Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
This is were everything starts, we now have an open peer-to-peer protocol that everyone on the internet can use to communicate.
1991
The US government introduces the 1991 Senate Bill 266, which attempts to allow "the Government to obtain the plain text contents of voice, data, and other communications when appropriately authorized by law" from "providers of electronic communications services and manufacturers of electronic communications service equipment". The bill fails to pass into law.
Pretty Good Privacy (PGP) - released by Phil Zimmermann.
1993 - The US Government launches a criminal investigation against Phil Zimmermann for sharing a cryptographic tool to the world (at the time crypto exporting laws are a thing).
1995 - Zimmermann publishes PGP's source code in a book via MIT Press, dodging the criminal investigation by using the first ammendment's protection of books.
That's it, PGP is out there, people now have a weapon to fight government surveillance. As Zimmermann puts it:
PGP empowers people to take their privacy into their own hands. There's a growing social need for it. That's why I wrote it.
1995 - The RSA Data Security company proposes S/MIME as an alternative to PGP.
1996
criminal investigation against Zimmermann and PGP is dropped.
PGP Inc is founded by Zimmermann, PGP becomes licensed-software.
GNU Privacy Guard (GPG) - version 0.0.0 released by Werner Koch.
PGP 5 is released.
The original agreement between Viacrypt and the Zimmermann team had been that Viacrypt would have even-numbered versions and Zimmermann odd-numbered versions. Viacrypt, thus, created a new version (based on PGP 2) that they called PGP 4. To remove confusion about how it could be that PGP 3 was the successor to PGP 4, PGP 3 was renamed and released as PGP 5 in May 1997
OpenPGP - This is a definition for security software that uses PGP 5.x as a basis.
1999
GPG version 1.0 released
Extensible Messaging and Presence Protocol (XMPP) is developed by the open source community. XMPP is a federated chat protocol (users can run their own servers) that does not have end-to-end encryption and requires communications to be synchronous (both users have to be online).
2002 - PGP Corporation is formed by ex-PGP members and the PGP license/assets are bought back from Network Associates
We argue that [...] the encryption must provide perfect forward secrecy to protect from future compromises [...] the authentication mechanism must offer repudiation, so that the communications remain personal and unverifiable to third parties
We now have an interesting development: messaging (which is seen as a different way of communication for most people) is getting the same security treatment as email.
2013 - The TextSecure (now Signal) application is introduced, built on top of the TextSecure protocol with Axolotl (now the Signal protocol with the double ratchet) as an evolution of OTR and SCIMP. It provides asynchronous communication unlike other messaging protocols, closing the gap between messaging and email.
2014
Matrix is introduced as a modern alternative to XMPP.
All in all, I should be the perfect user for PGP. Competent, enthusiast, embedded in a similar community. But it just didn't work.
WhatsApp now uses the Signal protocol, adding end-to-end encryption for its billions of users.
Another unexpected development: security professionals are now giving up on encrypted emails, and are moving to secure messaging.
Is messaging going to replace email, even though it feels like a different mean of communication?
Moxie's quotes are quite interesting:
In the 1990s, I was excited about the future, and I dreamed of a world where everyone would install GPG. Now I’m still excited about the future, but I dream of a world where I can uninstall it.
In addition to the design philosophy, the technology itself is also a product of that era. As Matthew Green has noted, “poking through an OpenPGP implementation is like visiting a museum of 1990s crypto.” The protocol reflects layers of cruft built up over the 20 years that it took for cryptography (and software engineering) to really come of age, and the fundamental architecture of PGP also leaves no room for now critical concepts like forward secrecy.
In 1997, at the dawn of the internet’s potential, the working hypothesis for privacy enhancing technology was simple: we’d develop really flexible power tools for ourselves, and then teach everyone to be like us. Everyone sending messages to each other would just need to understand the basic principles of cryptography. [...]
The GnuPG man page is over sixteen thousand words long; for comparison, the novel Fahrenheit 451 is only 40k words. [...]
