Plaid, The biggest CTF Team, was organizing a Capture The Flag contest last week. There were two crypto challenges that I found interesting, here is the write-up of the second one:
You are given a file with a bunch of triplets:
{N : e : c}
and the hint was that they were all encrypting the same message using RSA. You could also easily see that N was the same modulus everytime.
The trick here is to find two public exponent \( e \) which are coprime: \( gcd(e_1, e_2) = 1 \)
This way, with Bézout's identity you can find \( u \) and \( v \) such that: \(u \cdot e_1 + v \cdot e_2 = 1 \)
So, here's a little sage script to find the right public exponents in the triplets:
for index, triplet in enumerate(truc[:-1]):
for index2, triplet2 in enumerate(truc[index+1:]):
if gcd(triplet[1], triplet2[1]) == 1:
a = index
b = index2
c = xgcd(triplet[1], triplet2[1])
break
Now that have found our \( e_1 \) and \( e_2 \) we can do this:
\[ c_1^{u} * c_2^{v} \pmod{N} \]
And hidden underneath this calculus something interesting should happen:
\[ (m^{e_1})^u * (m^{e_2})^u \pmod{N} \]
\[ = m^{u \cdot e_1 + v \cdot e_2} \pmod{N} \]
\[ = m \pmod{N} \]
And since \( m < N \) we have our solution :)
Here's the code in Sage:
m = Mod(power_mod(e_1, u, N) * power_mod(e_2, v, N), N)
And after the crypto part, we still have to deal with the presentation part:
hex_string = "%x" % m
import binascii
binascii.unhexlify(hex_string)
Tadaaa!! And thanks @spdevlin for pointing me in the right direction :)
RFC
So, RFC means Request For Comments and they are a bunch of text files that describe different protocols. If you want to understand how SSL, TLS (the new SSL) and x509 certificates (the certificates used for SSL and TLS) all work, for example you want to code your own OpenSSL, then you will have to read the corresponding RFC for TLS: rfc5280 for x509 certificates and rfc5246 for the last version of TLS (1.2).

x509
x509 is the name for certificates which are defined for:
informal internet electronic mail, IPsec, and WWW applications
There used to be a version 1, and then a version 2. But now we use the version 3. Reading the corresponding RFC you will be able to read such structures:
Certificate ::= SEQUENCE {
tbsCertificate TBSCertificate,
signatureAlgorithm AlgorithmIdentifier,
signatureValue BIT STRING }
those are ASN.1 structures. This is actually what a certificate should look like, it's a SEQUENCE of objects.
- The first object contains everything of interest that will be signed, that's why we call it a To Be Signed Certificate
- The second object contains the type of signature the CA used to sign this certificate (ex: sha256)
- The last object is not an object, its just some bits that correspond to the signature of the TBSCertificate after it has been encoded with DER
ASN.1
It looks small, but each object has some depth to it.
The TBSCertificate is the biggest one, containing a bunch of information about the client, the CA, the publickey of the client, etc...
TBSCertificate ::= SEQUENCE {
version [0] EXPLICIT Version DEFAULT v1,
serialNumber CertificateSerialNumber,
signature AlgorithmIdentifier,
issuer Name,
validity Validity,
subject Name,
subjectPublicKeyInfo SubjectPublicKeyInfo,
issuerUniqueID [1] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version MUST be v2 or v3
subjectUniqueID [2] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version MUST be v2 or v3
extensions [3] EXPLICIT Extensions OPTIONAL
-- If present, version MUST be v3
}
DER
A certificate is of course not sent like this. We use DER to encode this in a binary format.
Every fieldname is ignored, meaning that if we don't know how the certificate was formed, it will be impossible for us to understand what each value means.
Every value is encoded as a TLV triplet: [TAG, LENGTH, VALUE]
For example you can check the GITHUB certificate here
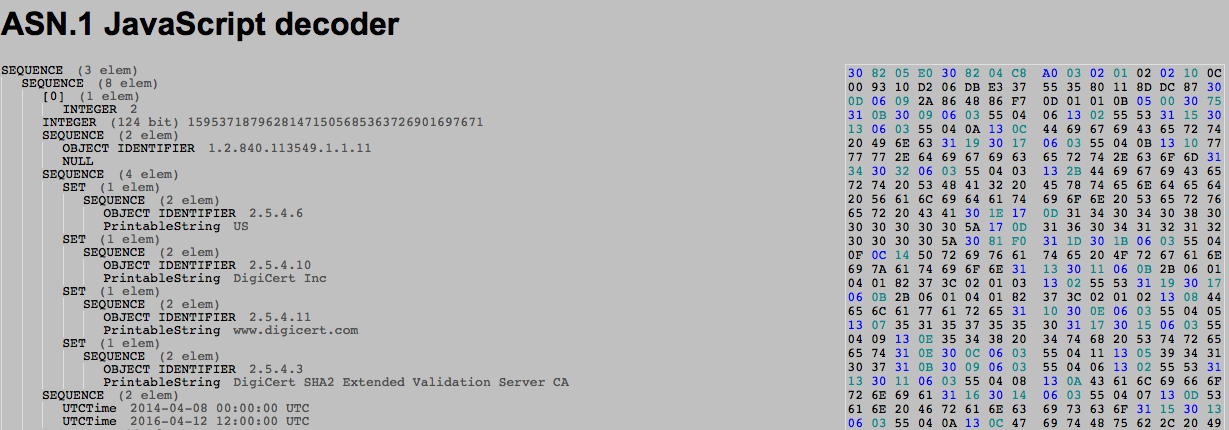
On the right is the hexdump of the DER encoded certificate, on the left is its translation in ASN.1 format.
