SHA-3 vs the world @ OWASP London posted November 2017
I just gave a talk at OWASP London on SHA-3 and derived functions + derived protocols.
It was apparently the first crypto talk in 5 years so I'm glad I revived this part of OWASP =)
2 comments
Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
Quick access to articles on this page:
more on the next page...
I just gave a talk at OWASP London on SHA-3 and derived functions + derived protocols.
It was apparently the first crypto talk in 5 years so I'm glad I revived this part of OWASP =)
2 commentsI'll be speaking at OWASP London tomorrow. It will be the same talk I just gave at Defcamp two weeks ago, and it will be the last time I give this talk.
It's sold out, but there will be a live streaming posted somewhere (maybe on their facebook page?).
After that, I will be talking at Black Hat Europe about Disco and libDisco. Stay tuned.
1 commentThis is a walk through of the Ethernaut capture-the-flag competition where each challenge was an ethereum smart contract you had to break.
I did this at 2am in a hotel room in Romania and ended up not finishing the last challenge because I took too long and didn't want to re-record that part. Basically what I was missing in my malicious contract: a function to withdraw tokens from the victim contract (it would have work since I had a huge amount of token via the attack). I figured I should still upload that as it might be useful to someone.
4 commentsI wrote an implementation of Noise in Go. I've already talked about it here but I've made some progress towards a more usable library.
It is now a real protocol built from the Noise protocol framework!
Noise doesn't work right off-the-bat because it does not have a length field in its messages. This means that two problems can arise:
In different words, without an indication of a length, noise cannot know where a message stops. Messages can get fragmented by middleboxes, and can get concatenated just because of latency or the way the other peer send its messages. In lab condition this might not be a problem, but in real life without a framing protocol below Noise things will fail quickly.
This is why by default, you can't implement the components of the Noise specification and expect it to work. Having said that, with this minimal addition of a length field things do work!
But that's not the only problem that the specification fails to tackle. The other problem is the authentication of static public keys.
You see, in Noise you have many different ways of doing handshakes (named Noise_XX, Noise_KN, ...), and some of them do not require one of the peer's authentication. Kind of like the typical browser ↔ webserver scenario where only the webserver will authenticate itself via a certificate (and perhaps the browser will later authenticate itself via credentials in a form). Some patterns that you should never use fail to authenticate both side (Noise_NN) and that is why I haven't implemented them. But for patterns that do authenticate one of the side (or both), problems arise: the Noise specification does not have any safeguards in its algorithms to prevent you from failing to authenticate the other side of the connection.
This means that if you implement Noise following the specification, patterns like Noise_XX where both sides require authentication will happily go through without caring about authenticating anything. This leads to trivial active man-in-the-middle attacks.
What I've done is that:
To make things truly plug-and-play, I've created helper functions that let you generate an authoritative root signing key and create proofs or callbacks for a set of parameters. I've written some documentation here that should get you started in no time. If things are broken (this is a beta) or not clear please let me now.
And again, don't use this in production.
The biggest achievement of this implementation though is the fact that it is implementing the net.Conn interface of the Golang standard library. This mean that if you're already using networking code in your Go application, you can just replace your net.Conn or tls.Conn with noise.Conn and things will continue to work seamlessly.
