Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
I introduced Plonk in a series of 12 videos here. That was almost a year and half ago! So I'm back with more :)
In this new series of videos I will explain how proof composition and recursion work with different schemes. Spoiler: we'll talk about Sangria, Nova, PCD, IVC, BCTV14 and Halo (and perhaps more if more comes up as I record these).
Three years ago, in the middle of writing my book Real-World Cryptography, I wrote about Why I'm writing a book on cryptography. I believed there was a market of engineers (and researchers) that was not served by the current offerings. There ought to be something more approachable, with less equations and theory and history, with more diagrams, and including advanced topics like cryptocurrencies, post-quantum cryptography, multi-party computations, zero-knowledge proof, hardware cryptography, end-to-end encrypted messaging, and so on.
The blogpost went viral and I ended up reusing it as a prologue to the book.
Now that Real-world cryptography has been released for more than a year, it turns out my 2-year bet was not for nothing :). The book has been very well received, including being used in a number of universities by professors, and has been selling quite well.
The only problem is that it mostly sold through Manning (my publisher), meaning that the book did not receive many reviews on Amazon.
So this is post is for you. If you've bought the book, and enjoyed it (or parts of it), please leave a review over there. This will go a long way to help me establish the book and allow more people to find it (Amazon being the biggest source of readers today).
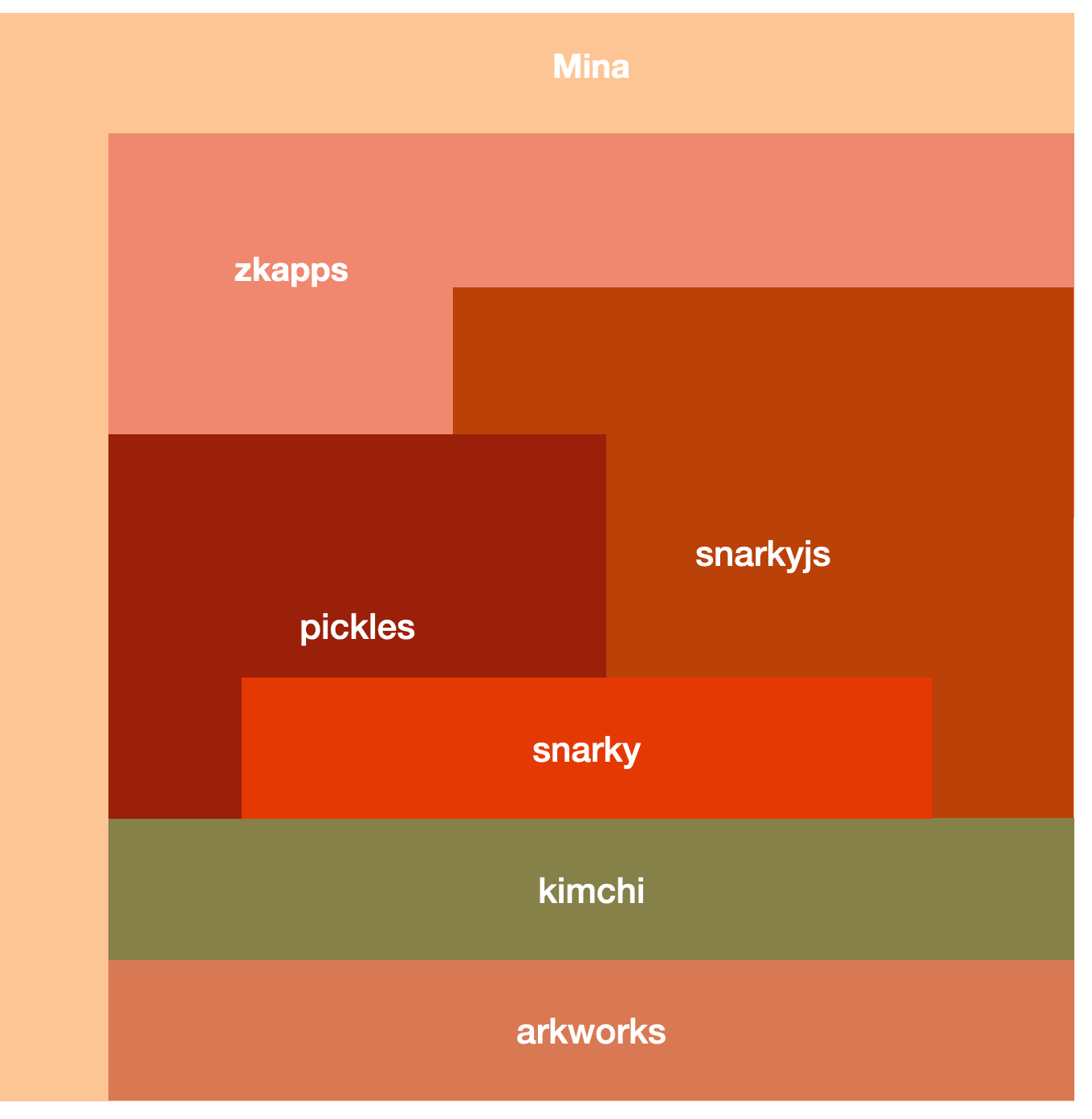
I introduced kimchi in this blogpost last year. It's the general-purpose zero-knowledge proof system that we will use in the next hardfork of Mina. We've been working on it continuously over the last two years to improve its features, performance, and usability.
Kimchi by itself is only a backend to create proofs. The whole picture includes:
Pickles, the recursion layer, for verifying proofs within proofs (ad infinitum)
Snarky, the frontend that allows developers to write programs in a higher-level abstraction that Kimchi and Pickles can prove
Today, both of these parts are written in OCaml and not really meant to be used outside of Mina. With the advent of zkapps most users are able to use all of this right now using typescript in a user-friendly toolbox called snarkyjs.
If you're only interested in using the main tool in typescript, head over to the snarkyjs repo.
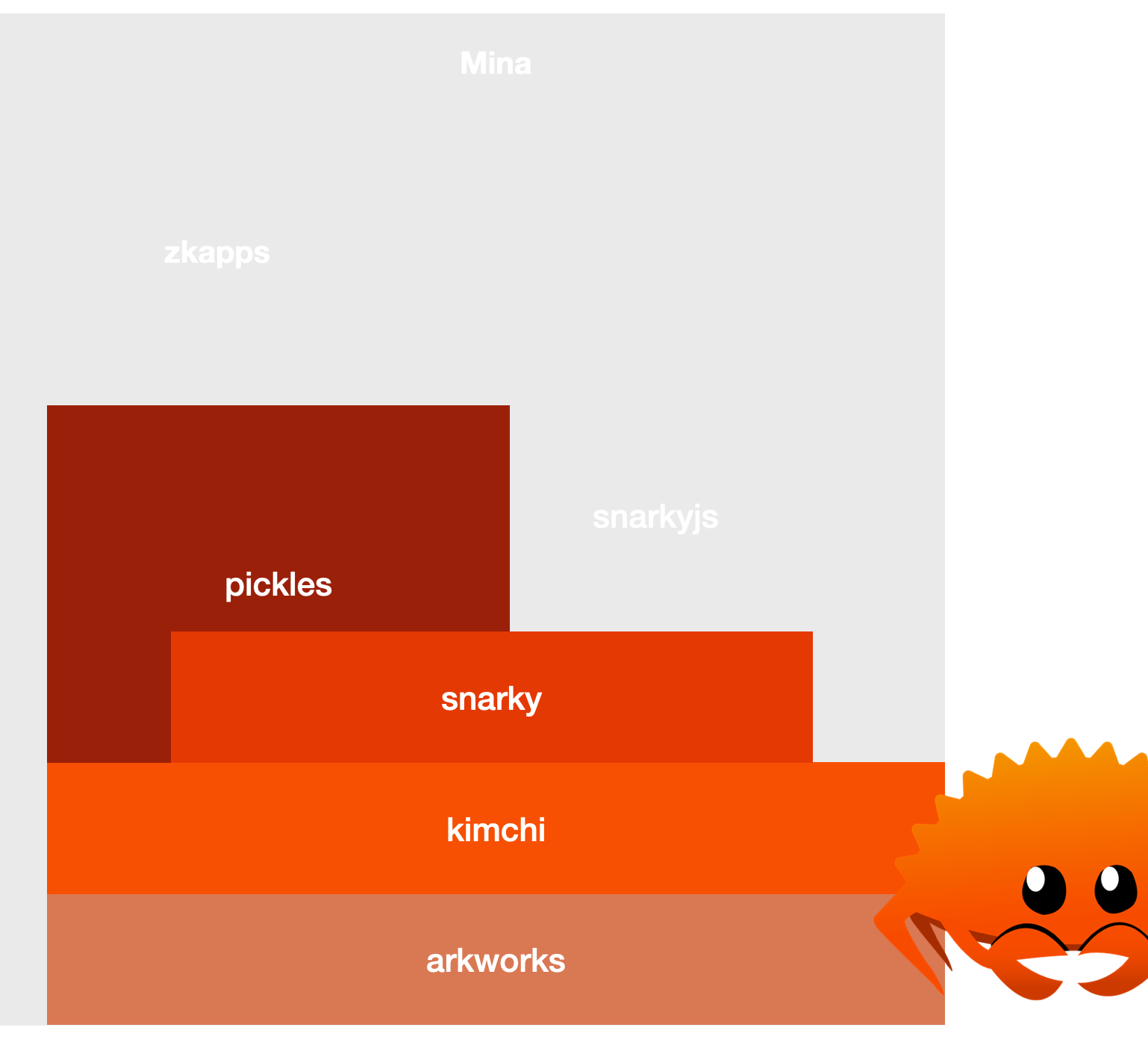
Still, we would benefit from having the pickles + snarky + kimchi combo in a single language (Rust). This would allow us to move faster, and we would be able to improve performances even more. On top of that, a number of users have been looking for an all-in-one zero-knowledge proof Rust library that supports recursion without relying on a trusted setup.
For this reason, we've been moving more to the Rust side.
What does this have to do with you? Well, while we're doing this, kimchi could use some help from the community! We love open source, and so everything's developed in the open.
A year later, we're now the open source zero-knowledge project with the highest number of contributors (as far as I can tell), and we even hired a number of them!
Some of the contributors were already knowledgeable in ZKPs, some were already knowledgeable in Rust, some didn't know anything. It didn't really matter, as we followed the best philosophy for an open source project: the more transparent and understandable a project is, the more people will be able to contribute and build on top of it.
Kimchi has an excellent introduction to contributing (including a short video), a book explaining a number of concepts behind the implementation, a list of easy tasks to start with, and my personal support over twitter or Github =)
So if you're interested in any of these things, don't be shy, look at these links or come talk to me and I'll help you onboard to your first contribution!
