Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
You want to teach someone about a crypto concept, something 101 that could be explained in 1-2 pages with a lot of diagrams? Look no more, we need you.
Concept
The idea is to have a recurrent benevolent e-magazine (like POC||GTFO) that focuses on:
cryptography: duh! That being said, cryptography does include: implementations, cryptocurrencies, protocols, at scale, politics, etc. so there are more topics that we deem interesting than just theoretical cryptography.
pedagogy: heaps of diagrams and a focus on teaching. Taking an original writing style is a plus. We're looking not to bore readers.
101: we're looking for introductions to concepts, not deeply technical articles that require a lot of initial knowledge to grasp.
short: articles should be similar to a blog post, not a full-fledged paper. With that in mind articles should be around 1, 2 or 3 pages. We are not looking for something dense though, so no posters, rather a submission should be a light read that can be part of a series or influence the reader to read more about the topic.
Topics
Preferably, authors should write about something they are familiar with, but here is a list of topics that would likely be interesting for such a light magazine:
what is SSH?
what is SHA-3?
what is functional encryption?
what is TLS 1.3?
what is a linear differential attack?
what is a cache attack?
how does LLL work?
what are common crypto implementation tricks?
what is R-LWE?
what is a hash-based signature?
what is an RFC?
what is the IETF?
what is the IACR?
why are companies encrypting databases?
what is x509, .pem, asn.1 and base64?
etc...
Format
LaTeX if possible.
Deadline
No deadline at the moment.
How to submit
send me a dropbox link or something on the contact page, you can also send it to me via twitter
PS: I am going to annoy you if you don't use diagrams in your article
I will be at the Tamuro meetup in London tonight (at the George Inn pub). It's a meetup about security and cryptography. Feel free to join if you want to grab a beer and talk about supersingular isogenies.
I'm giving a talk about smart contract security at the IT Camp conference of Cluj Napoca, Romania on Thursday.
If anyone is there and wants to talk about crypto while drinking beer, contact me!
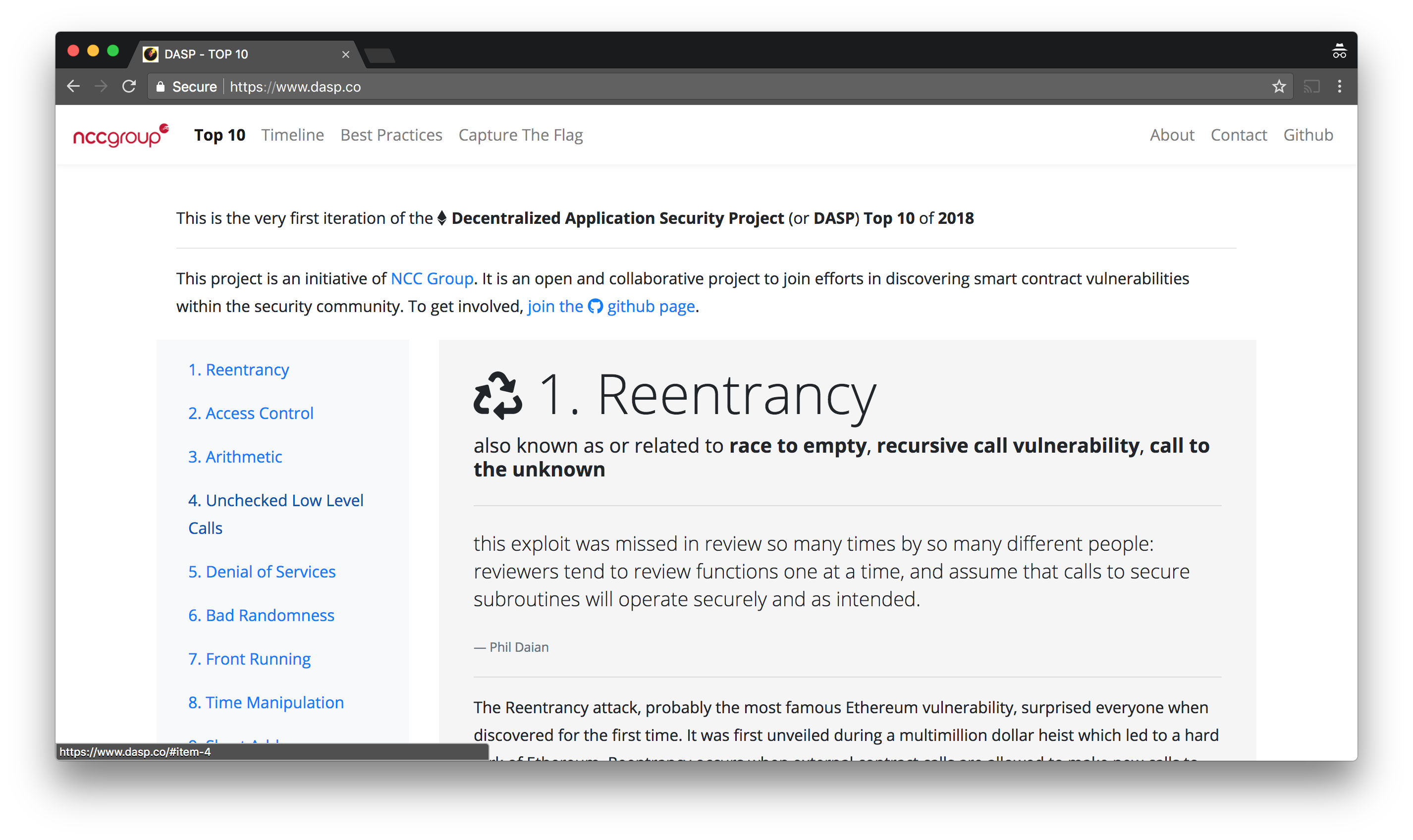
Last month I was in Singapore with Mason to talk about vulnerabilities in Ethereum smart contracts at Black Hat Asia. As part of the talk we released the DASP, a top 10 of the most damaging or surprising security vulnerabilities that we have observed in the wild or in private during audits we perform as part of our jobs.
The page is on github as well and we welcome contributions to the top 10 and the list of known exploits. In addition we're looking to host more projects related to the Ethereum space there, if you are looking for research projects or are looking to contribute on tools or anything that can make smart contracts development more secure, file an issue on github!