Worse, it turns out that nobody else found all this stuff to be fascinating. Even though GPG has been around for almost 20 years, there are only ~50,000 keys in the “strong set,” and less than 4 million keys have ever been published to the SKS keyserver pool ever. By today’s standards, that’s a shockingly small user base for a month of activity, much less 20 years.
2018
the first draft of Messaging Layer Security (MLS) is published, a standard for end-to-end encrypted group chat protocols.
EFAIL releases damaging vulnerabilities against most popular PGP and S/Mime implementations.
In a nutshell, EFAIL abuses active content of HTML emails, for example externally loaded images or styles, to exfiltrate plaintext through requested URLs. To create these exfiltration channels, the attacker first needs access to the encrypted emails, for example, by eavesdropping on network traffic, compromising email accounts, email servers, backup systems or client computers. The emails could even have been collected years ago.
Why do people keep telling me to use PGP? The answer is that they shouldn’t be telling you that, because PGP is bad and needs to go away.
EFAIL is the straw that broke the camel's back. PGP is officially dead.
2019
Matrix is out of beta and working on making end-to-end encryption the default.
Moxie gives a controversial talk at CCC arguing that advancements in security, privacy, censorship resistance, etc. are incompatible with slow moving decentralized protocols. Today, most serious end-to-end encrypted messaging apps use the Signal protocol (Signal, Facebook Messenger, WhatsApp, Skype, etc.)
Let me introduce the problem: Alice owns a private key which can sign transactions. The problem is that she has a lot of money, and she is scared that someone will target her to steal all of her funds.
Cryptography offers some solutions to avoid this being a key management problem.
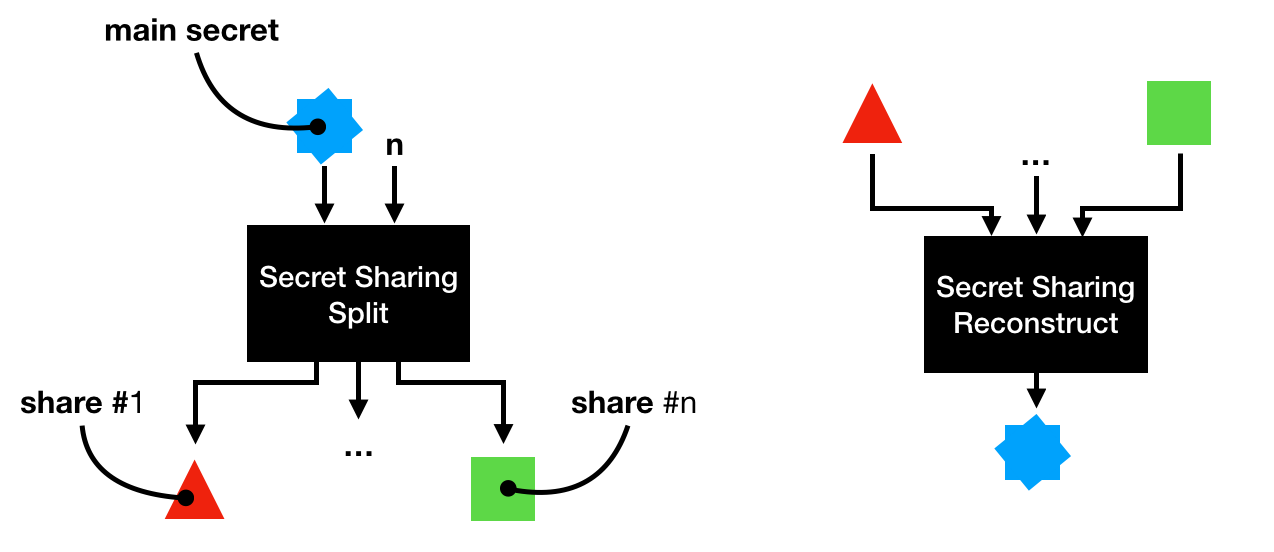