Learning OCaml has been quite a harsh journey for myself, especially as someone who didn't know anything (and still doesn't know much) about type systems and the whole theory behind programming languages. (Functional languages, it seems, use a lot of very advanced concepts and it can be quite hard to understand OCaml code without understanding the theory behind it.)
But I digress, I wanted to write this note to "past me" (and anyone like that guy). It's a note about what you should do to get past the OCaml bump. There's two things: getting used to read types, and understanding how to parse compiler errors.
For the first one, a breakthrough in how effective I am at reading OCaml code came when I understood the importance of types. I'm used to just reading code and understanding it through variable names and comments and general organization. But OCaml code is much more like reading math papers I find, and you often have to go much slower, and you have to read the types of everything to understand what some code does. I find that it often feels like reverse engineering. Once you accept that you can't really understand OCaml code without looking at type signatures, then everything will start falling into place.
For the second one, the OCaml compiler has horrendous errors it turns out (which I presume is the major reason why people give up on OCaml). Getting an OCaml error can sometimes really feel like a death sentence. But surprisingly, following some unwritten heuristics can most often fix it. For example, when you see a long-ass error, it is often due to two types not matching. In these kind of situations, just read the end of the error to see what are the types that are not matching, and if that's not enough information then work you way up like you're reading an inverted stack trace. Another example is that long errors might actually be several errors concatenated together (which isn't really clear due to formatting). Copy/pasting errors in a file and adding line breaks manually often helps.