Note that I will be giving the talk again at IT Camp in Cluj-Napoca in a few months.
They make it seem really worrisome, but should we really be scared about the findings?
Traceable delivery is the first thing that came up in the presentation. What is it? It’s the check marks that appear when your recipient receives a message you sent. It's mostly a UI feature but the fact that no security is tied to it allows a server to fake them while dropping messages, making you think that your recipient has wrongly received the message. This was never a security feature to begin with, and nobody never claimed it was one.
Closeness is the fact that the WhatsApp servers can add a new participant into your private group chat without your consent (assuming you’re the admin). This could lead people to share messages to the group including to a rogue participant. The caveat is that:
previous messages cannot be decrypted by the newcomer because a new key is generated when someone new joins the mix
everybody is receiving a notification that somebody joined, at this point everyone can choose to willingly send messages to the group
Again, I do not see this as a security vulnerability. Maybe because I’ve understood how group chats can work (or miswork) from growing up with shady websites and applications. But I see this more as a UI/UX problem.
The paper is not bad though, and I think they’re right to point out these issues. Actually, they do something very interesting in it, they start it up with a nice security model that they use to analyse several messaging applications:
Intuitively, a secure group communication protocol should provide a level of security comparable to when a group of people communicates in an isolated room: everyone in the room hears the communication (traceable delivery), everyone knows who spoke (authenticity) and how often words have been said (no duplication), nobody outside the room can either speak into the room (no creation) or hear the communication inside (confidentiality), and the door to the room is only opened for invited persons (closeness).
Following this security model, you could rightfully think that we haven’t reached the best state in secure messaging. But the fuss about it could also wrongfully make you think that these are worrisome attacks that need to be dealt with.
To me, this article reads as a better example of the problems with the security industry and the way security research is done today, because I think the lesson to anyone watching is clear: don't build security into your products, because that makes you a target for researchers, even if you make the right decisions, and regardless of whether their research is practically important or not.
I'd say the problem is in the reaction, not in the published analysis. But it's a sad reaction indeed.