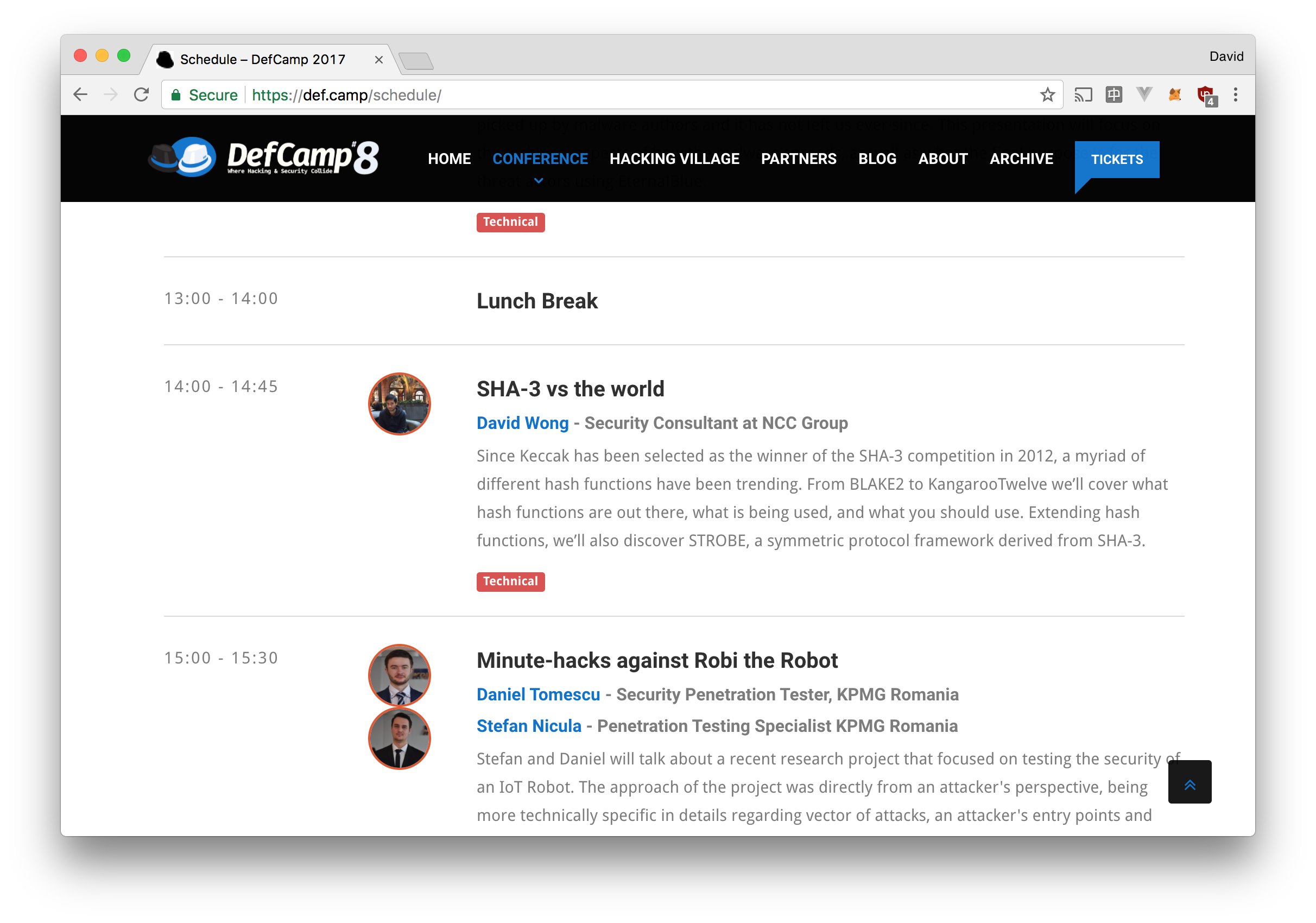
I'll be at Defcamp talking about SHA-3 (the standard), as well as its derived functions and protocols. It's happening next week in Bucharest. If you're around there hit me up!
warning: as this is a proof of concept to see if 4chan could be implemented on the blockchain, some people might post shocking pictures or videos on there. At the time of the writing nothing "bad" has happened, but take precautions if you're planning to take a look at it :)
This is part II of Writing a DAPP for the Ethereum block chain I guess (where I previously said I would not publish this smart contract on the main network).
Pulling the entire Ethereum blockchain took me all afternoon. The thing is taking 29GB of disk space at the moment.