I'm not going to write up exactly how to figure out how each errors should be managed. Instead, I'm hopping that core contributors to OCaml will soon seriously consider improving the errors. In the mean time though, the best way to get out of an error is to ask on on discord, or on stackoverflow, how to parse the kind of errors you're getting. And sometimes, it'll lead you to read about advanced features of the language (like polymorphic recursion).
I'm pleased to announce that I'm part of the steering committee of the Permutation-Based Crypto 2023 one-day workshop which will take place in Lyon, France (my hometown) colocated with Eurocrypt.
Things have changed a lot since the previous one took place (pre-covid!) so I expect some new developments to join the party (wink wink SNARK-friendly sponges).
A lot of cryptographic protocols can be reduced to computing some value. Perhaps the value obtained is a shared secret, or it allows us to verify that some other values match (if it's 0). Since we're talking about cryptography, computing the value is most likely done by adding and multiplying numbers together.
Addition is often free, but it seems like multiplication is a pain in most cryptographic protocols.
If you're multiplying two known values together, it's OK. But if you want to multiply one known value with another unknown value, then you will most likely have to reach out to the discrete logarithm problem. With that in hand, you can multiply an unknown value with a known value.
This is used, for example, in key exchanges. In such protocols, a public key usually masks a number. For example, the public key X in X = [x] G masks the number x. To multiply x with another number, we do this hidden in the exponent (or in the scalar since I'm using the elliptic curve notation here): [y] X = [y * x] G. In key exchanges, you use this masked result as something useful.
If you're trying to multiply two unknown values together, you need to reach for pairings. But they only give you one multiplication. With masked(x) and masked(y) you can do pairing(masked(x), masked(y)) and obtain something that's akin to locked_masked(x * y). It's locked as in, you can't do these kind of multiplications anymore with it.
Previously I talked about monads, which are just a way to create a "container" type (that contains some value), and let people chain computation within that container. It seems to be a pattern that's mostly useful in functional languages as they are often limited in the ways they can do things.
Little did I know, there's more to monads, or at least monads are so vague that they can be used in all sorts of ways. One example of this is state monads.
A state monad is a monad which is defined on a type that looks like this:
type 'a t = state -> 'a * state
In other word, the type is actually a function that performs a state transition and also returns a value (of type 'a).
When we act on state monads, we're not really modifying a value, but a function instead. Which can be brain melting.
The bind and return functions are defined very differently due to this.
The return function should return a function (respecting our monad type) that does nothing with the state:
let return a = fun state -> (a, state)
let return a state = (a, state) (* same as above *)
This has the correct type signature of val return : 'a -> 'a t (where, remember, 'a t is state -> ('a, state)). So all good.
The bind function is much more harder to parse. Remember the type signature first:
val bind : 'a t -> f:('a -> 'b t) -> 'b t
which we can extend, to help us understand what this means when we're dealing with a monad type that holds a function:
you should probably spend a few minutes internalizing this type signature. I'll describe it in other words to help: bind takes a state transition function, and another function f that takes the output of that first function to produce another state transition (along with another return value 'b).
The result is a new state transition function. That new state transition function can be seen as the chaining of the first function and the additional one f.
OK let's write it down now:
let bind t ~f = fun state ->
(* apply the first state transition first *)
let a, transient_state = t state in
(* and then the second *)
let b, final_state = f a transient_state in
(* return these *)
(b, final_state)
Hopefully that makes sense, we're really just using this to chain state transitions and produce a larger and larger main state-transition function (our monad type t).
How does that look like when we're using this in practice? As most likely when a return value is created, we want to make it available to the whole scope. This is because we want to really write code that looks like this:
let run state =
(* use the state to create a new variable *)
let (a, state) = new_var () state in
(* use the state to negate variable a *)
let (b, state) = negate a state in
(* use the state to add a and b together *)
let (c, state) = add a b state in
(* return c and the final state *)
(c, state)
where run is a function that takes a state, applies a number of state transition on that state, and return the new state as well as a value produced during that computation.