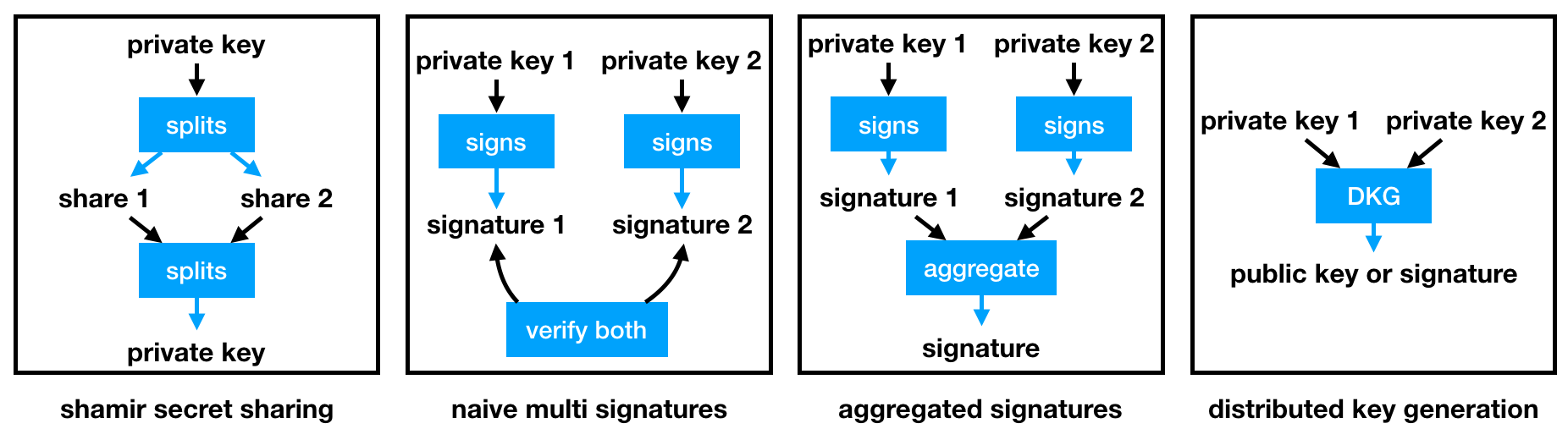
The first one is called Shamir Secret Sharing (SSS), which is simply about splitting the signing private key into n shares.
Alice can then split the shares among her friends. When Alice wants to sign a transaction, she would then have to ask her friends to give her back the shares, that she can use to recreate the signing private key. Note that SSS has many many variants, for example VSSS allows participants to verify that malicious shares are not being used, and PSSS allows participants to proactively rotate their shares.
This is not great though, as there is a small timeframe in which Alice is the single point of failure again (the moment she holds all the shares).
A logical next step is to change the system, so that Alice cannot sign a transaction by herself.
A multi-signature system (or multisig) would require n participants to sign the same transaction and send the n signatures to the system.
This is much better, except for the fact that n signatures means that the transaction size increases linearly with the number of signers required.
We can do better: a multi-signature system with aggregated signatures. Signature schemes like BLS allow you to compress the n signatures in a single signature. Note that it is currently much slower than popular signature schemes like ECDSA and EdDSA, so there must be a trade off between speed and size.
We can do even better though!
So far one still has to maintain a set of n public keys so that a signature can be verified. Distributed Key Generation (DKG) allows a set of participant to collaborate on the construction of a key pair, and on signing operations.
This is very similar to SSS, except that there is never a single point of failure. This makes DKG a Multi-Party Computation (MPC) algorithm.
The BLS signature scheme can also aggregate public keys into a single key that will verify their aggregated signatures, which allows the construction of a DKG scheme as well.
