I'm using cmder on windows, it's pretty and it comes with a lot of unix tools (cat, ls, bash, ssh, more, grep...) and pipes and streams and... I can use vim in the console. Not emacs, vim. I do have emacs on windows but I don't think I can do a emacs -nw to just use it from the console. So let's go back to learn vim, because I hate being slow. And here is a nice way of doing it!
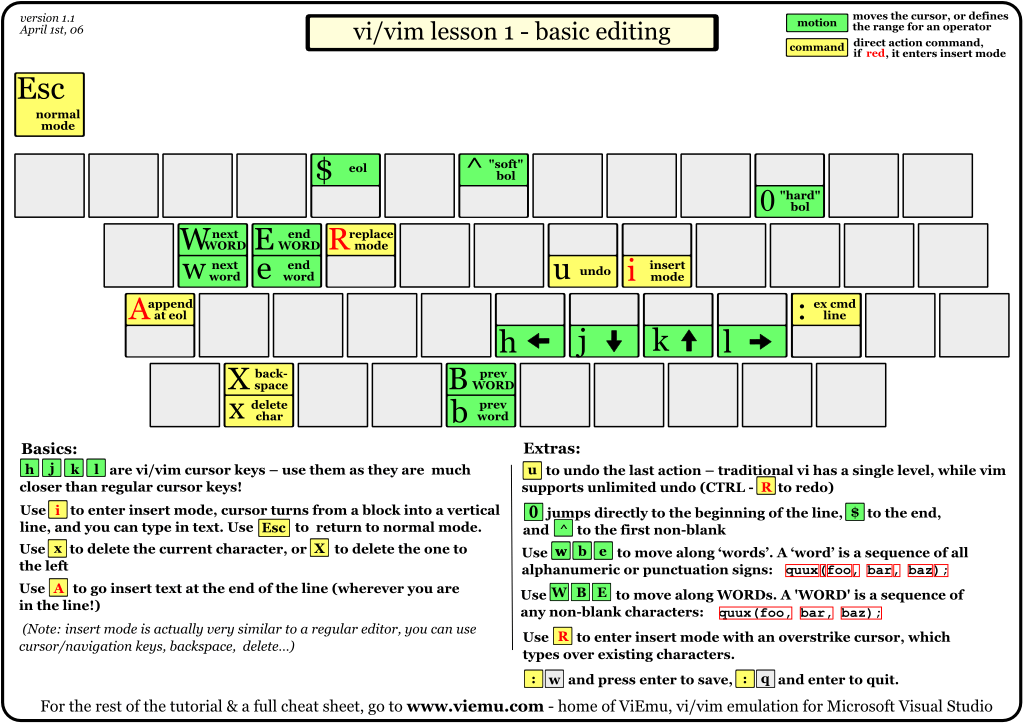
http://www.viemu.com/a_vi_vim_graphical_cheat_sheet_tutorial.html
you can find several pictures of a keyboard aiming at teaching you step by step how vim works. This is all I needed!
I'm digging into the code source of Sage and I see that a lot of functions are implemented with Shoup's NTL. There is also FLINT used. I was wondering what were the differences. I can see that NTL is in c++ and FLINT is in C. On wikipedia:
It is developed by William Hart of the University of Warwick and David Harvey of Harvard University to address the speed limitations of the Pari and NTL libraries.
Although in the code source of Sage I'm looking at they use FLINT by default and switch to NTL when the modulus is getting too large.
By the way, all of that is possible because Sage uses Cython, which allows it to use C in python. I really should learn that...
EDIT:
This implementation is generally slower than the FLINT implementation in :mod:~sage.rings.polynomial.polynomial_zmod_flint, so we use FLINT by default when the modulus is small enough; but NTL does not require that n be `int`-sized, so we use it as default when n is too large for FLINT.
So the reason behind it seems to be that NTL is better for large numbers.
Silk Road's trial just closed and I ran into this old (?) journal of Ross Ulbricht that contains quite a bunch of interesting passages. I think this will turn into a movie.
03/25/2013
server was ddosed, meaning someone knew the real IP. I assumed they obtained it by becoming a guard node. So, I migrated to a new server and set up private guard nodes. There was significant downtime and someone has mentioned that they discovered the IP via a leak from lighttpd.
03/28/2013
being blackmailed with user info. talking with large distributor (hell's angels).
03/29/2013
commissioned hit on blackmailer with angels
04/01/2013
got word that blackmailer was excuted
created file upload script
started to fix problem with bond refunds over 3 months old
04/02/2013
got death threat from someone (DeathFromAbove)
04/04/2013
withdrawals all caught up
made a sign error when fixing the bond refund bug, so several vendors had very negative accounts.
switched to direct connect for bitcoin instead of over ssh portforward
received visual confirmation of blackmailers execution
04/06/2013
gave angels go ahead to find tony7
04/08/2013
sent payment to angels for hit on tony76 and his 3 associates
04/21 - 04/30/2013
market and forums under sever DoS attack. Gave 10k btc ransom but attack continued.
05/04/2013
attacker agreed to stop if I give him the first $100k of revenue and $50k per week thereafter. He stopped, but there
appears to be another DoS attack still persisting
05/07/2013
paid $100k to attacker
05/22/2013
paid the attacker $50k
05/29/2013
rewrote orders page
paid attacker $50k weekly ransom
$2M was stolen from my mtgox account by DEA
09/19 - 09/25/2013
red got in a jam and needed $500k to get out. ultimately he convinced me to give it to him, but I got his ID first and
had cimon send harry, his new soldier of fortune, to vancouver to get $800k in cash to cover it. red has been mainly
out of communication, but i haven't lost hope. Atlantis shut down. I was messaged by one of their team who said they
shut down because of an FBI doc leaked to them detailing vulnerabilities in Tor.
09/30/2013
Had revelation about the need to eat well, get good sleep, and meditate so I can stay positive and productive.
All of this sounds so surreal. He is making a huge amount of money for sure. A million dollars doesn't seem much for him. He is constantly buying servers and he seems to be coding a lot. He also seem like a normal dude.
And here's a funny thread on who's Variety Jones
I was looking for a way to know what are the real differences between magma, sage and pari. I only worked with sage and pari (and by the way, pari was invented at my university!) but heard of magma from sage contributors.
From the sage website: The Sage-Pari-Magma ecosystem
The biggest difference between Sage and Magma is that Magma is closed source, not free, and difficult for users to extend. This means that most of Magma cannot be changed except by the core Magma developers, since Magma itself is well over two million lines of compiled C code, combined with about a half million lines of interpreted Magma code (that anybody can read and modify). In designing Sage, we carried over some of the excellent design ideas from Magma, such as the parent, element, category hierarchy.
Any mathematician who is serious about doing extensive computational work in algebraic number theory and arithmetic geometry is strongly urged to become familiar with all three systems, since they all have their pros and cons. Pari is sleek and small, Magma has much unique functionality for computations in arithmetic geometry, and Sage has a wide range of functionality in most areas of mathematics, a large developer community, and much unique new code.
I also noticed that Sage provides an interface to Shoup's NTL through ntl. functions. Good to know!
here's an entertaining piece about NSA backdoors through history: http://ethanheilman.tumblr.com/post/70646748808/a-brief-history-of-nsa-backdoors
1997 Lotus Notes: The NSA requested that Lotus weaken its cryptography so that the NSA could break documents and emails secured by Lotus notes. This Software was used by citizens, companies and governments worldwide.
I talked about this one here.
I shipped!
You can get the .xpi on the github repo.
Just open it with Firefox and no restart is needed! (Ctrl+O in firefox)
For now it's very basic. You will see this icon next to the close button:

Yes I know I should create a custom icon :D but I was too busy coding.
You will then see some basic statistics of the day.
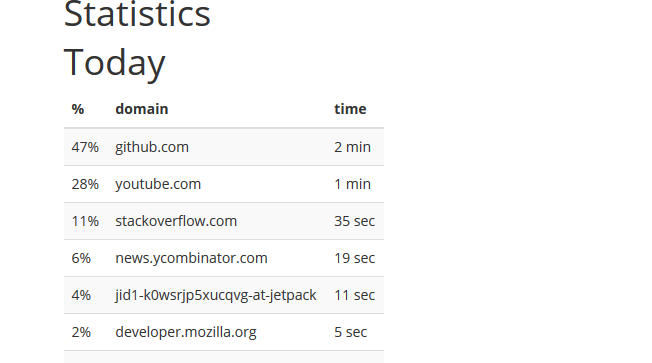
I'm now working on making this page nice with pretty graphics and more statistics (week, month, tracking of the most visited website of the week...).
So if you want to try my plugin, know that it works (so far)! And that you should pay this blog a visit because I'm planning on updating it.

A step by step tutorial showing you how to get admin credentials on a windows machine: http://imgur.com/gallery/H8obU
tl;dr:
- reboot in start-up repair mode
- read privacy statement of one menu should open notepad
- thanks to notepad replace
sethc 1 with cmd
- so now when you press 5 times on
shift it will call cmd instead of sethc 1
- you know have a shell, use command
net localgroup Administrators to get a list of the admins
- type
net user <ACCOUNT NAME HERE> * to change one account's password.
If you're looking for a "fix", microsoft advise you to turn off sticky keys all completely
And here's another exploit for windows 98
Note that as soon as you can access the hard drive, you don't need to use the first trick and can switch around programs in system32 as you wish (except if windows is encrypted with bitlocker). For example you can do this with an ubuntu live cd and swap cmd with the magnifier tool and you will be able to do the same thing.
I always thought I could reduce the amount of time slacking if I could track my time on facebook, reddit, hackernews... like I track my calories intake to reduce my weight. I couldn't find a good firefox plugin for that so I decided to make one.
I'm opensourcing the code right here: https://github.com/mimoo/FirefoxTimeTracker
I'm pretty surprised with Firefox SDK and it's actually easier than what I thought to build a browser plugin. It might also help that everything Mozilla documents is clear and pretty.
At the moment the code successfully logs the time passed on different websites across sessions. It just lacks nice graphs. If you want to try it just wait a couple days until I ship.


{kind=link}