Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
I posted this on twitter initially, although it's short I think it's worthy of being reshared here.
The simplest abstraction is to see cryptocurrency / blockchain / distributed ledger technology as a database running on a single computer.
Everybody can access this database and there’s some simple logic that allows you to debit your account and credit someone else’s account.
The computer has a queue to make sure transactions are processed in order.
Blockchains that support smart contracts allow for people to install programs to that computer, which will add a bit more logic than simply debiting/crediting accounts. Others can then just send transactions to this computer to make a function call to any program (smart contract) that was installed on the computer.
The cool thing really is that we’re all using the same computer with the same database and the same programs.
Now in practice, nobody would trust a single point of failure like that. What if the computer crashes, or burns in a fire? Distributed systems to the rescue! We use distributed system protocols to run the same database on many computers distributed around the world.
These distributed system protocols effectively simulate a single database/computer so that a few computers failing doesn’t mean the end of the blockchain.
On top of that, we refuse to trust the computers that participate in this protocol. They could be lying about the balance in your account. We want the computers to police one another and agree on the database they are simulating.
That’s where consensus protocols are used: to make the distributed database secure even when some of the participants are malicious.
And that’s it. That’s blockchain tech for you. The obvious application is money, as the secure and simulated single computer is useful to simplify a payment system, but really any distributed database that cannot trust some of its participants can benefit from the advances there.
If you have questions about these analogies or other blockchain concepts, ask them in the comment section and I'll try to update this post :)
We recently released an update to our proof system for Mina called Kimchi. Kimchi is the main machinery we use to generate the recursive proofs that allow the Mina blockchain to remain of a fixed size of 22KB. It will also soon enable privacy and local execution of smart contracts with our snapps update. In this post, we'll go through what Kimchi is and what's different about it.
First, it is good to see where in the stack we are. Looking at the edge of the network, what we can see is a big blackbox: Mina.
If you're curious enough, you can open it and see what's inside. At some point you'll end up with pickles. Pickles is the recursion layer, it is the protocol that we use to create proofs of proofs of proofs of ... and reduce the blockchain to a fixed-size of under 22KB.
Pickles need something to create proofs though, and this is what Kimchi is:
In this post, we'll attempt to create some abstractions and simplifications to teach intuitions about what Kimchi is. We will try to keep explanations at a relatively high level, so it will be up to you to open the blackboxes that we will lay before you.
One of these black boxes, for example, are the pasta curves.
There's clearly a theme here. All that's left is to change Mina's name to another pickled condiment.
A bit of context
Kimchi is based on PLONK, a proof system released in 2019 by Ariel Gabizon, Zachary J. Williamson, and Oana Ciobotaru. Since then, many ameliorations and extensions have been proposed. There's been fflonk, turbo PLONK, ultra PLONK, plonkup, and recently plonky2. It's hard to follow, but essentially all these protocols implement variants of PLONK. Thus, we call them plonkish protocols. Kimchi is such a plonkish protocol.
Today, PLONK is regarded as one of the most ambitious general-purpose zero-knowledge proof constructions. Many projects like Zcash, Polygon Zero (formerly known as Mir Protocol), Aztec network, Dusk, MatterLabs (zksync), Astar, and anoma, have their own implementation of the proof system.
But first, what is a proof system?
Let's look at a scenario that should shed some light on the construction's interface. If you understand this section, you're halfway there, as you'll be able to think for yourself on how general-purpose zero knowledge proofs can be used without having to figure out what's going on inside of it.
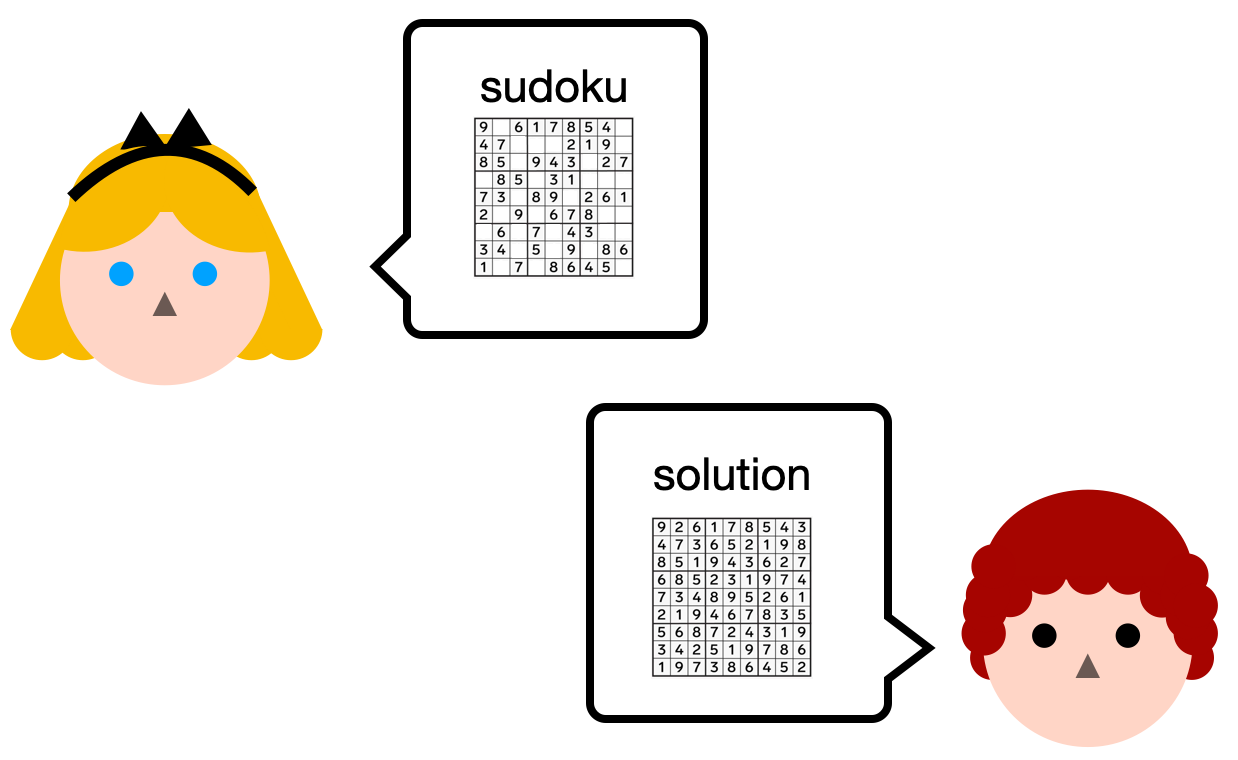
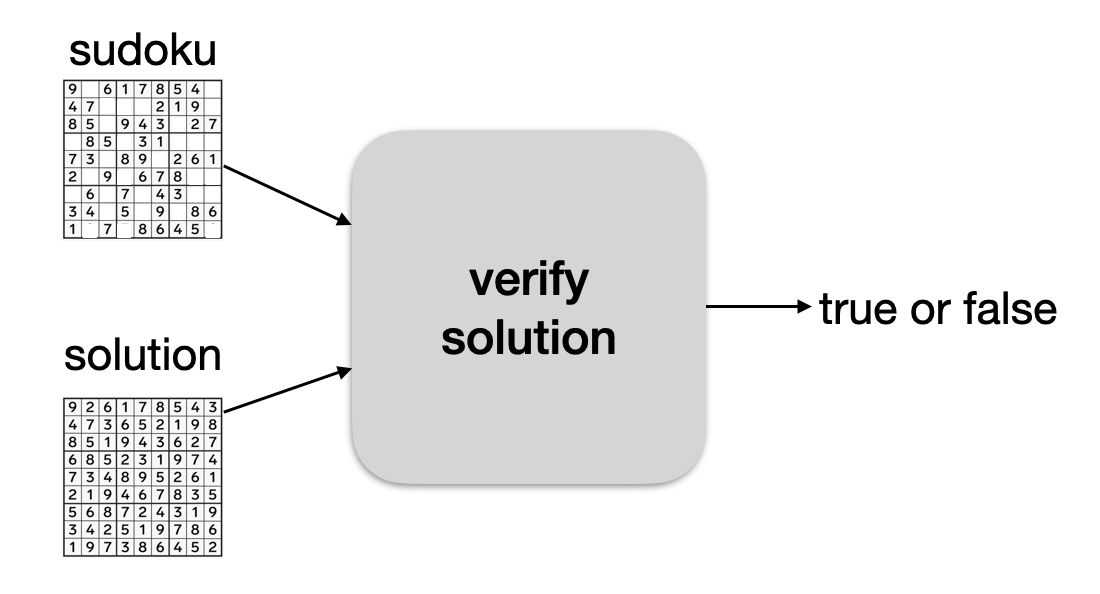
Let's imagine that Alice has a sudoku puzzle. She sends it to Bob, and Bob finds a solution to the puzzle. To prove it to her, he sends her the solution.
Alice can then run the solution, with the sudoku, in a program that will return true if the solution is correct.
The problem is that Bob doesn't really want to share his solution... So instead, he runs the program himself, on his laptop, and tells Alice "I know a solution, trust me, I just ran the verify solution program on my laptop and it returned true".