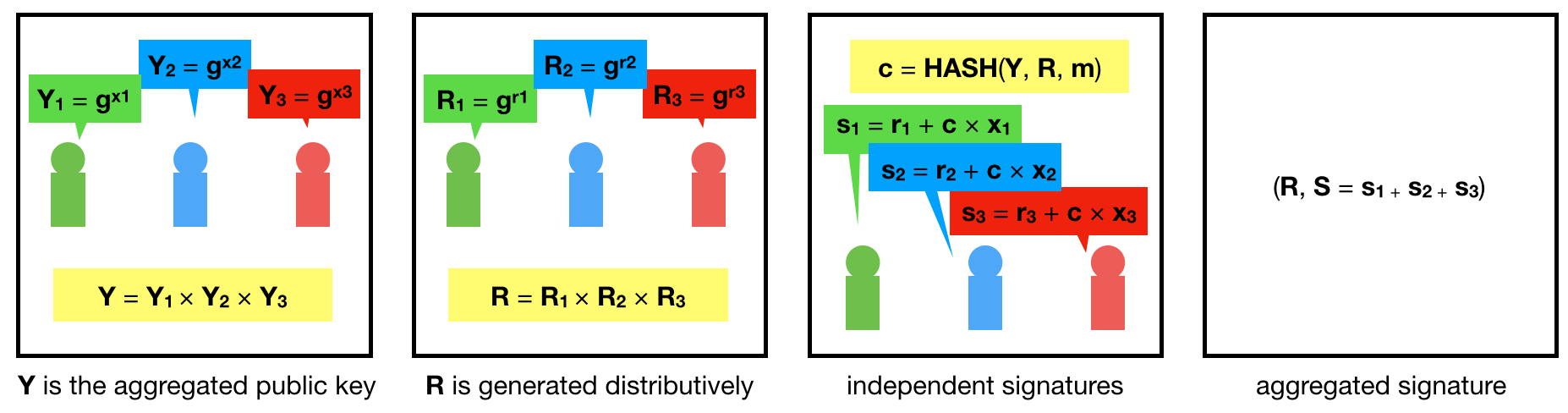
Interestingly, you can do this with schnorr signatures too! The following diagram explains a simplified version of the scheme:
Note two things:
All these schemes can be augmented to become threshold schemes: we don't need n signatures from the n signers anymore, but only a threshold m of n. (Having said that, when people talk about threshold signatures, they often mean the threshold version of DKG.) This way if someone loses their keys, or is on holiday, we can still sign.
Most of these schemes assume that all participants are honest and by default don't tolerate malicious participants. More complicated schemes made to tolerate malicious participants exist.
Unfortunately all of this is pretty new, and as an active field of study no standard has been decided on one algorithm so far.
That's the difference!
One last thing: there's been some recent ideas to use zero knowledge proofs (ZKP) to do what aggregated signatures do but for multiple messages (because all the previous solutions all signed the same message). The idea is to release a proof that you have verified all the signatures associated to a set of messages. If the zero knowledge proof is shorter than all the signatures, it did its job!
did you like this? This will part of a book on cryptography! Check it out here.
I am now half-way in the writing of my book (I wrote 8 chapters out of 16) and I am already exhausted.
It doesn't help that I started writing right before accepting a new position for a very challenging (and interesting) project.
But here I am, half-way there, and I think I'm onto something. I can't wait to get there and look at the finished project as a real paper book :)
To give you some insight into this process, let me share some thoughts.
Writing is hard. I have realized that I need at least a full day to write something. It does take time to get into the zone, and writing in the morning before work just doesn't work for me (and writing after work is even worse). As JP Aumasson put it (about his process of writing Serious Cryptography):
I quickly realized that I didn’t know everything about crypto. The book isn’t just a dump of my own knowledge, but rather the fruit of hours of research—sometimes a single page would take me hours of reading before writing a single word.
So when I don't have a full day ahead of me, I use my limited time to read articles and do research in topics that I don't fully understand. This is useful, and I make more progress during the week end once I have time to write.
Revising is hard. If writing a chapter takes some effort X, revising a chapter takes effort X^3 . After each chapter, several people at Manning, and in my circle, provide feedback. At the same time, I realize that there's much more I want to write about subject Y and I start pilling up articles and papers that I want to read before I revise the chapter. I end up spending a TON of effort revising and re-visiting chapters.