As you can see, without the RFC near by we don't really know what each value corresponds to. For completeness here's the same certificate parsed by openssl x509 command tool:
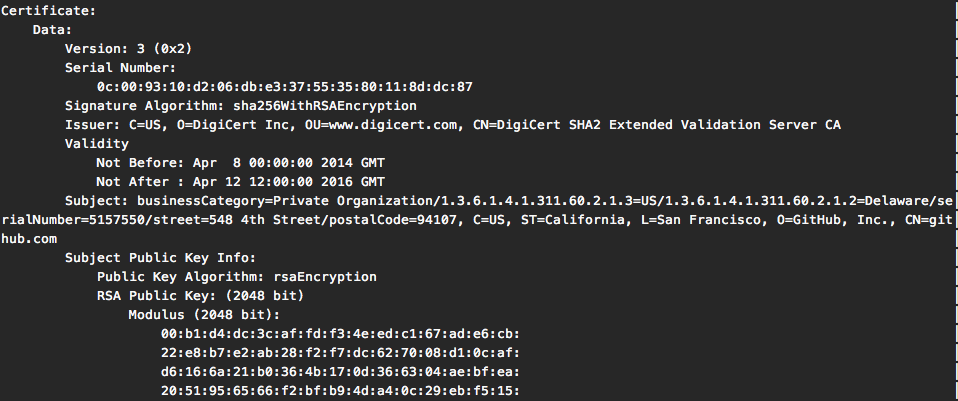
How to read the DER encoded certificate
So go back and check the hexdump of the GITHUB certificate, here is the beginning:
30 82 05 E0 30 82 04 C8 A0 03 02 01 02
As we saw in the RFC for x509 certificates, we start with a SEQUENCE.
Certificate ::= SEQUENCE {
Microsoft made a documentation that explains pretty well how each ASN.1 TAG is encoded in DER, here's the page on SEQUENCE
30 82 05 E0
So 30 means SEQUENCE. Since we have a huge sequence (more than 127 bytes) we can't code the length on the one byte that follows:
If it is more than 127 bytes, bit 7 of the Length field is set to 1 and bits 6 through 0 specify the number of additional bytes used to identify the content length.
(in their documentation the least significant bit on the far right is bit zero)
So the following byte 82, converted in binary: 1000 0010, tells us that the length of the SEQUENCE will be written in the following 2 bytes 05 E0 (1504 bytes)
We can keep reading:
30 82 04 C8 A0 03 02 01 02
Another Sequence embedded in the first one, the TBSCertificate SEQUENCE
TBSCertificate ::= SEQUENCE {
version [0] EXPLICIT Version DEFAULT v1,
The first value should be the version of the certificate:
A0 03
Now this is a different kind of TAG, there are 4 classes of TAGs in ASN.1: UNIVERSAL, APPICATION, PRIVATE, and context-specific. Most of what we use are UNIVERSAL tags, they can be understood by any application that knows ASN.1. The A0 is the [0] (and the following 03 is the length). [0] is a context specific TAG and is used as an index when you have a series of object. The github certificate is a good example of this, because you can see that the next index used is [3] the extensions object:
TBSCertificate ::= SEQUENCE {
version [0] EXPLICIT Version DEFAULT v1,
serialNumber CertificateSerialNumber,
signature AlgorithmIdentifier,
issuer Name,
validity Validity,
subject Name,
subjectPublicKeyInfo SubjectPublicKeyInfo,
issuerUniqueID [1] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version MUST be v2 or v3
subjectUniqueID [2] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version MUST be v2 or v3
extensions [3] EXPLICIT Extensions OPTIONAL
-- If present, version MUST be v3
}
Since those obects are all optionals, skipping some without properly indexing them would have caused trouble parsing the certificate.
Following next is:
02 01 02
Here's how it reads:
_______ tag: integer
| ____ length: 1 byte
| | _ value: 2
| | |
| | |
v v v
02 01 02
The rest is pretty straight forward except for IOD: Object Identifier.