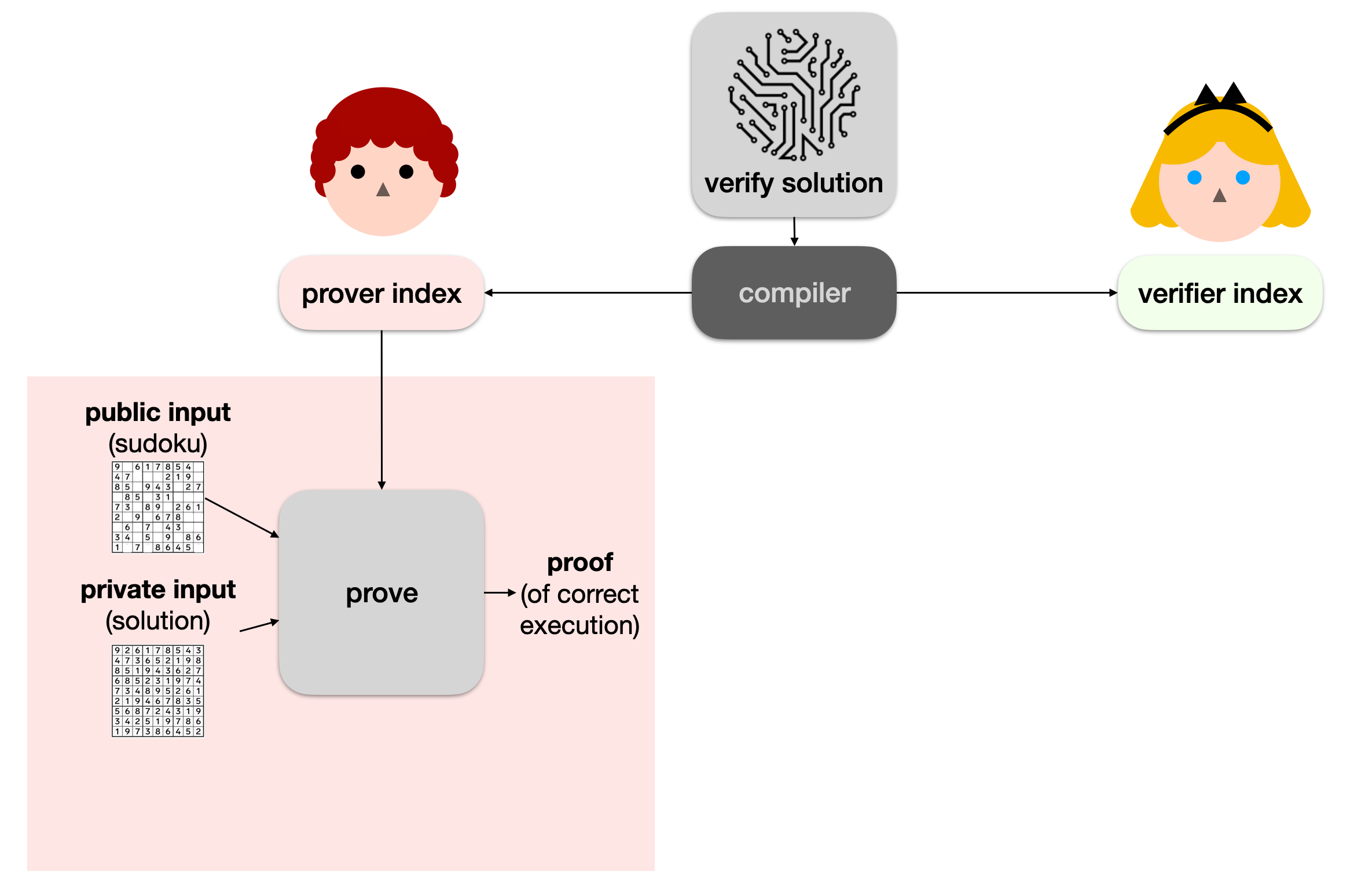
Obviously Alice has no reason to trust Bob. We're in a bit of a pickle. This is where protocols like PLONK can be useful. The first step is to take our verify solution program in a special format (I'll come back to that later) and compile it down to two distinct blobs of data:
the prover index (sometimes called the prover key, although it's not a real key)
the verifier index (sometimes called the verifier key, not a key either)
Then the prover (Bob) can use a prove algorithm with the prover index, the sudoku puzzle, as well as his solution to execute the program and produce a proof of correct execution (a proof that the program returned true in this case).
We call the sudoku the public input, as it is known by others (like Alice), and the solution the private input, as Bob wants it to remain secret.
Note: here we don't really care about the output (we just want the program to correctly run to completion, which is equivalent to returning true). Sometimes though, we do care about having a public output (perhaps the result of the execution, which Alice can use). In these cases, the public output is part of the public input. (This detail doesn't really matter in practice.)
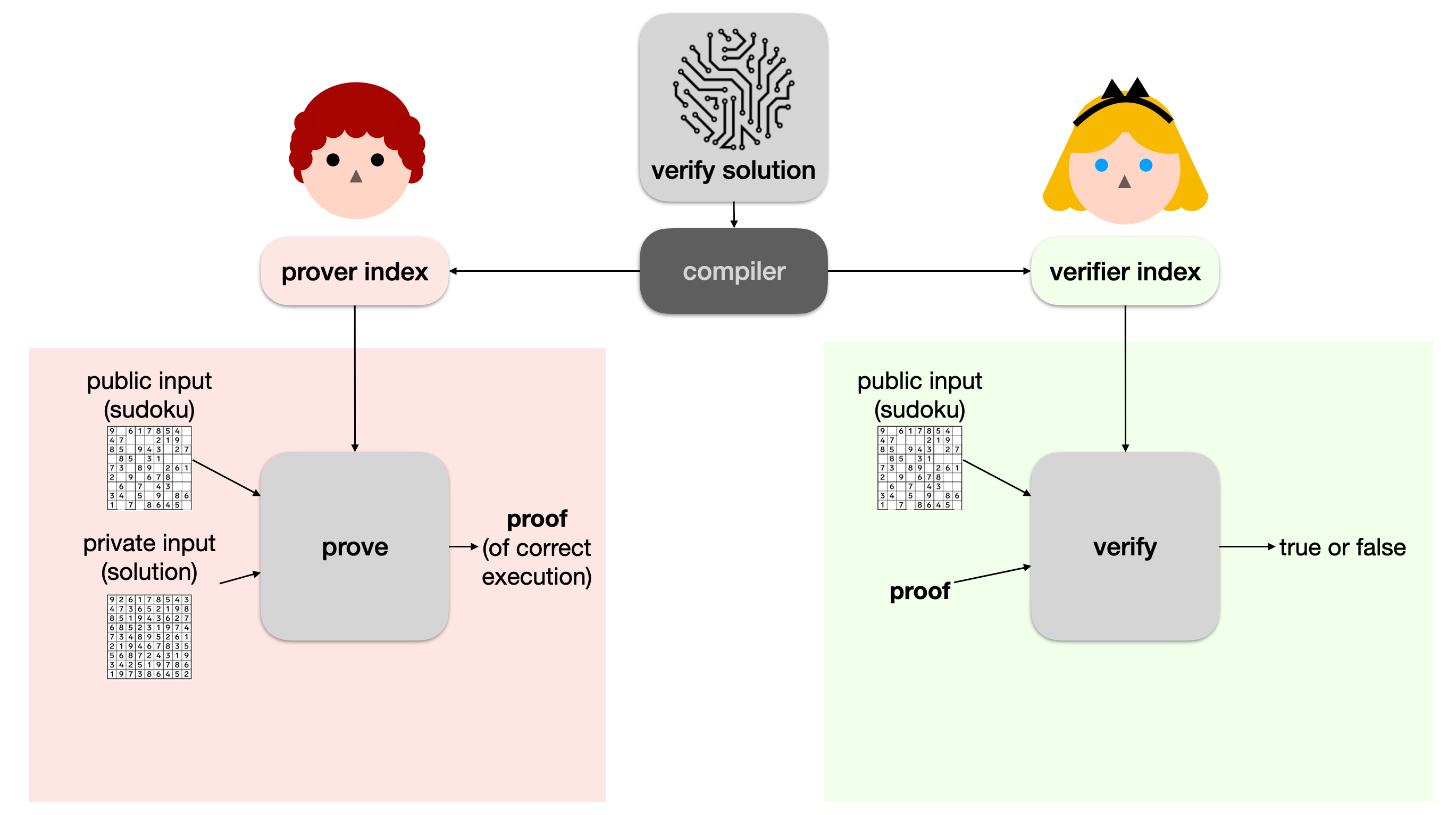
Now, Bob can simply give the proof to Alice, and Alice can verify it with another algorithm called verify. If the verify function returns true, she knows that Bob correctly ran the program verify solution to completion (using her sudoku puzzle and his solution).
What about Snapps?