Getting feedback is hard. I am lucky, I know a lot of people with different levels of knowledge in cryptography. This is very useful when I want to test how different audiences read different chapters. Unfortunately people are good at providing good feedback, and bad at providing bad feedback. And only the bad feedback ends up being useful feedback. If you want to help, [the first chapters are free to read](https://www.manning.com/books/real-world-cryptography?a_aid=Realworldcrypto&a_bid=ad500e09
) and I'm ready to buy you a beer for some constructive negative feedback.
Laying out a chapter is hard. Writing a blog is relatively easy. It's short, self-contained, and often something I've been thinking about for weeks, months, before I put it into writing. Writing a chapter for a book is more like writing a paper: you want it to be perfect. Knowing a lot about the subject makes this even more difficult: you know you can make something great and not achieving that would be disappointing. One strategy that I wish I would have more time to spend on is the following one:
create a presentation about the subject of a chapter
give the presentation and observe what diagrams need revisiting and what parts are hard for an audience to understand
after many iterations put the slides into writing
I'm convinced this is the right approach, but I am not sure how I could optimize for this. If you're in SF and wants me to give you a presentation on one of the chapter of the book, leave a comment here :)
There are several cryptocurrencies that are doing really interesting things, Algorand is one of them.
Their breakthrough was to make a leader-based BFT algorithm work in a permissionless setting (and I believe they are the first ones who managed to do this).
At the center of their system lies a cryptography sortition algorithm. It's quite interesting, so I made a video to explain it!
PS: I've been doing these videos for a while, and I still don't have a cool intro, so if you want to make me a cool intro please do :D
My colleague Mesut asked me if using random identifiers of 128-bit would be enough to avoid collisions.
I've been asked similar questions, and every time my answer goes something like this:
you need to calculate the number of outputs you need to generate in order to get good odds of finding collisions. If that number is impressively large, then it's fine.
The birthday bound is often used to calculate this. If you crypto, you must have heard of something like this:
with the SHA-256 hash function, you need to generate at least 2128 hashes in order to have more than 50% chance of finding collisions.
And you know that usually, you can just divide the exponent of your domain space by two to find out how much output you need to generate to reach such a collision.