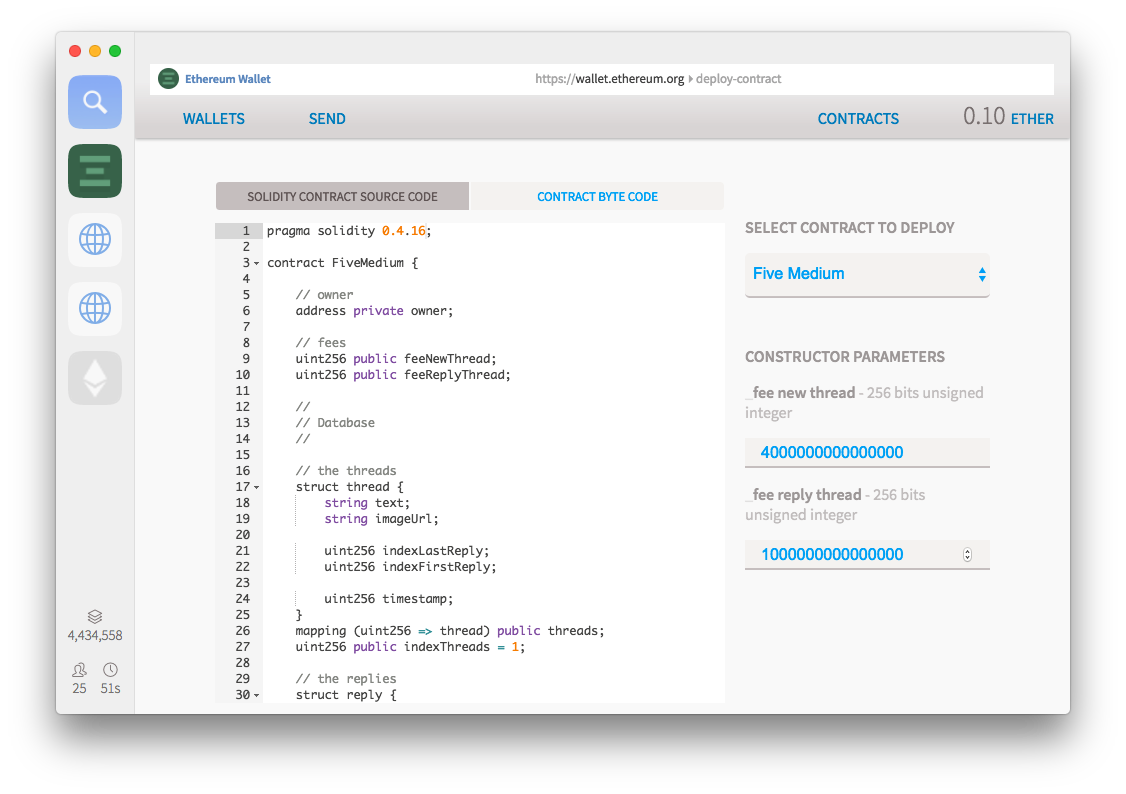
I sent ~20USD worth of ether (0.10 ether) from Coinbase to my real Mist wallet and prepared to see how much it would cost to deploy my smart contract. Surprisingly it was cheap! It cost me 0.007715952 ETHER which is ~2USD (around 1 million unit of gas at 0.008 ether per million gas) to deploy my contract to 0x470fb19D08c3d2eB8923A31d1408c393Dab09ccF an address computed out of my keypair and a nonce. I do not own its associated private key because I simply will never need it.