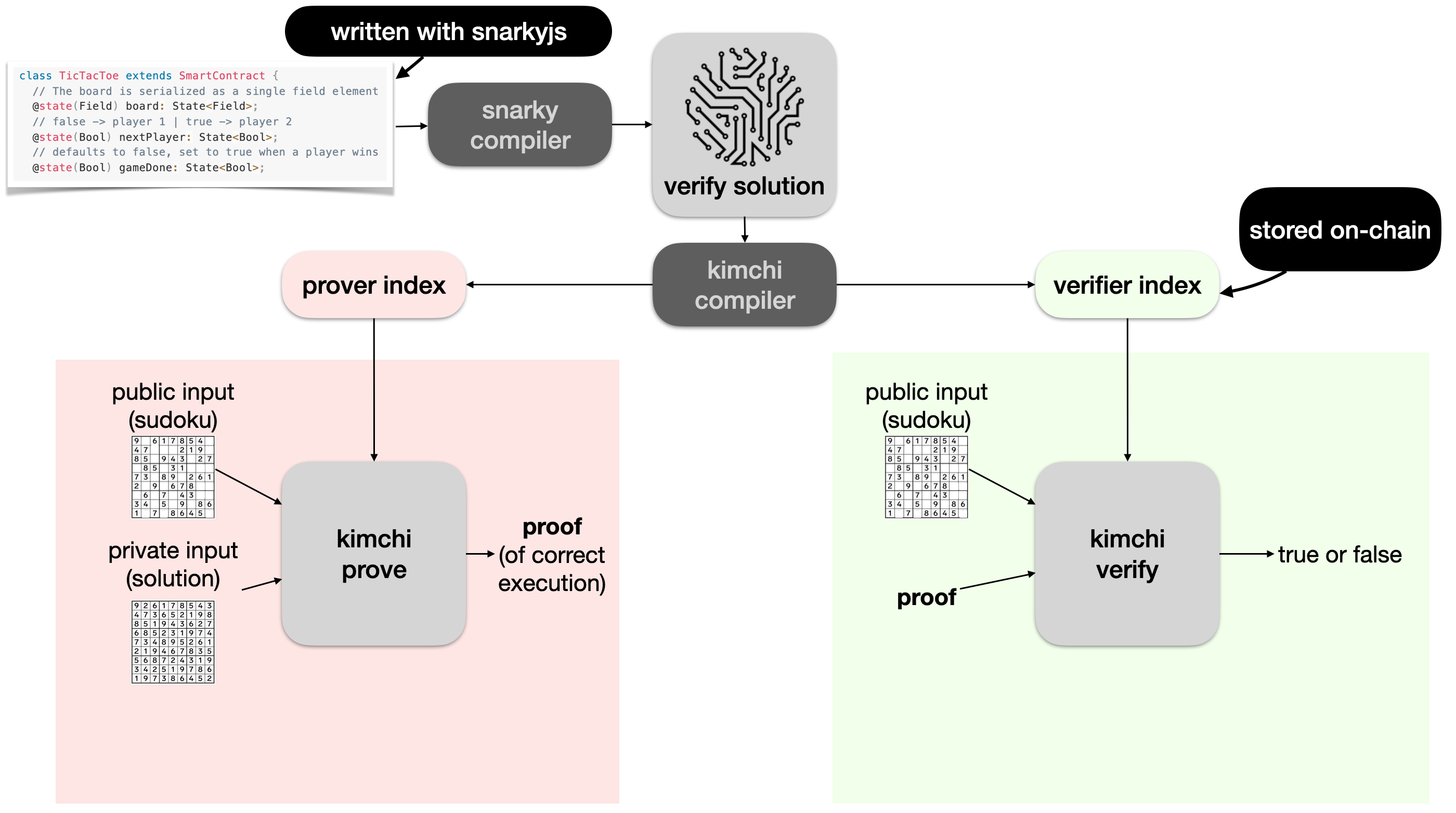
In Mina, snapps (zero-knowledge smart contracts) can be written in typescript using the snarkyjs library, and then compiled down to some intermediary representation with snarky. A Kimchi compiler can then be used to compile the program into the prover and verifier indexes, and both sides can use Kimchi provided functionalities to produce proofs as well as verify them.
The verifier index is uploaded on chain, which allows anyone to verify proofs contained in transactions that claim that they executed a snapp correctly.
Arithmetic circuits
Let's now address the elephant in the room: cryptography is about math and numbers, but programs like our sudoku solution verifier are about instructions and bits. That's not going to work. What can we do about it? The solution is to use arithmetic circuits!
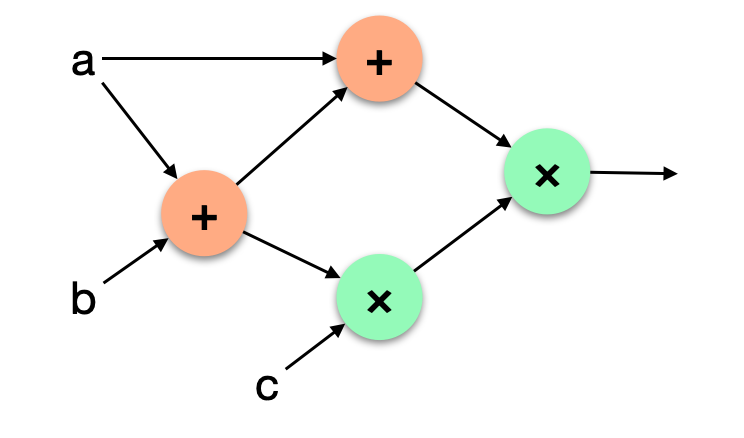
Arithmetic circuits are circuits made out of arithmetic gates:
I'll argue that with an addition gate (that adds two numbers together) and a multiplication gate (that multiplies two numbers together) we can rewrite most programs.
Let's look at a simple example. Let's imagine that I want to use a bit x in a computation. To do that, I first need to make sure that x is indeed a bit (that it is 0 or 1).
Look at the following equation: x(x-1) = 0. This should be true, only if x is 0 or 1. We call that a constraint (we're constraining x to some values). Writing circuits for our proof system is about writing such constraints. Many of them in fact.
Let's see how that works with our arithmetic gates.
First we add 1 to -x (I'll explain how to get -x from x later). Then we use the multiplication gate with the output:
The output of the multiplication gate must be 0 (that's the constraint we want to write).
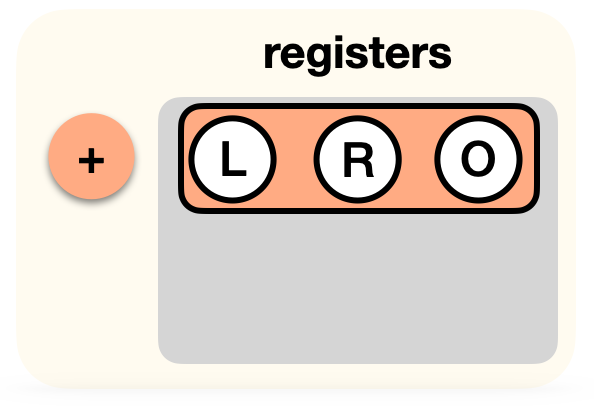
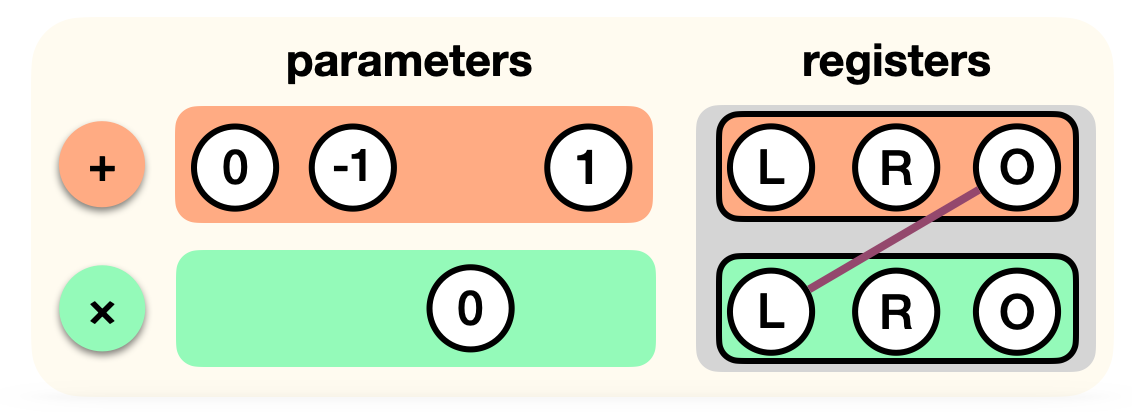
This is it, our circuit for now only has two gates. In PLONK, you would write this down as a list of gates acting on registers (the two inputs L and R, and the output O):
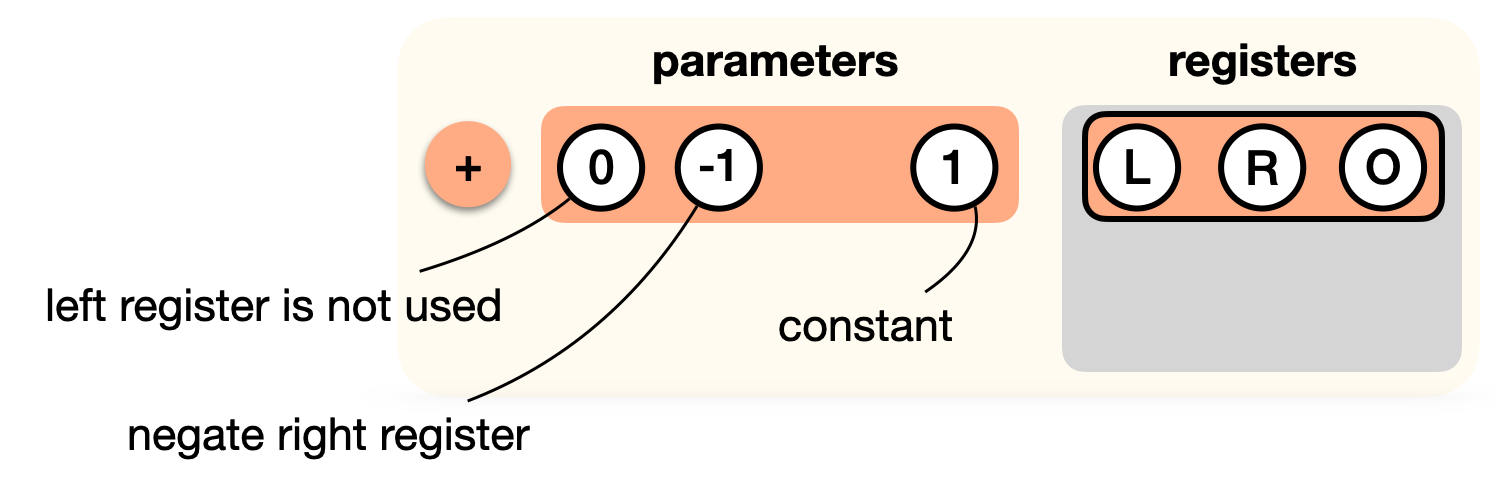
Now, we aren't really doing an addition of L and R here, we're rather adding 1 to -R. How do we do this? Perhaps we could have a "add with constant" gate, and a "subtract gate"? Instead, we "tweak" our addition gate:
Now let's add the multiplication gate to the list. But remember, the output register is not used, as it must be 0. So we tweak that gate as well:
More on tweaking these gates later.