Now, this figure is a bit deceiving when it comes to real world cryptography. This is because we probably don't want to define "OK, this is bad" as someone reaching the point of having 50% chance of finding a collision. Rather, we want to say:
someone reaching one in a billion chance (or something much lower) to find a collision would be bad.
In addition, what does it mean for us? How many identifiers are we going to generate per second? How much time are we willing to keep this thing secure?
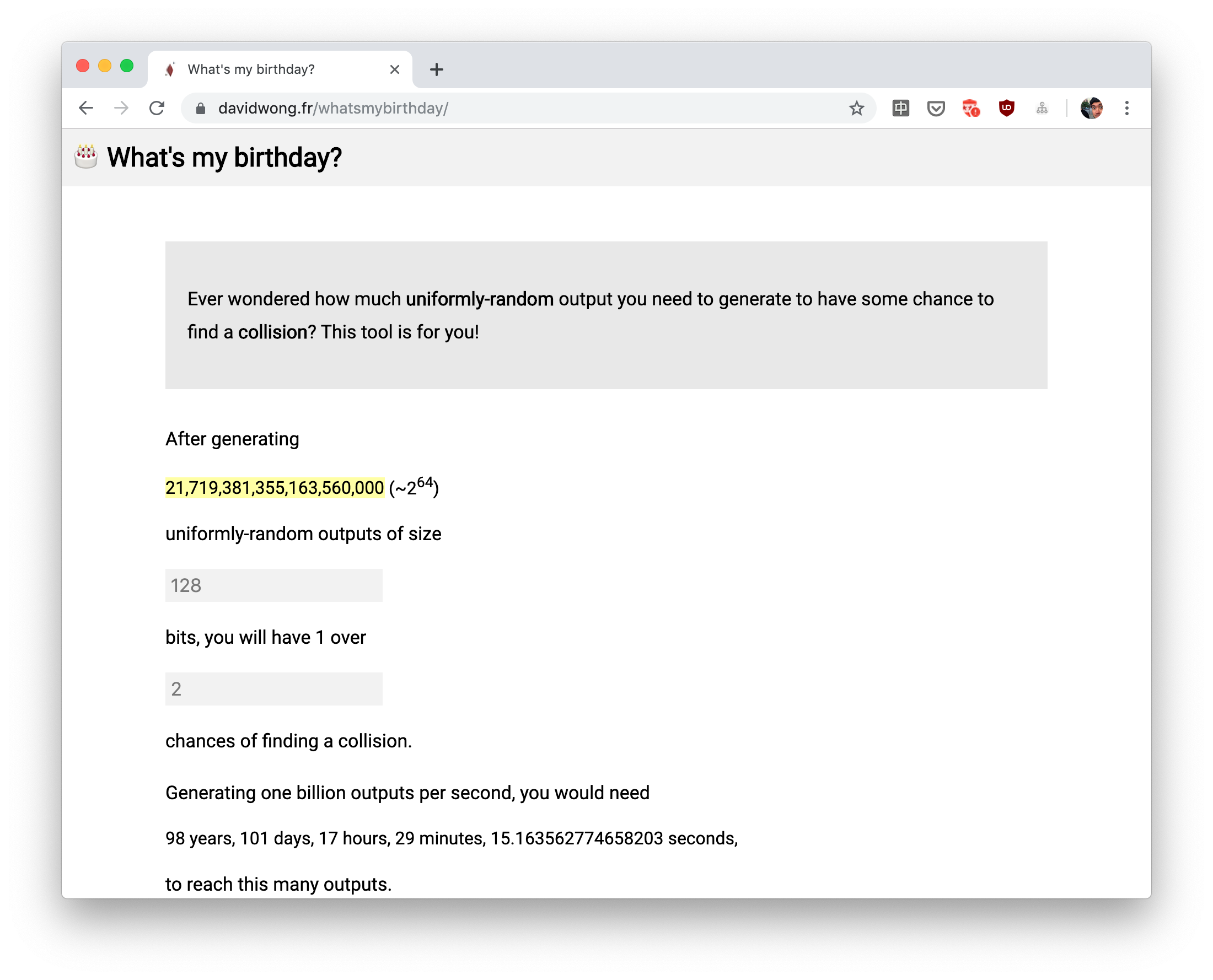
To truly answer this question, one needs to plug in the correct numbers and play with the birthday bound formula. Since this is not the first time I had to do this, I thought to myself "why don't I create an app for this?" and voila.
Thanks to my tool, I can now answer Mesut's question:
If you generate one million identifiers per second, in 26 years you will have one in a billion chance to generate a collision. Is this enough?
If this is not adversary-controlled, or it is rate-limited, you will probably not generate millions of identifiers per second though, but rather thousands, in this case it will take 265 centuries to get these odds.
Manning Publications reached out to me last year with an opportunity for a book. I had been thinking of a book for quite some time, as I felt that the landscape lacked a book targeted to developers, students and engineers who did not want to learn about the history of cryptography, or have to sort through too many technical details and mathematic formulas, and wanted an up to date survey of modern applied cryptography. In addition, I love diagrams. I don’t understand why most books underuse them. When you think of AES-CTR what do you think about? I bet the excellent diagrams from Wikipedia just flash in your mind.
The book Real World Cryptography was released today in pre-access. This means you’ll be able to read new chapters as I write them, and be able to provide feedback on topics you wished I would include and questions you wish I would answer.
and it seems to have broken the internet (sorry about that ^.^")
I've never worked on something this big, and I'm overwhelmed by all this reception. This is honestly pretty surreal from where I'm standing.
Libra is a cryptocurrency, which is on-par with other state-of-the-art blockchains. Meaning that it attempts to solve a lot of the problems Bitcoin originally had:
Energy Waste. The biggest reproach that people have on Bitcoin, is that it wastes a lot of our electricity. Indeed, because of the proof of work mechanism people constantly use machines to hash useless data in order to find new blocks. Newer cryptocurrencies, including Libra, make use of Byzantine Fault Tolerance (BFT) consensus protocols, which are pretty green by definition.