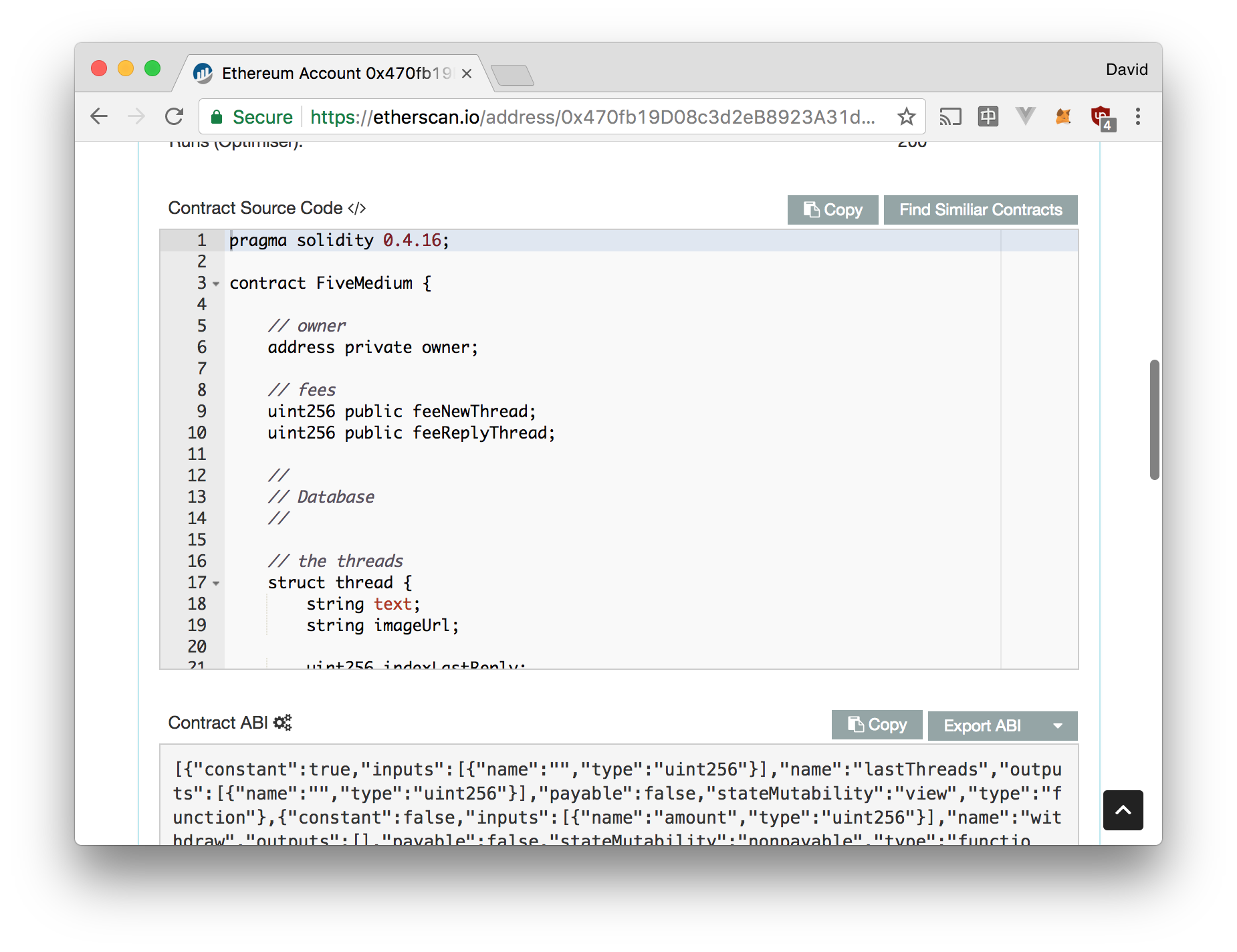
To make sure the smart contract's code was properly open sourced on etherscan.io I had to put the source code there and provide the used compiler's version and the ABI encoded arguments to the controller. The ABI encoded arguments are just the 0-padded hexadecimal encoing of the arguments. I had two uint256 as arguments to my FiveMedium() constructor: the fee to post a thread and the fee to reply to a thread.
I decided to set the creation of a thread around 1$ and replying to a thread around 10 cents. It was then time to push the button and publish it.