There's one last thing that we're missing: the output register of the first gate is the left register of the second gate. We can simply wire the two registers to encode this correspondance:
And this is how we represent a circuit in PLONK! We just list all the gates (and their parameters) as well as the wiring between the registers they act on.
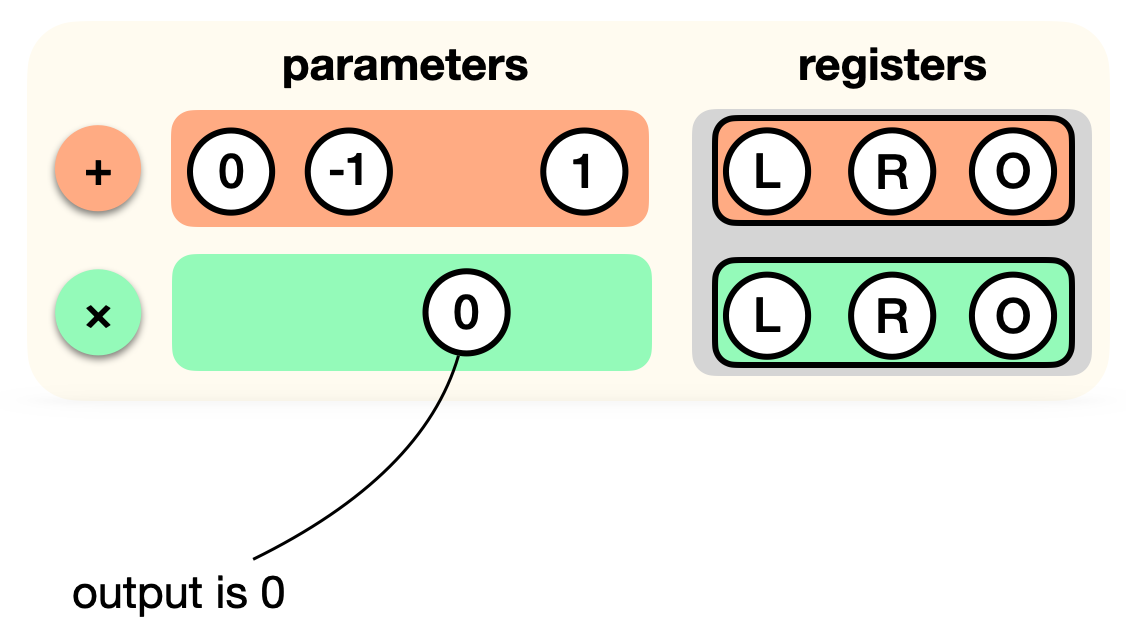
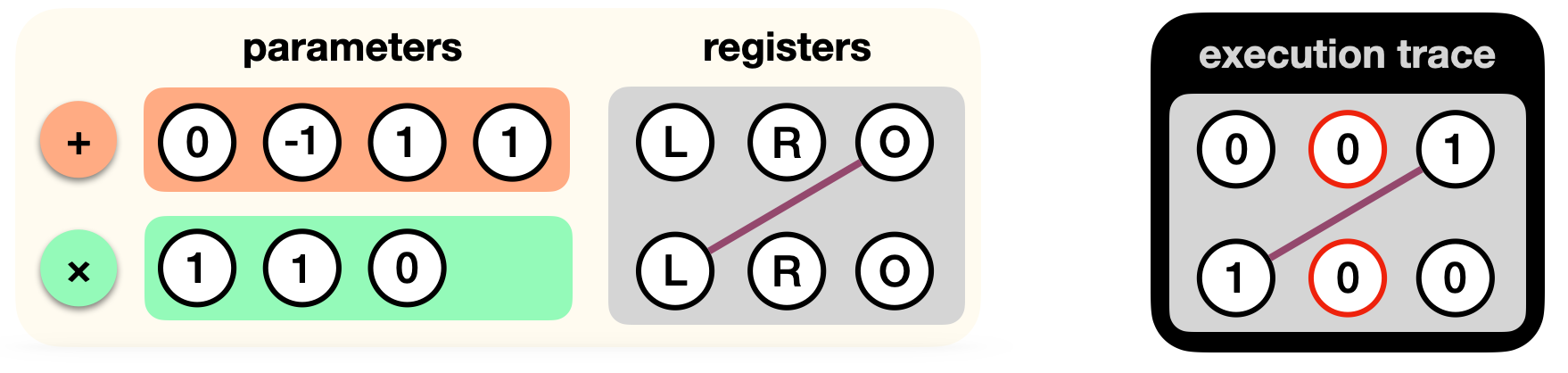
Now, when a prover wants to produce a proof, they will run the program and record the values of each registers in an execution trace. For example, here is one that takes x = 0.
Note: the values in the left register of the first gate, and the output register of the second gate, can be anything as they are not used by the gates.
One simplification I made, is that we don't know where x comes from here. In a real circuit, the right registers of this execution trace are wired to another register containing the value x (or perhaps it is given as private or public input to the circuit, but I will avoid explaining how this works here).
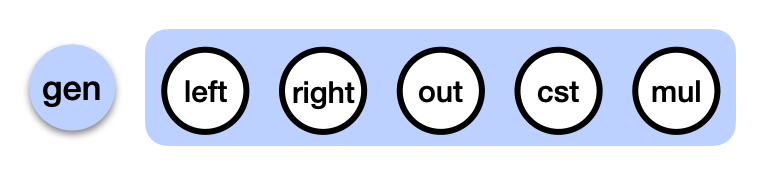
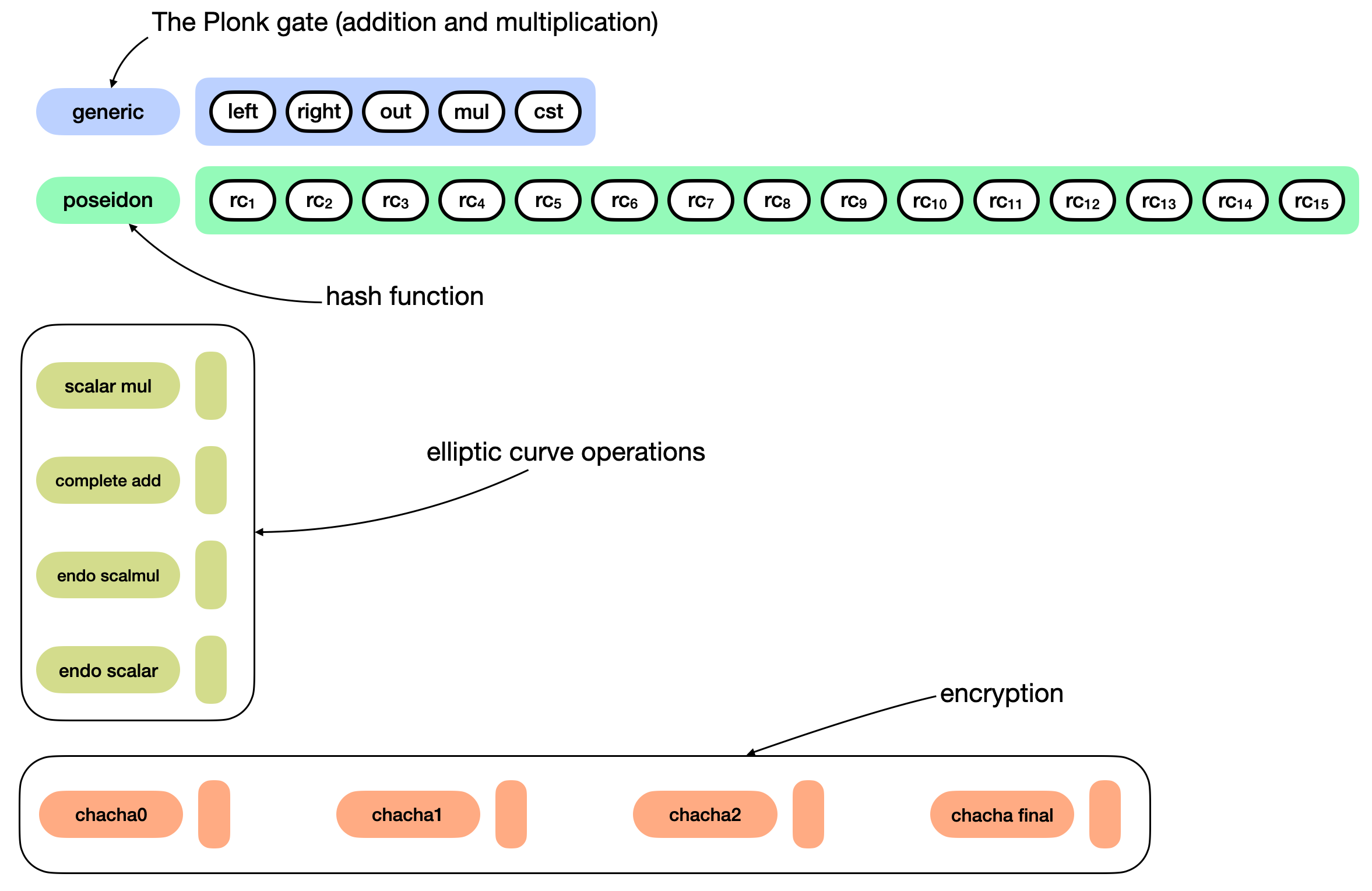
Another simplification I made, is that in reality the addition and multiplication gates are implemented as a single tweakable gate that we call the generic gate in Kimchi:
Tweaking the parameters of the generic gate essentially turns it into different gates (addition, multiplication, addition with constant, subtraction, etc.)