The important thing to take away there is that we want to apply these state transition functions with values that were created previously at different point in time.
Also, if that helps, here are the signatures of our imaginary state transition functions:
val new_var -> unit -> state -> (var, state)
val negate -> var -> state -> (var, state)
val add -> var -> var -> state -> (var, state)
Rewriting the previous example with our state monad, we should have something like this:
let run =
bind (new_var ()) ~f:(fun a ->
bind (negate a) ~f:(fun b -> bind (add a b) ~f:(fun c ->
return c)))
Which, as I explained in my previous post on monads, can be written more clearly using something like a let% operator:
let t =
let%bind a = new_var () in
let%bind b = negate a in
let%bind c = add a b in
return c
And so now we see the difference: monads are really just way to do things we can already do but without having to pass the state around.
It can be really hard to internalize how the previous code is equivalent to the non-monadic example. So I have a whole example you can play with, which also inline the logic of bind and return to see how they successfuly extend the state. (It probably looks nicer on Github).
type state = { next : int }
(** a state is just a counter *)
type 'a t = state -> 'a * state
(** our monad is a state transition *)
(* now we write our monad API *)
let bind (t : 'a t) ~(f : 'a -> 'b t) : 'b t =
fun state ->
(* apply the first state transition first *)
let a, transient_state = t state in
(* and then the second *)
let b, final_state = f a transient_state in
(* return these *)
(b, final_state)
let return (a : int) (state : state) = (a, state)
(* here's some state transition functions to help drive the example *)
let new_var _ (state : state) =
let var = state.next in
let state = { next = state.next + 1 } in
(var, state)
let negate var (state : state) = (0 - var, state)
let add var1 var2 state = (var1 + var2, state)
(* Now we write things in an imperative way, without monads.
Notice that we pass the state and return the state all the time, which can be tedious.
*)
let () =
let run state =
(* use the state to create a new variable *)
let a, state = new_var () state in
(* use the state to negate variable a *)
let b, state = negate a state in
(* use the state to add a and b together *)
let c, state = add a b state in
(* return c and the final state *)
(c, state)
in
let init_state = { next = 2 } in
let c, _ = run init_state in
Format.printf "c: %d\n" c
(* We can write the same with our monad type [t]: *)
let () =
let run =
bind (new_var ()) ~f:(fun a ->
bind (negate a) ~f:(fun b -> bind (add a b) ~f:(fun c -> return c)))
in
let init_state = { next = 2 } in
let c, _ = run init_state in
Format.printf "c2: %d\n" c
(* To understand what the above code gets translated to, we can inline the logic of the [bind] and [return] functions.
But to do that more cleanly, we should start from the end and work backwards.
*)
let () =
let run =
(* fun c -> return c *)
let _f1 c = return c in
(* same as *)
let f1 c state = (c, state) in
(* fun b -> bind (add a b) ~f:f1 *)
(* remember, [a] is in scope, so we emulate it by passing it as an argument to [f2] *)
let f2 a b state =
let c, state = add a b state in
f1 c state
in
(* fun a -> bind (negate a) ~f:f2 a *)
let f3 a state =
let b, state = negate a state in
f2 a b state
in
(* bind (new_var ()) ~f:f3 *)
let f4 state =
let a, state = new_var () state in
f3 a state
in
f4
in
let init_state = { next = 2 } in
let c, _ = run init_state in
Format.printf "c3: %d\n" c
(* If we didn't work backwards, it would look like this: *)
let () =
let run state =
let a, state = new_var () state in
(fun state ->
let b, state = new_var () state in
(fun state ->
let c, state = add a b state in
(fun state -> (c, state)) state)
state)
state
in
let init_state = { next = 2 } in
let c, _ = run init_state in
Format.printf "c4: %d\n" c
When I was younger, I used to play a lot of counter strike (CS). CS was (and still is) this first-person shooter game where a team of terrorists would play against a team of counter terrorists. Victory would follow from successfully bombing a site or killing all the terrorists. Pretty simple. I discovered the game at a young age, and I got hooked right away. You could play with other people in cyber cafes, and if you had a computer at home with an internet connection you could even play with others online. This was just insane! But what really hooked me was the competitive aspect of the game. If you wanted, you could team up with 4 other players and play matches against others. This was all new to me, and I progressively spent more and more hours playing the game. That is, until I ended up last of my class, flunked my last year of highschool, failed the Bacalaureat. I decided to re-prioritize my passion in gaming in order not to fail at the path that was laid in front of me. But a number of lessons stayed with me, and I always thought I should write about them.