Efficiency. Bitcoin is notably slow, with a block being mined every 10 minutes, and a minimum confirmation time of one hour. BFT allows us to "mine" a new block every 3 seconds (in reality it can even go much faster).
Safety. Another problem with Bitcoin (or proof of work-based cryptocurrencies) is that it forks, constantly, and then re-organize itself around the "main chain". This is why one must wait several blocks to confirm that their transaction has been included. This concept is not great at all, as we've seen with Ethereum Classic which was forked (not so long ago) with more than 100 block in the past! BFT protocols never fork once they commit a block. What you see on the chain, is the final chain always. This is why it is so fast (and so sexy).
Stability. This one is pretty self-explanatory. Bitcoin's price has been anything but stable. Gamblers actually strive on that. But for a global currency to be useful, it has to keep a certain rate for people to use it safely. Libra uses a reserve of real assets to back the currency. This is the most conservative way to achieve stability, and it is probably the most contentious point about Libra, but one needs to remember that this is all in order to achieve stability. Stability is required if we want this to be useful for everyone.
Adoption. This final point is the most important in my opinion, and this is the reason I've joined Facebook on this journey. Adoption is the largest problem to all cryptocurrencies right now, even though you hear about them in the news very few people use them to actually transact (and most people use them to speculate instead). The mere size of the association (which is planned to reach 100 members from all around the world) and the user-base of Facebook is going to be a big factor in adoption. That's the most exciting thing about the project.
On top of that, it is probably one of the most interesting projects in cryptography right now. The codebase is in Rust, it uses the Noise Protocol Framework, it will include BLS signatures and formally verified smart contracts. And there's a bunch of other exciting stuff to discover!
If you're interested you should definitely check the many papers we've published:
I've read many comments about this project, and here's how I would summarize my point of view: this is a crazy and world-scale project. There are not many projects with such an impact, and we'll have to be very careful about how we walk towards that goal. How will it change the world? Like a lot of global projects, it will have its ups and downs, but I believe that this is a positive net worth project for the world (if it works). We're in a unique position to change the status quo for the better. It's going to be exciting :)
If you're having trouble understanding why this could work, think about it this way. You currently can't transact money easily as soon as you're crossing a border, and actually, for a lot of countries (like the US) even intra-border money transfers are a pain. Currently the best banks in the world are probably Monzo and Revolut, and they're not available everywhere. Why? Because the banking system is very complex. By using a cryptocurrency, you are skipping decades of progress and setting up a interoperable network. Any banks and custody wallets can now use this network. You literally get the same thing you would get with your normal bank (same privacy, same usability, etc.) except that now banks themselves have access to a cheap and global network. The cherry on top is that normal users can bypass banks and use it directly, and you can monitor the total amount of money on the network. No more random printing of money.
A friend compared this project to nuclear energy: you can debate about it long and large, but there's no doubt it has advanced humanity. I feel the same way about this one. This is a clear improvement.
I've started writing a book on applied cryptography at the beginning of 2019, and I will soon release a pre-access version. I will talk about that soon on this blog!
(picture taken from the book)
The book's audience is for students, developers, product managers, engineers, security consultants, curious people, etc. It tries to avoid the history of cryptography (which seems to be unavoidable in any book about cryptography these days), and shy away from mathematical formulas. Instead, it relies heavily on diagrams! A lot of them! As such, it is a broad introduction to what is useful in cryptography and how one can use the different primitives if seen as black boxes. It attempts to also serve the right amount of details, to satisfy the reader's curiosity. I'm hopping for it to be a good book for quickly getting introduced to different concepts going from TLS to PAKE. It will also include more modern topics like post-quantum cryptography and cryptocurrencies.
I don't think there's anything like this yet. the classic Applied Cryptography is quite old now and did not do much to encourage best practices or discourage rolling your own. The excellent Serious Cryptography is more technical and has more depth than what I'm aiming for. My book will rather be something in between, or something that would (hopefully) look like Matthew Green's blog if it was a book (minus a lot of the humor, because I suck at making jokes).