From PLONK to Kimchi
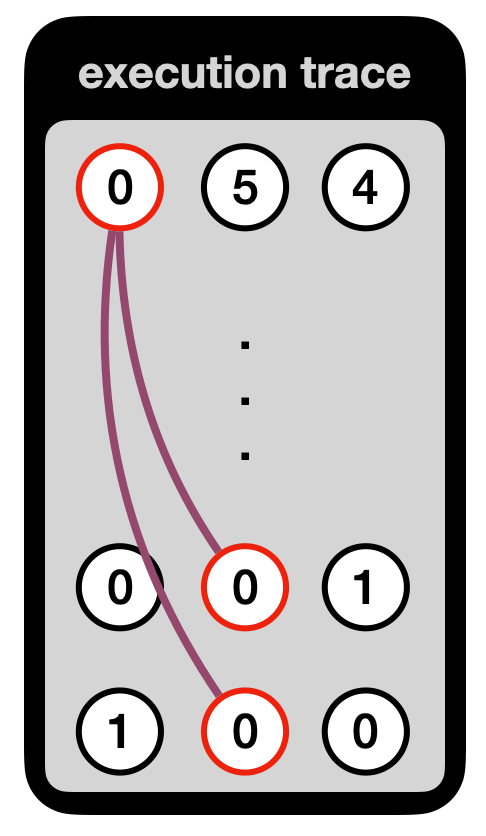
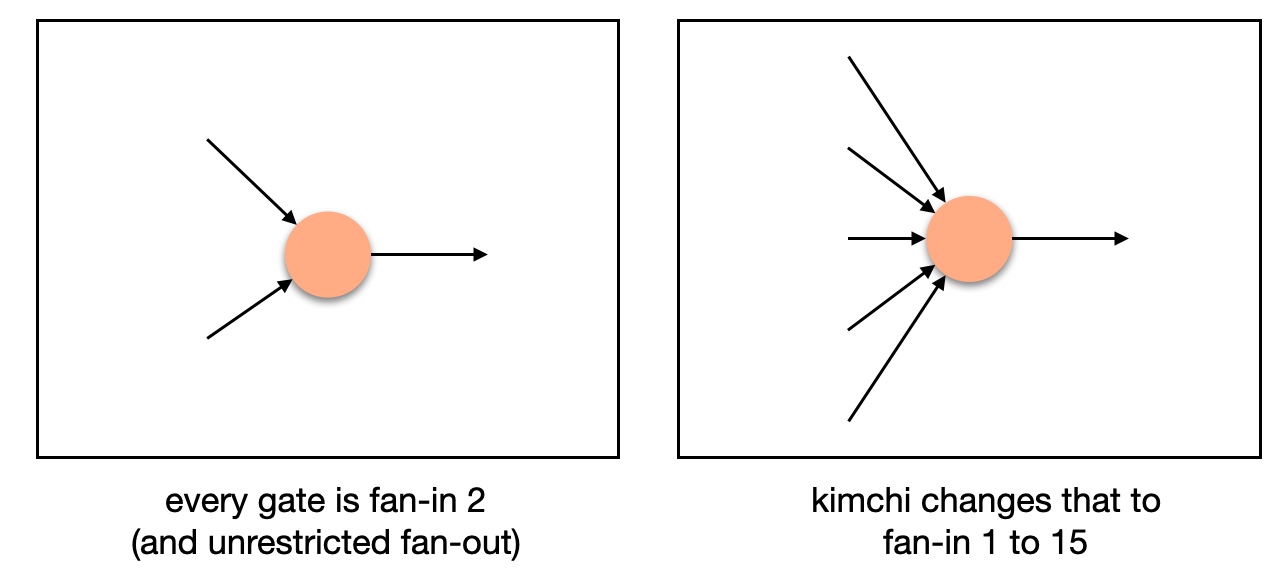
Kimchi is a collection of improvements, optimizations, and alterations made on top of PLONK. For example, it overcomes the trusted setup limitation of PLONK by using a bulletproof-style polynomial commitment inside of the protocol. This way, there is no need to trust that the participants of the trusted setup were honest (if they were not, they could break the protocol). Talking about circuits, since we're talking about circuits here, Kimchi adds 12 registers to the 3 registers PLONK already had:
These registers are split into two types of registers: the IO registers, which can be wired to one another, and temporary registers (sometimes called advice wires) that can be used only by the associated gate.
More registers means that we now can have gates that take multiple inputs instead of just one:
This opens new possibilities. For example, a scalar multiplication gate would require at least three inputs (a scalar, and two coordinates for the curve point). As some operations happen more often than others, they can be rewritten more efficiently as new gates. Kimchi offers 9 new gates at the moment of this writing:
Another concept in Kimchi is that a gate can directly write its output on the registers used by the next gate. This is useful in gates like "poseidon", which need to be used several times in a row (11 times, specifically) to represent the poseidon hash function:
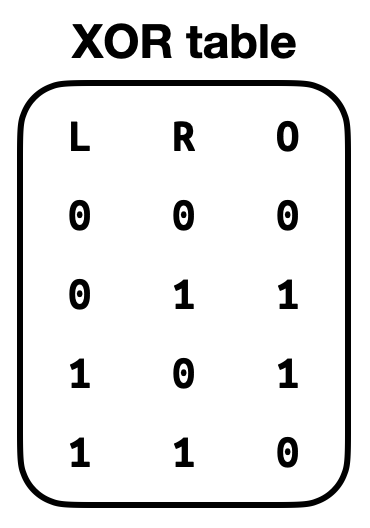
Another performance improvement implemented in Kimchi are lookups. Sometimes, some operations can be written as a table. For example, an XOR table:
An XOR table for values of 4 bits is of size 28. Implementing this with generic gates would be hard and lengthy, so instead Kimchi builds the table and allows gates (so far only Chacha uses it) to simply perform a lookup into the table to fetch for the result of the operation.
There's much more to Kimchi, but this is for another time. You can check out the implementation here and if you're curious opening the other blackboxes you can check our our in-depth explanations here.
To summarize
Pickles now uses an upgraded proof system: Kimchi. Kimchi brings several optimizations and quality-of-life improvements to circuit builders. This should allow for faster provers, larger circuits, and potentially shorter proof sizes!
Today, I want to introduce a tool called cargo-spec.
I've been using it at work to specify kimchi, the general-purpose zero-knowledge proof system that is used in production for the Mina blockchain.
Before I introduce the tool, let me give some motivation behind why I created it, as well as why it is designed the way it is.
Specifications are important
First, let's talk about specifications. Most of the cryptographic schemes that are used in the wild tend to be specified. This is not necessarily a crypto thing, but this is where I have experience. These specifications often look like RFCs, but it is not the only standard.
More importantly, specifications are multi-purpose. For example, they are used to help others implement an algorithm or protocol. This is usually the reason for these RFCs, but not necessarily what my tool targets.
Specifications are also used to help others understand how a protocol works. Indeed, if you want to understand a protocol, and it only exists as code, you'll have to reverse engineer the code. Not everyone is good at reverse engineering. I would even argue that most people are bad at it. Not everyone can read the language you implemented your protocol in. Not everyone has the time to do it.
I used to work in a team where researchers wanted to formally analyze a protocol, but had no clue how it worked. And of course, they didn't want to read the massive Rust codebase to do that. Security engineers would want to review it for bugs, but what is a bug without a spec? How can you understand the logic without a higher level document describing the protocol?
This is where specifications can also be really useful: to let security engineers audit your code. With a spec, they can simply match it to the code, and any divergence is a bug.
Your code is a book
I want to take a short detour to talk about writing. Writing code is like writing a book. It will be read again and again, changed, and maintained by others.
A book has sections, chapters, intros, outros, callouts, etc. Why shouldn't code have the same things? Code sorts of has that already: files, modules, packages, namespaces, function names, variable names, comments, etc. are all tricks a developer can use to make their code readable.
But this doesn't mean you can't add actual sections in your code! There's probably a reference to Knuth's literal programming, but it's a bit old, so I'll give you a reference I really enjoyed recently: Literate Programming in the Large by Timothy Daly.
In this talk, Timothy makes the point that we're the first user of our documentation: as we will all forget the code we wrote at some point, documentation (or a specification) might help drastically. Without it, changing the code could become a herculean task.
So Timothy's point is that you should write a book about your code. That there's no reason not to write and write and write. Perhaps there'll be too much stuff? But we live in the future and we don't look at real books, but at pages that you can grep and index. Even outdated stuff might help, as it will give some insight or rational.
How to specify?
Back to specs! The way I've worked in the past with specifications, was to write them as documents that lived outside of the codebase. But when you work on a project with a home-made protocol, you always have a reference implementation.
That reference implementation is a living thing, it changes over time.
This means that specifications of living projects tend to diverge from the implementation(s), unless they are maintained by rigorous developers.
The other solution is to write your specification in the code, where updates can be made by developers more easily as they adjust the code.
But a specification is a structured document, with intros, outros, overviews, and other things that aren't really a good fit for being split apart in multiple files.
One day, I asked myself the question, why not both?
cargo-spec is a tool written in Rust, although it works with codebases in any languages, to implement these ideas.