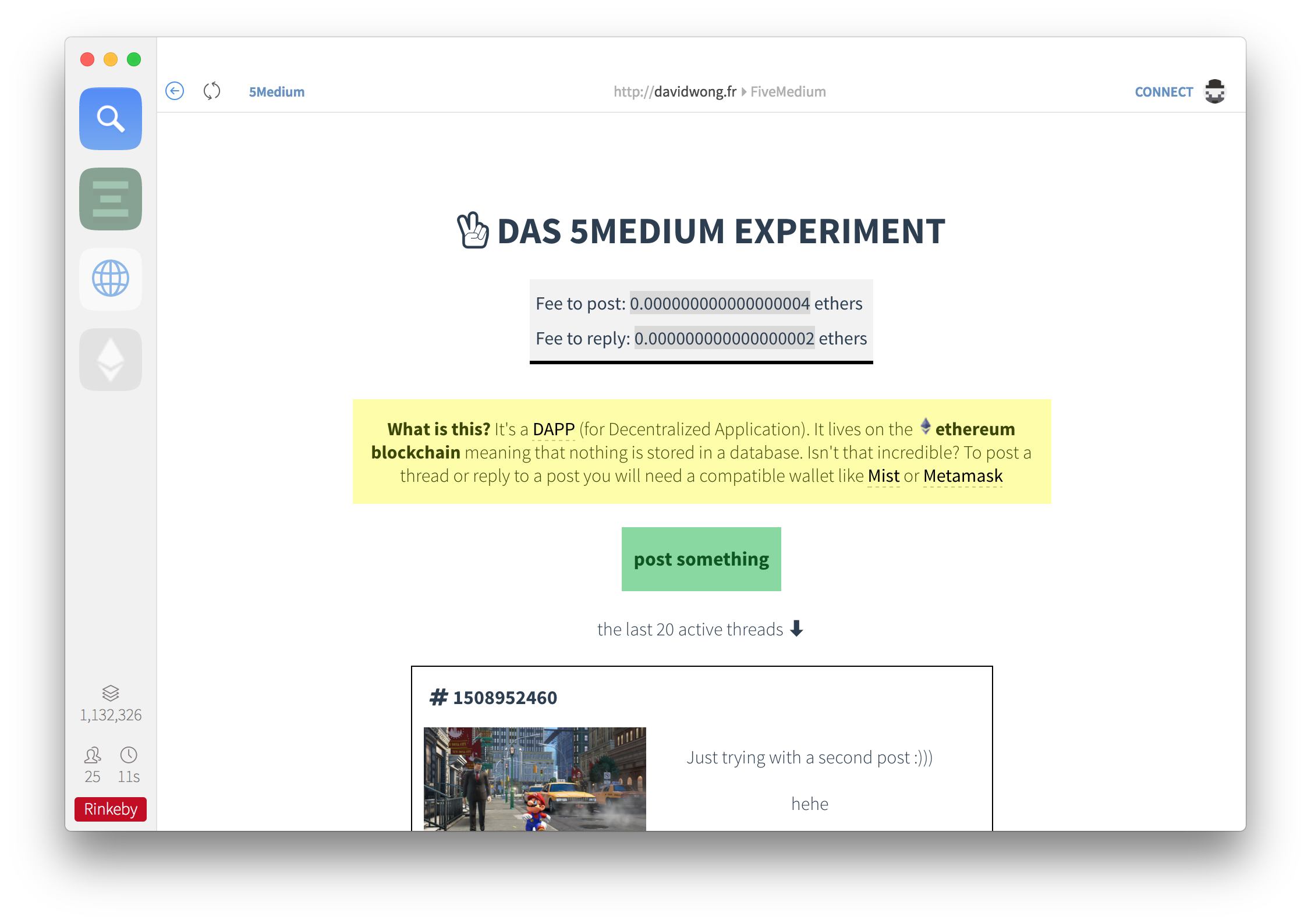
And voila! You can access the DAPP on davidwong.fr/FiveMedium.
Note: the mandatory gas cost to post or reply on a thread seems to be around 0.30$. This has influenced me to lower down the contract fees to approach the gas fees.
2 commentswarning: as this is a proof of concept to see if 4chan could be implemented on the blockchain, some people might post shocking pictures or videos on there. At the time of the writing nothing "bad" has happened, but take precautions if you're planning to take a look at it :)
I've been dabbing in smart contract security (see my video here) and I found it natural to try and do a DAPP (decentralized application) myself. How hard can it be?
3.5 days later I've got back into Javascript after many years; I've learned Vue.js (kind of, my code is really ugly) and I've created my first DAPP!
