implemented a Noise-based protocol in Golang (that I call NoisePlugAndPlay). I tested it with test vectors and other libraries to get a minimum amount of confidence in what I did, then I decided to implement Disco on top of it. The protocol I created is called libdisco.
It’s more than just a protocol to encrypt communications though. Since I’m using Strobe, I can also make it a symmetric cryptographic library without adding much lines of code (100 wrapping lines of code to be exact).
Of course it’s all experimental. I will not recommend anyone to use this in production.
Instead, play with it and appreciate the concepts. Down the line, this could really be the modern alternative to TLS we’ve been waiting for (of course I’m biased here). But the road is long and paved with issues that need better be fixed before entering a stable version.
If I caught your interest, go take a look at www.discocrypto.com.