The tool expects two things:
a template, which contains the organization of your spec in markdown. You can write content there, but also use placeholders when you want parts to be filled by your code.
a specification file, that helps you list the places in your code that you want to use in the specification.
The tool then extract parts of your code, replace the placeholders of your spec with that content, and produces the final specification (for now two formats are available: markdown and respec).
In the diagram above that I made at work, I show how the kimchi specification is created. I then use mdbook to serve it, as it contains LaTeX equations. I could have used hugo (which I did, initially), or really any other tool. You might also just want to have your spec in markdown file and leave it at that.
What is extracted from your code? Comments starting with a special prefix: //~ (or #~ in python, or (*~ ... *) in OCaml, etc.)
Rustdoc vs spec doc
You can ignore this section if you're not interested in specifying Rust code, although I'll give some insights that might be useful for other languages that also support special comments for code documentation.
By default, Rust has two types of comments: the normal ones (//), but also documentation comments (///, //!, and /** ... */). When you run cargo doc, the Rust documentation comments from your code get parsed and an HTML documentation is generated from them.
Since you can't use both spec comments and doc comments, how can you reconcile the two? The philosophy of cargo-spec, is that a language doc comment should be used to specify the interface of the code only; not the internal logic. As such, documentation should treat its library like a blackbox. Because who uses documentation? Developers who want to work with the library without having to understand its inners.
On the other hand maintainers, contributors, reviewers, etc. will mostly look at what's inside, and this is what you should specify using spec comments.
Examples
You're curious to see it in action? Interestingly, The specification of cargo spec is written using cargo spec itself. It's a pretty simple respec specification mostly here to showcase the tool.
During the last weeks I've been working on the Kimchi specification at work, where I've been using this tool as well. is written using it as well. You can check it out here, but keep in mind that it is still work in progress.
I'm excited to see if this will change the game, and if it will push more people to specify their code. Let me know if you find it useful :)
If you're trying to get into zero-knowledge proof systems (like Plonk) and are trying to contribute to open source, there's a number of tasks sitting in https://t.co/t3j5gokkdg and I'd be happy to help you start with one o.o
So I made a video to introduce the kimchi repository to newcomers who want to contribute:
If you're interested, ping me on twitter :) there's a lot of opportunities to learn in there!
comment on this story
As some of the readers of this blog know, I worked for two years at Novi (Facebook) on the Diem (formerly known as Libra) cryptocurrency. The project was recently dismantled, most likely due to regulator unwillingness to help a non-government backed cryptocurrency reach millions of people at scale.
Today, a group of 17 ex Novi/Diem engineers and researchers announced Aptos, presumably a fork of Diem. From what I understand, this means that a state-of-the-art blockchain that has been pushing the envelop in terms of innovation, security, and performance, and that's been in development for the last 4 years, now has a path to launch.
I'm guessing that we're going to see the typical proof-of-stake approach being implemented (unlike Diem's proof of authority) as well as a revamped set of smart contracts (written in Move) to govern the new blockchain. Besides that, the blockchain was already in a solid shape a year ago so I don't foresee any major changes.
Congratulation to the new team :) this is exciting.
A product can be seen as a production line. That's what The Phoenix Project novel argues. It makes sense to me. Things gets assembled and passed around, work stations can become bottlenecks, and at the end of the line you deliver the product to the user. In that production line, pieces come from your own warehouse, or from external vendors. That distinction my friend, is what we call "insider threat vs supply chain attacks" in security.
Insider threat is a problem that's mostly ignored today. Large corporations have spies in them, that's a given. They have poor ways to deal with them, but that's fine, because most of these spies are working from other governments and they're tolerated in the grand scheme of things. They might inject backdoors here and there (see the juniper incident) but most of the times they remain unnoticed and unproblematic.
Supply chain attacks, on the other hand, are from less sophisticated attackers. They're from script kiddies, blackhats, "hackers", and others that we generally don't label much as advanced (like in advanced persistent threat). But they are getting more and more advanced.
To counter supply chain attacks, the first thing you can do is inventory (some people might call this threat modeling). The idea, really, is to list all of the pieces and the flows that make up your product. An acyclic directed graph of machines and humans. Once you have that, it's much clearer what the different attack vectors are.
I'm a software person, so I mostly focus on software security. When you write software, you worry about a few things:
your dependencies
the flows around your code evolution
what goes into a release
how that release gets into production
The fourth point is sort of an infra problem, so it's not the most urgent problem you should think about as a developer. I'd say the third point could be an infra problem as well, unless you're lucky enough to have release engineers or dev infra people working in your company. The second point is probably Github, and all the corner cases you have around it. For the most part, you can choose to trust Github. The first point, the dependencies you're using, that is your problem.
I learned a few things, back at Facebook when I was working on libra/diem, and I think that could be useful to others. First, not languages are created equal. Languages like Golang are fantastic because they provide a rich standard library. What some would call a battery-included stdlib. Thanks to that, you rarely see Golang projects depend on more than 100 transitive dependencies (this means that I'm including dependencies that are used by your direct dependencies, and so on). Other languages, like javascript and Rust can have their dependency graph just blow up due to poor standard libraries and great package managers.
When I looked at what we were doing at the time with libra/diem, I got obsessed with the large amount of dependencies that our software used. A year in, I got inspired by Feymann's story about investigating the challenger disaster, and the way he managed to pinpoint the problem by using the wisdom of the crowd.
The wisdom of the crowd is this concept where the average of all people's guesses to a question can be extremely close to the real answer. The best demonstration to this concept is when a bunch of people are asked to estimate the number of jelly beans contained in a jar. Check that video on youtube. If you're french, fouloscopie is a great youtuber who does research about crowds and their behavior.
So I used the same methodology. I created a form and sent it to all the engineers at the company. The form asked the following: "for each pieces of our big puzzle, what is your estimation of the risk from 0 to 5? If you don't know leave it blank." The result was eye opening. The trivial parts were deemed not risky, as expected. The confusing parts (like consensus and HSM code) had estimations that were all over the place. Dependencies were ranked as the highest risk. Finally, some other parts that I had overlooked got ranked as high-risk which made a lot of sense and changed our strategy for the rest of the year.
So dependencies were definitely a problem, people agreed. What could we do? First, I developed a tool called dephell that would allow us to get some quick stats on the dependencies we were using in our Rust project. The tool was a bit buggy, and incorrect at times, but it was good enough to show us outliers. We used it on every libraries in our project to get a sense of what dependencies they were relying on. We had hundreds and hundreds of dependencies, so that was quite a hard task, but a few patterns stood out.
Sometimes, we used many different dependencies to solve the same problem. The fix was easy: decide which one was the most solid dependency and use that one. Other times, we would use a large dependency, that would import more dependencies, and notice that if we would rewrite it ourselves we could live with a much smaller amount of code and no dependencies. This is what I did when I wrote libra's noise implementation which removed a large amount of code and a few dozens of dependencies to a few hundreds of lines of code. Sometimes, we realized that the dependencies we were using were not great: they were not maintained, had unknown maintainers and contributors, lots of unsafe code, and so on. Finding a better alternative was usually the way to go.
That analysis got us to remove a lot of dependencies. But dependencies continue to creep in, and so we needed a flow to prevent that growth. The obvious solution was to add friction to the process of adding a dependency. Making sure that I was involved in accepting any PR that added a new dependency (via continuous integration) was enough. Most of the times it would go like this:
hey! Can I get a review from you for this PR, it looks like you need to look at it since I'm adding a new dependency.
for sure! I looked at the dependency and it's adding X lines of code, as well as Y additional dependencies. Is this something that's really necessary? Are there better alternatives?
hum... actually I could write that in a few lines of code, let me try that instead.
At that point, you're having a good sense of what your dependencies are, you sorted them out and even did some cleaning, and you stopped the growth. You still have problems: dependencies evolve. We know, from experience, that the risk of not updating dependencies is higher than updating. That's because a lot of your updates will be bug fixes. So you need to update. Updating adds a few non-negligible risks though:
a backdoor could have been introduced in a (transitive) dependency
new dependencies could be added by the update
new bugs could be introduced by the update
The cost of 3 is negligible compared to the bug fixes. Remember: you can't review every dependencies you're using. You wouldn't be using third-party dependencies in the first place if you had all the time in the world. 2 has to be taken into account in your dependency growth control strategy. 1 is the subject of this post.