First thing I'll have to say: it's hella fun.
Javascript has gone a long way and the Vue.js framework is just great! I've tried using React but I found it less developer-friendly, harder to learn and lacking in terms of template. It just didn't click. I guess coming from HTML first (and jQuery later) the Vue.js framework just makes more sense to me. It's all about having fun and I wasn't having any with React.
I still want to create, modify and query things the jQuery way, but I'm getting used to the javascript modernities (querySelector, arrow functions, ...) and the Vue.js way. I like it. It will take some time to get rid of my old habits and re-think the way I write front end code but I like it.
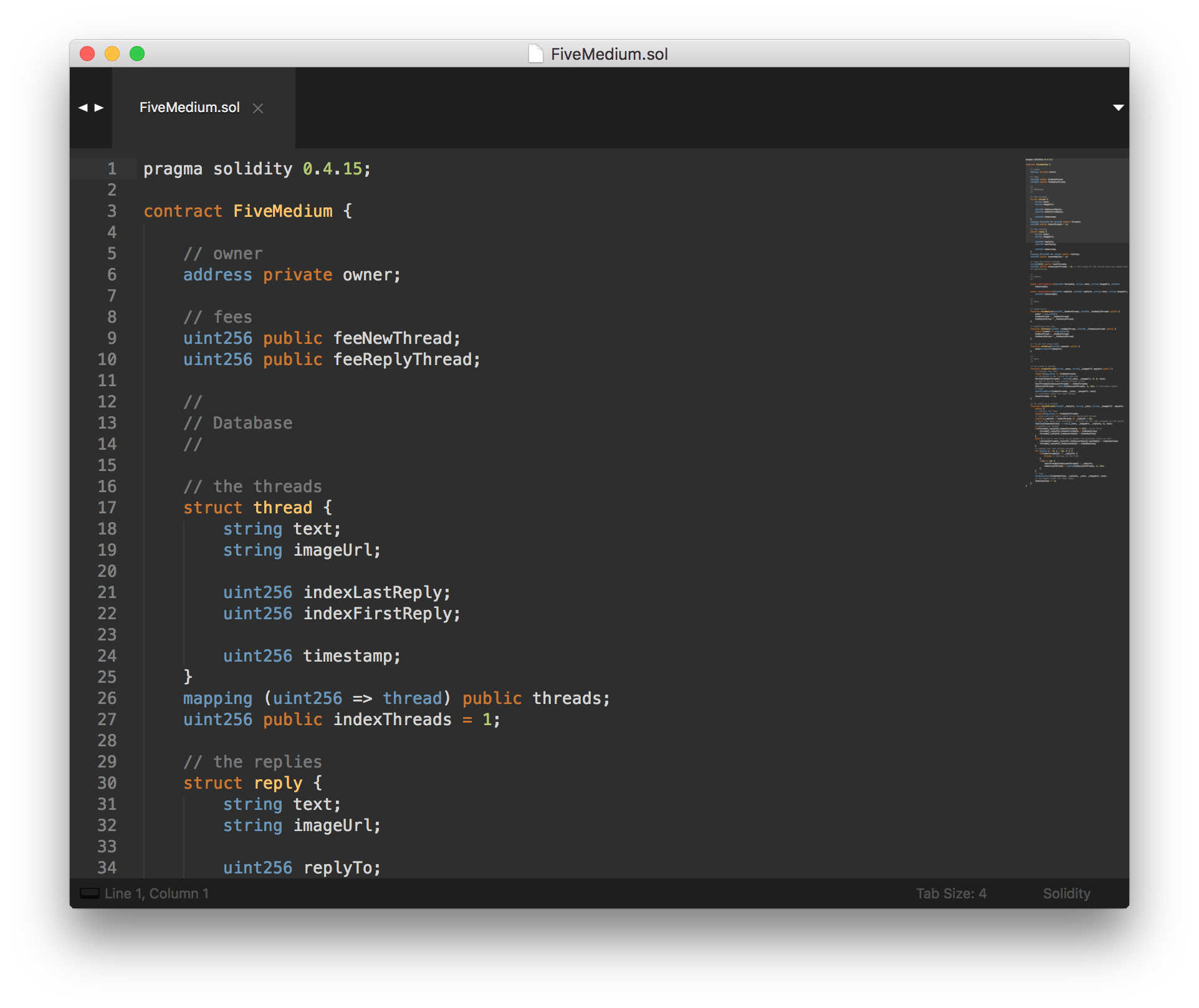
Writing the smart contract is quite straight forward. It's 128 lines of Solidity code, but most of it are comments (yes I comment my code). At one point I should publish it on etherscan.io because this is best practice. It's not compiled with the last version of Solidity (boooo!) because I deployed it via Mist and Mist doesn't have the last version of Solidity.