My first lesson was how intense competition is. I never had any experience come close to it since then, and miss competition dearly. Once you start competing, and you start getting good at it, you feel the need to do everything to get the advantage. Back then, I would watch every frag movie that came out (even producing some), I would know all the best players of every clan (and regularly play with them), and I would participate in 3 online tournaments a day. I would wake up every day around noon, play the first tournament at 1pm, then practice the afternoon, then play the tournament of 9pm, and then the last one at 1am. If my team lost, I would volunteer to replace a player dropping out from a winning team. Rinse and repeat, every day. There's no doubt in my mind that I must have reached Gladwell's 10,000 hours.
I used the same kind of technique years later when I started my master in cryptography. I thought: I know how to become the best at something, I just have to do it all the time, constantly. I just need to obsess. So I started blogging here, I started subscribing to a number of blogs on cryptography and security and I would read everything I could every single hours of every day. I became a sponge, and severally addicted to RSS feeds. Of course, reading about cryptography is not as easy as playing video games and I could never maintain the kind of long hours I would when I was playing counter strike. I felt good, years later, when I decided to not care as much about new notifications in my RSS feed.
Younger, my dream was to train with a team for a week in a gaming house, which is something that some teams were starting to do. You'd go stay in some house together for a week, and every day practice and play games together. It really sounded amazing. Spend all my hours with people who cared as much as me. It seemed like a career in gaming was possible, as more and more money was starting to pour into esport. Some players started getting salaries, and even coaches and managers. It was a crazy time, and I felt really sad when I decided to stop playing. I knew a life competing in esport didn't make sense for me, but competition really was fullfiling in a way that most other things proved not to be.
An interesting side effect of playing counter strike every day, competitively, for many years, is that I went through many teams. I'm not sure how many, but probably more than 50, and probably less than 100. A team was usually 5 players, or more (if we had a rotation). We would meet frequently to spend hours practicing together, figuring out new strategies that we could use in our next game, doing practice matches against other teams, and so on. I played with all different kind of people during that time, spending hours on teamspeak and making life-long friendships. One of my friend, I remember, would get salty as fuck when we were losing, and would often scream at us over the microphone. One day we decided to have an intervention, and he agreed to stop using his microphone for a week in order not to get kicked out of the team. This completely cured his raging.
One thing I noticed was that the mood of the team was responsible for a lot in our performance. If we started losing during a game, a kind of "loser" mood would often take over the team. We would become less enthusiastic, some team mates might start raging at the incompetence of their peers, or they might say things that made the whole team want to give up. Once this kind of behavior started, it usually meant we were on a one-way road to a loss.
But sometimes, when people kept their focus on the game, and tried to motivate others, we would make incredible come backs. Games were usually played in two halves of 15 rounds. First in 16 would win. We sometimes went from a wooping 0-15 to an insane strike of victories leading us to a 16-15. These were insane games, and I will remember them forever.
The common theme between all of those come back stories were in how the whole team faced adversity, together. It really is when things are not going well that you can judge a team. A bad team will sink itself, a strong team will support one another and focus on doing its best, potentially turning the tide.
During this period, I also wrote a web service to create tournaments easily. Most tournaments started using it, and I got some help to translate it in 8 different european languages. Thousands of tournaments got created through the interface, in all kind of games (not just CS). Years later I ended up open sourcing the tool for others to use. This really made me understand how much I loved creating products, and writing code that others could directly use.
Today I have almost no proof of that time, besides a few IRC screenshots. (I was completely addicted to IRC.)