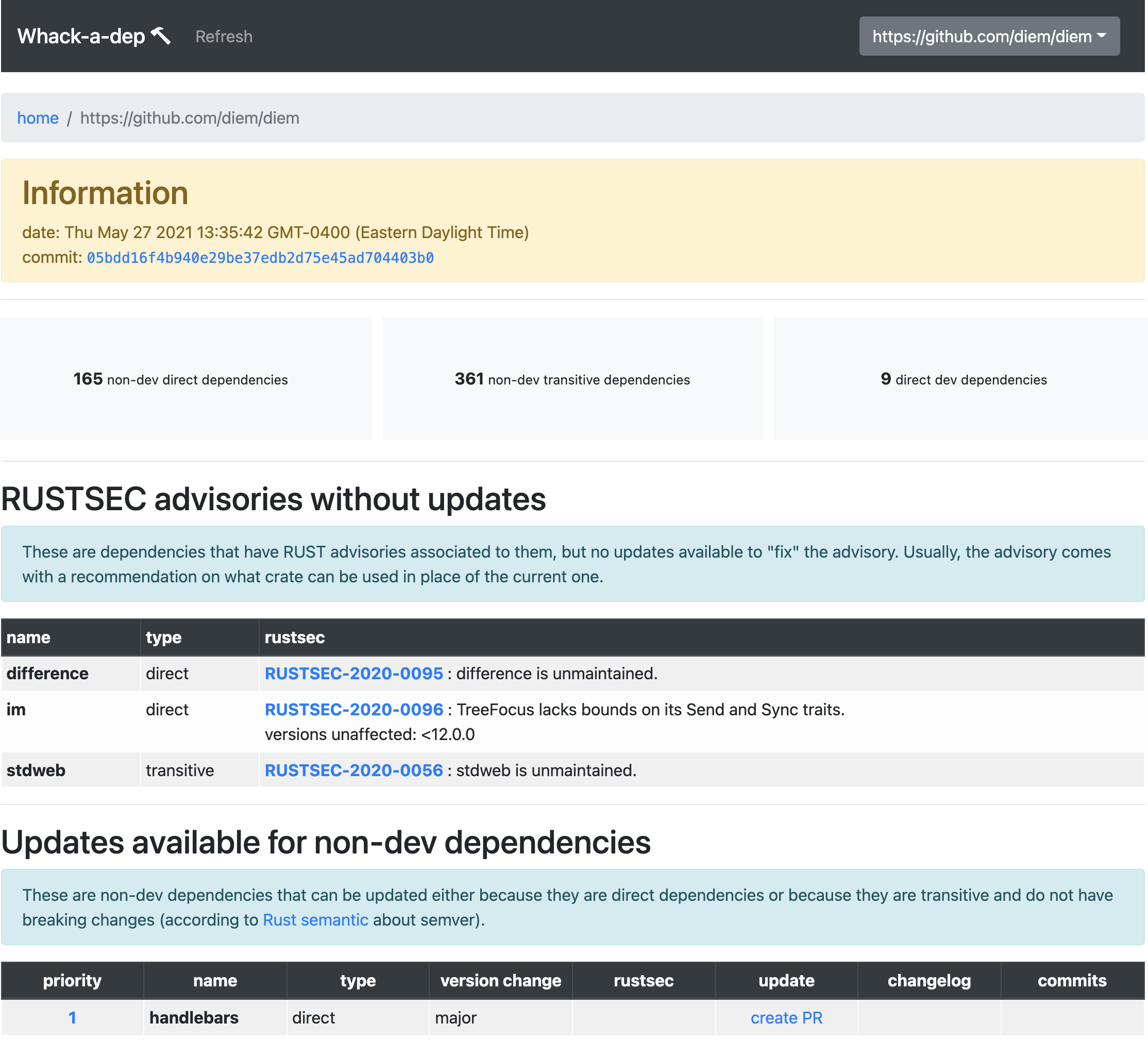
To tackle 1, John and I created whackadep. Whackadep is a service, with a web UI, that monitors your repository. Originally architected to be language-agnostic, it was for obvious reasons built primarily for Rust codebases.
Whackadep's role was to periodically check if new updates were available, and to quickly show you two things:
what was the risk of not updating
what was the risk of updating
The risk of not updating is generally calculated via the help of RUSTSEC, the RustSec Advisory Database, as well as a calculation of the difference between the semantic versions. If the update is X breaking versions on top of your version, then it'll be harder to update if they're a serious bug that needs urgent fixing. All of this was taken into account to calculate a priority score that would help a human user figure out what to do.
The risk of updating was calculated from a few heuristics, but was meant to be extendable. The presence of an updated build.rs file, for example, was a big red flag. The presence of a new, never-seen-before, contributor in a release was also seen as a red flag. A number of these customizable heuristics would be used to calculate a risk score, which could be used by the user of the tool to decide if that warranted a human review.
Of course, in Rust-land, you get dependency updates every single day. So you need more reassurance that a review is not needed. For this, we came up with the idea of a trusted set of libraries. As Linus said one day (although I can't find that quote anymore): security works via a network, and if you don't do security via a network you're dumb. He said it sort of like that I believe. The idea is that you can't do everything yourself, and the only way to scale is to trust others. Thus, by whitelisting a number of libraries as being part of a club of well-maintained libraries with well-known authors, we could reduce the burden of reviewing dependencies.
Anyway, the whole point of this article is to show you that dependencies are a huge problem in most software stacks, and that solutions don't really exist to deal with this. Human processes are doomed to fail, and thus you need an automated and machine-built component to help you there. Interestingly, I just finished reading Zero to One a few days ago, and in the book Peter Thiel makes the point that machines shouldn't try to replace humans but instead provide services to help make them superheroes. This is what whackadep was aiming to do: give developers super powers. I hope I inspired some of you to continue pursuing this idea, because we're going to need some help.
Zkapps (formerly known as snapps) are zero-knowledge smart contracts that will launch on Mina this year. You can learn more about them here. This tutorial teaches you how to write a tic-tac-toe game using snarkyjs, the official library to write zkapps on Mina.
Set up
You can quickly create a project by using the Snapp CLI:
A zero-knowledge smart contract, or zkapp, is very close in concept to the ones you see on Ethereum:
it has a state
it has a constructor that initializes the initial state when you deploy your zkapp
and it has methods that can mutate the state
Let's start with the state.
A state for a tic-tac-toe
Zkapps, at the lowest level, only understand field elements, of type Field. Field is a type similar to Ethereum's u256 except that it is a bit smaller. Essentially it's a number between 0 and 28948022309329048855892746252171976963363056481941560715954676764349967630336. Every other type has to be derived from Field, and we provide a number of such helpful types in snarky. (You can also create your own types but we won't use that here.)
First, a tic-tac-toe game needs to track the state of the game. The board.
The state of a zkapp can only hold 8 field elements. This is not set in stone, but the more storage a zkapp can contain, and the harder it becomes to participate in consensus (and thus the less decentralized the network becomes). Zkapps that need to handle large state can do so via Merkle trees, but I won't be talking about that here.
A tic-tac-toe board is made of 9 tiles, that's one too many :( so what can we do about it? Well as I said, a field element is a pretty big number, so let's just encode our board into one:
class TicTacToe extends SmartContract {
// The board is serialized as a single field element
@state(Field) board: State<Field>;
}
We'll also need to keep track of who's turn is it, and if the game is finished (someone has won):
class TicTacToe extends SmartContract {
// The board is serialized as a single field element
@state(Field) board: State<Field>;
// false -> player 1 | true -> player 2
@state(Bool) nextPlayer: State<Bool>;
// defaults to false, set to true when a player wins
@state(Bool) gameDone: State<Bool>;
// player 1's public key
player1: PublicKey;
// player 2's public key
player2: PublicKey;
}
Notice that the public keys of the players are not decorated with @state. This is because we don't need to store that information on chain, we can simply hardcode it in the zkapp. If you wanted to be able to start a new game with new players, you would store these on chain so that you could mutate them via a method of the zkapp. But we're keeping it simple.
Also, PublicKey and Bool are two types provided by the standard library and built on top of Field. Bool is built on top of a single field element, so in total our on-chain state has 3 field elements. That'll work!
A constructor
Next, we must initialize that state in a constructor. let's look at the code:
class TicTacToe extends SmartContract {
// The board is serialized as a single field element
@state(Field) board: State<Field>;
// false -> player 1 | true -> player 2
@state(Bool) nextPlayer: State<Bool>;
// defaults to false, set to true when a player wins
@state(Bool) gameDone: State<Bool>;
// player 1's public key
player1: PublicKey;
// player 2's public key
player2: PublicKey;
// initialization
constructor(
initialBalance: UInt64,
address: PublicKey,
player1: PublicKey,
player2: PublicKey
) {
super(address);
this.balance.addInPlace(initialBalance);
this.board = State.init(Field.zero);
this.nextPlayer = State.init(new Bool(false)); // player 1 starts
this.gameDone = State.init(new Bool(false));
// set the public key of the players
this.player1 = player1;
this.player2 = player2;
}
}
The constructor does two things that might look weird. First, it takes an address as argument, this is the address where the zkapp will be deployed (this might disappear in future versions of snarky). Second, the constructor takes an initialBalance, which might be needed to pay the account creation fee (if you haven't already). The rest should be pretty straight forward.
Adding methods to the zkapp
We really only need one method: a method to play. We can create one with the @method decorator:
The method takes the player's public key, two coordinates, and a signature (to make sure that they own the public key) over the coordinates.
The board can be visualized as such:
The logic, at a high-level
Let's look at the logic that we will have to implement:
class TicTacToe extends SmartContract {
// ...
@method async play(
pubkey: PublicKey,
signature: Signature,
x: Field,
y: Field
) {
// 1. if the game is already finished, abort.
// 2. ensure that we know the private key associated to the public key
// and that our public key is known to the zkapp
// 3. Make sure that it's our turn,
// and set the state for the next player
// 4. get and deserialize the board
// 5. update the board (and the state) with our move
// 6. did I just win? If so, update the state as well
}
Does that make sense? In the rest of this tutorial I go over every step
Step 1: Game over is game over
if the game is already finished, abort.
To do this, we have to read the state of the zkapp with get. When you execute the program locally, this will go and fetch the state of the zkapp from the blockchain (hence the asynchronous call with await). Your execution will then only be deemed valid by the network if they see the same state (in this case the value of gameDone) on their side.
Using assert functions like [assertEquals()] is the natural way to abort the program if it takes the wrong path. Under the hood, what happens is that the prover won't be able to satisfy the circuit and create a proof if the assert is triggered.
Step 2: Access control
ensure that we know the private key associated to the public key and that our public key is known to the zkapp
First, let's verify that the public key is one of the hardcoded key:
Make sure that it's our turn, and set the state for the next player
Earlier, we encoded a player as a boolean, with false describing the first player and true the second one. So let's derive this first.