Writing the dapp with Vue.js and the web3.js API (the javascript library to interact with the blockchain via an ethereum node) is pretty straight forward as well. The learning curve is not bad and there are tons of resources for beginners. That is, until you test your dapp with a real wallet like the Metamask wallet (integrated as a browser plugin) or the official Mist wallet (Electron app). Different wallets offer different functions and versions of web3 (how it works: they inject the web3 object in your document and you can use it directly from your javascript webapp). They also (for the most part) refuse any synchronous calls on the web3 API without really providing ways for you to debug what is not synchronous in your call. A lot of functions have to be replaced for the asynchronous variants, any async/await has to disappear and you enter callback hell. Not fun.
The worst is that the documentation gets sparser and sparser as you enter the world of real DAPPs. You understand that things are changing really fast, that wallets will soon stop supporting web3.js and that a real API will be provided at some point. Everything is way more experimental than I had thought.
On top of that, Metamask doesn't let you watch for events yet, so say goodbye to your DAPP being "live" for their users.
To make the app offline, meaning browsable without a wallet, I use Infura. You basically just have to switch the url of the node to the ones Infura gives you, and web3 will be able to interact with it the same way it interacts with a real node. This is because the standard works via normal Json-RPC routes using the Json way to structure queries and responses. Unfortunately, like Metamask, Infura doesn't let you listen to events so the app is browsable, but not live.
I haven't taken the time to publish the smart contract on the real ethereum network yet. It's sitting on Rinkeby which is a test network where you can get ethers for free. I'm not going to get rich on a test network, and some of my friends are eyeballing me for this decision (I see you jc) but this is fun and I want people to try it for free :)
Is it hard? No but it's annoying. First I need to pull up the whole Ethereum blockchain.
As of April 19th, 2017, my blockchain size is 23.5 GB total.
from this Quora answer
Second, I need some ethers, and buying ethers from the UK is hard. Of course I already have some (I wouldn't be writing anything about ethereum if I wasn't invested), but I had to go through weeks of research to buy them. (If you're looking for an easy way, learn from my wasted time: transfer money on a Revolut account, change it to euro, do a free SEPA transfer to Kraken, buy ethers there.)
Anyone can replicate my work. The DAPP is client-side code (javascript) so anyone can download it and run it on their own page. the contract is also up there on the blockchain, it's public stuff. I don't really like this, but it is how Ethereum works. If I someday drop the page from the internet, anyone can get it and run it. Run it on their own server, but also run it locally from their own machine.
If you want to see how it works without getting a wallet:
But I recommend you to give a try to this new technology!
Download Mist, set the network to Rinkeby, grab some free ethers from the faucet there and browse to my DAPP FiveMedium.
Have fun!
PS: yes this is heavily inspired by 4chan.
2 commentsI just made a video covering common attacks on Ethereum's smart contracts. I used live0verflow's techniques to record and edit this one so it's going to feel different from the others :) It's a tl;dr of A survey of attacks on Ethereum smart contracts by Nicola Atzei and Massimo Bartoletti and Tiziana Cimoli.
ps: many thanks to Matthew Di Ferrante for the help!
comment on this story
My book Real-World Cryptography is finished and shipping! You can purchase it here.
If you don't know where to start, you might want to check these popular articles:
Here are the latest links posted:
You can also suggest a link.