Object Identifiers
They are basically strings of integers that reads from left to right like a tree.
So in our Github's cert example, we can see the first IOD is 1.2.840.113549.1.1.11 and it is supposed to represent the signature algorithm.
So go to http://www.alvestrand.no/objectid/top.html and click on 1, and then 1.2, and then 1.2.840, etc... until you get down to the latest branch of our tree and you will end up on sha256WithRSAEncryption.
Here's a more detailed explanation on IOD and here's the microsoft doc on how to encode IOD in DER.
I was really confused about all those acronyms when I started digging into OpenSSL and RFCs. So here's a no bullshit quick intro to them.
PKCS#7
Or Public-Key Crypto Standard number 7. It's just a guideline, set of rules, on how to send messages, sign messages, etc... There are a bunch of PKCS that tells you exactly how to do stuff using crypto. PKCS#7 is the one who tells you how to sign and encrypt messages using certificates.
If you ever see "pkcs#7 padding", it just refers to the padding explained in pkcs#7.
X509
In a lot of things in the world (I'm being very vague), we use certificates. For example each person can have a certificate, and each person's certificate can be signed by the government certificate. So if you want to verify that this person is really the person he pretends to be, you can check his certificate and check if the government signature on his certificate is valid.
TLS use x509 certificates to authenticate servers. If you go on https://www.facebook.com, you will first check their certificate, see who signed it, checked the signer's certificate, and on and on until you end up with a certificate you can trust. And then! And only then, you will encrypt your session.
So x509 certificates are just objects with the name of the server, the name of who signed his certificate, the signature, etc...
Example from wikipedia:
Certificate
Version
Serial Number
Algorithm ID
Issuer
Validity
Not Before
Not After
Subject
Subject Public Key Info
Public Key Algorithm
Subject Public Key
Issuer Unique Identifier (optional)
Subject Unique Identifier (optional)
Extensions (optional)
...
Certificate Signature Algorithm
Certificate Signature
ASN.1
So, how should we write our certificate in a computer format? There are a billion ways of formating a document and if we don't agree on one then we will never be able to ask a computer to parse a x509 certificate.
That's what ASN.1 is for, it tells you exactly how you should write your object/certificate
DER
ASN.1 defines the abstract syntax of information but does not restrict the way the information is encoded. Various ASN.1 encoding rules provide the transfer syntax (a concrete representation) of the data values whose abstract syntax is described in ASN.1.
Now to encode our ASN.1 object we can use a bunch of different encodings specified in ASN.1, the most common one being used in TLS is DER
DER is a TLV kind of encoding, meaning you first write the Tag (for example, "serial number"), and then the Length of the following value, and then the Value (in our example, the serial number).
DER is also more than that:
DER is intended for situations when a unique encoding is needed, such as in cryptography, and ensures that a data structure that needs to be digitally signed produces a unique serialized representation.
So there is only one way to write a DER document, you can't re-order the elements.
And a made up example for an ASN.1 object:
OPERATION ::= CLASS
{
&operationCode INTEGER UNIQUE,
&InvocationParsType,
&ResponseParsAndResultType,
&ExceptionList ERROR OPTIONAL
}
And its DER encoding:
0110 0111 0010 110...
Base64
Base64 is just a way of writing binary data in a string, so you can pass it to someone on facebook messenger for exemple
From the openssl Wiki:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
0000000000111111111122222222223333333333444444444455555555556666
0123456789012345678901234567890123456789012345678901234567890123
And if you see any equal sign =, it's for padding.
So if the first 6 bits of your file is '01' in base 10, then you will write that as B in plaintext. See an example if you still have no idea about what I'm talking about.
PEM
A pem file is just two comments (that are very important) and the data in base64 in the middle. For example the pem file of an encrypted private key:
-----BEGIN ENCRYPTED PRIVATE KEY-----
MIIFDjBABgkqhkiG9w0BBQ0wMzAbBgkqhkiG9w0BBQwwDgQIS2qgprFqPxECAggA
MBQGCCqGSIb3DQMHBAgD1kGN4ZslJgSCBMi1xk9jhlPxP3FyaMIUq8QmckXCs3Sa
9g73NQbtqZwI+9X5OhpSg/2ALxlCCjbqvzgSu8gfFZ4yo+Xd8VucZDmDSpzZGDod
X0R+meOaudPTBxoSgCCM51poFgaqt4l6VlTN4FRpj+c/WZeoMM/BVXO+nayuIMyH
blK948UAda/bWVmZjXfY4Tztah0CuqlAldOQBzu8TwE7WDwo5S7lo5u0EXEoqCCq
H0ga/iLNvWYexG7FHLRiq5hTj0g9mUPEbeTXuPtOkTEb/0ckVE2iZH9l7g5edmUZ
GEs=
-----END ENCRYPTED PRIVATE KEY-----
And yes the number of - are important