In zero-knowledge proofs, we can't have branches with too much logic. The program pretty much always has to do the same thing. That being said, what we can do is to assign a different value to a variable depending on a condition. For example, this is how we can get the boolean that describes us as a player:
// get player token
const player = Circuit.if(
pubkey.equals(this.player1),
new Bool(false),
new Bool(true)
);
Circuit.if() takes three arguments, the first one is a condition that must be a Bool type, the other two are the returned values depending on if the condition is true or false.
Now that we have the player value, we can use it to check if it our turn:
// ensure its their turn
const nextPlayer = await this.nextPlayer.get();
nextPlayer.assertEquals(player);
And we can update the state for the next player via the set() function:
// set the next player
this.nextPlayer.set(player.not());
Step 4: fitting a board in a field element
get and deserialize the board
There's many strategies here, but a simple one is to deserialize the field element into bits (via toBits()) and interpret these bits as the board.
Yet, this is not enough. A bit can only represent two states, and we have three: empty, false (player 1), true (player 2).
So we'll use two lists of size 9 instead:
one to track who played on that tile
and one to track if a tile is empty or not
As you can see, it is important to track if a tile is empty or not, because in the first list 0 represents both the empty tile and a move from the player 1.
const serialized_board = await this.board.get();
const bits = serialized_board.toBits(9 * 2);
const bits_not_empty = bits.slice(0, 9);
const bits_player = bits.slice(9, 18);
let board = [];
for (let i = 0; i < 3; i++) {
let row = [];
for (let j = 0; j < 3; j++) {
const not_empty = bits_not_empty[i * 3 + j];
const player = bits_player[i * 3 + j];
row.push([not_empty, player]);
}
board.push(row);
}
To make the rest of the logic easier to read, I'm going to use the Optional type to encode the [not_empty, player] array. It looks like this:
class Optional<T> {
isSome: Bool;
value: T;
// ...
}
It is simply a Bool that describes if it's empty (no one has played that tile yet), and if it's not empty the value associated with it (a cross or a circle, encoded as the playerBool).
Here's what the full deserialization code looks like:
Now here comes the trickiest part. Zero-knowledge smart contracts have some constraints: they don't allow you to dynamically index into an array, so you can't do this:
board[x][y].isSome = new Bool(true);
board[x][y].value = player;
instead, you have to go through every tile, and check if it's the one to update. (Note that you can't have dynamic for loops as well, they need to be of constant size).
for (let i = 0; i < 3; i++) {
for (let j = 0; j < 3; j++) {
// is this the cell the player wants to play?
const to_update = Circuit.if(
x.equals(new Field(i)).and(y.equals(new Field(j))),
new Bool(true),
new Bool(false)
);
}
}
And you can use the same tricks to make sure you can play on the tile, and to update the board:
for (let i = 0; i < 3; i++) {
for (let j = 0; j < 3; j++) {
// is this the cell the player wants to play?
const to_update = Circuit.if(
x.equals(new Field(i)).and(y.equals(new Field(j))),
new Bool(true),
new Bool(false)
);
// make sure we can play there
Circuit.if(
to_update,
board[i][j].isSome,
new Bool(false)
).assertEquals(false);
// copy the board (or update)
board[i][j] = Circuit.if(
to_update,
new Optional(new Bool(true), player),
board[i][j]
);
}
}
Finally, we can serialize and store this update into the zkapp's state:
// serialize
let not_empty = [];
let player = [];
for (let i = 0; i < 3; i++) {
for (let j = 0; j < 3; j++) {
not_empty.push(this.board[i][j].isSome);
player.push(this.board[i][j].value);
}
}
const new_board = Field.ofBits(not_empty.concat(player));
// update state
this.board.set(new_board);
Step 6: Did I just win?
did I just win? If so, update the state as well
Finally, we can check if someone won by checking all rows, columns, and diagonals. This part is a bit tedious and boring, so here's the code:
let won = new Bool(false);
// check rows
for (let i = 0; i < 3; i++) {
let row = this.board[i][0].isSome;
row = row.and(this.board[i][1].isSome);
row = row.and(this.board[i][2].isSome);
row = row.and(this.board[i][0].value.equals(this.board[i][1].value));
row = row.and(this.board[i][1].value.equals(this.board[i][2].value));
won = won.or(row);
}
// check cols
for (let i = 0; i < 3; i++) {
let col = this.board[0][i].isSome;
col = col.and(this.board[1][i].isSome);
col = col.and(this.board[2][i].isSome);
col = col.and(this.board[0][i].value.equals(this.board[1][i].value));
col = col.and(this.board[1][i].value.equals(this.board[2][i].value));
won = won.or(col);
}
// check diagonals
let diag1 = this.board[0][0].isSome;
diag1 = diag1.and(this.board[1][1].isSome);
diag1 = diag1.and(this.board[2][2].isSome);
diag1 = diag1.and(this.board[0][0].value.equals(this.board[1][1].value));
diag1 = diag1.and(this.board[1][1].value.equals(this.board[2][2].value));
won = won.or(diag1);
let diag2 = this.board[0][2].isSome;
diag2 = diag2.and(this.board[1][1].isSome);
diag2 = diag2.and(this.board[0][2].isSome);
diag2 = diag2.and(this.board[0][2].value.equals(this.board[1][1].value));
diag2 = diag2.and(this.board[1][1].value.equals(this.board[2][0].value));
won = won.or(diag2);
// update the state
this.gameDone.set(won);
The full code is available here if you want to play with it.
Moxie just wrote his first impressions on web3. If you've been wondering about web3, and want a non-bullshit and technical glance at what it is, I think this is a really good post.
While I do agree with his critics, I don't share his skepticism. Let's look at his description of how most users interact with decentralized apps (dapps):
For example, whether it’s running on mobile or the web, a dApp like Autonomous Art or First Derivative needs to interact with the blockchain somehow – in order to modify or render state (the collectively produced work of art, the edit history for it, the NFT derivatives, etc). That’s not really possible to do from the client, though, since the blockchain can’t live on your mobile device (or in your desktop browser realistically). So the only alternative is to interact with the blockchain via a node that’s running remotely on a server somewhere.
A server! But, as we know, people don’t want to run their own servers. As it happens, companies have emerged that sell API access to an ethereum node they run as a service, along with providing analytics, enhanced APIs they’ve built on top of the default ethereum APIs, and access to historical transactions. Which sounds… familiar. At this point, there are basically two companies. Almost all dApps use either Infura or Alchemy in order to interact with the blockchain. In fact, even when you connect a wallet like MetaMask to a dApp, and the dApp interacts with the blockchain via your wallet, MetaMask is just making calls to Infura!
This is a real problem. To interact with the blockchain, you need to download its whole history with a program. This takes a lot of time (sometimes days) and space. This is not realistic for most users, and even less so for mobile users. The solution has been to just trust a public node. Infura is one of them and has become quite "trusted" through being the backend behind Metamask, the most popular Ethereum wallet. This service can lie to you, and you wouldn't notice. As such, the whole security of the blockchain is moot once you start interacting through a public node.
“It’s early days still” is the most common refrain I see from people in the web3 space when discussing matters like these. In some ways, cryptocurrency’s failure to scale beyond relatively nascent engineering is what makes it possible to consider the days “early,” since objectively it has already been a decade or more.
Did you know that most of the web was not encrypted until recently? For example, Facebook defaulted to https in 2013. Not even a decade ago. Cryptocurrencies have come a long way since the advent of Bitcoin, and research has exploded in all directions. It is early days.
Now, what are the actual solutions that exist in the space?
First, newer byzantine-fault tolerant (BFT) consensus protocols have straight-forward solutions to this problem. Since each block is cryptographically certified by consensus participants, and no re-organization (or forks) can happen, the certification can be reused to provide a proof to the clients (the real ones). As such, Infura could very well give you this cryptographic proof to accompany a response to your request, and the problem would be fixed. This is what Celo is doing with Plumo, but more generally any blockchain that uses a BFT consensus (Diem/Libra, Cosmos, Algorand, Dfinity, etc.) should be able to implement something like this.
The security guarantee is not as high as verifying every block since the beginning of time (the genesis). (For this, cryptocurrencies like Mina have proposed recursive zero-knowledge proofs solutions that attest to all the state transition since genesis.) Plumo calls this ultra-light clients:
We observe that in order to verify the latest block header in BFT networks a client only needs the public keys of the current committee. As long as no committee has had a dishonest supermajority, a client who verifies a chain of committee hand-off messages certifying the PoS election results, known as epoch messages, does not need to check each block or even the headers of each block. Instead, to make (or verify a recent) transaction, the client simply asks for the latest (or otherwise relevant) block header, and verifies that it has been signed by a supermajority of the current committee. This constitutes the simplifying assumption (SA) and light client protocol proved by Plumo.
Another issue is key rotations, which increase the size of the proof (as you need to give proofs to all the key rotations before you can give a proof to the latest state of the chain), but I believe that zero-knowledge proofs can fix that as well.
Bottom line: it's actually not that grim, solutions are there, but users have to care for people to implement them, apply them, and for the solutions to receive adoption. OK, this is pretty much what Moxie says:
However, even if this is just the beginning (and it very well might be!), I’m not sure we should consider that any consolation. I think the opposite might be true; it seems like we should take notice that from the very beginning, these technologies immediately tended towards centralization through platforms in order for them to be realized, that this has ~zero negatively felt effect on the velocity of the ecosystem, and that most participants don’t even know or care it’s happening. This might suggest that decentralization itself is not actually of immediate practical or pressing importance to the majority of people downstream, that the only amount of decentralization people want is the minimum amount required for something to exist, and that if not very consciously accounted for, these forces will push us further from rather than closer to the ideal outcome as the days become less early.
But this is not counting on Infura getting hacked. And it will get hacked.