Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
If you know about authenticated encryption, you could stop reading here, understand that you can just use AES-GCM or Chacha20-Poly1305 whenever you need to encrypt something, and move on with your life. Unfortunately real-world cryptography is not always about the agreed standard, it is also about constraints. Constraints in size, constraints in speed, constraints in format, and so on. For this reason, we need to look at scenarios where these AEADs won't fit, and what solutions have been invented by the field of cryptography.
Wrapping keys: how to encrypt secrets
One of the problem of nonce-based AEADs is that they all require a nonce, which takes additional space. In worse scenarios, the nonce to-be-used for encryption comes from an untrusted source and can thus lead to nonce repetition that would damage the security of the encryption. From these assumptions, it was noticed that encrypting a key might not necessarily need randomization, since what is encrypted is already random.
Encrypting keys is a useful paradigm in cryptography, and is used in a number of protocol as you will see in the second part of this book.
These two algorithms are often implemented in Hardware Security Modules (HSM). HSMs are devices that are capable of performing cryptographic operations while ensuring that keys they store cannot be extracted by physical attacks. That's at least if you're under a certain budget.
These key-wrapping algorithms do not take an additional nonce or IV, and randomize their encryption based on what they are encrypting. Consequently, they do not have to store an additional nonce or IV next to the ciphertexts.
AES-GCM-SIV and nonce-misuse resistance authenticated encryption
In 2006, Rogaway published a new key-wrapping algorithm called Synthetic initialization vector (SIV), as part of Deterministic Authenticated-Encryption: A Provable-Security Treatment of the Key-Wrap Problem.
In the white paper, Rogaway notes that the algorithm is not only useful to encrypt keys, but as a general AEAD algorithm as well that is resistant to nonce repetitions.
As you probably know, a repeating nonce in AES-GCM or Chacha20-Poly1305 has catastrophic consequences. It not only reveals the XOR of the two plaintexts, but it also allows an attacker to recover an authentication key and to forge more messages. In Nonce-Disrespecting Adversaries: Practical Forgery Attacks on GCM in TLS, a group of researchers found 184 HTTPS servers being guilty of reusing nonces. (I even wrote here about their super-cool live demo.)
The point of a nonce-misuse resistant algorithm is that encrypting two plaintexts with the same nonce will only reveal if the two plaintexts are equal or not.
It is sometimes hard to obtain good randomness on constrained devices or mistakes can be made. In this case, nonce-misuse resistant algorithms solve real problems.
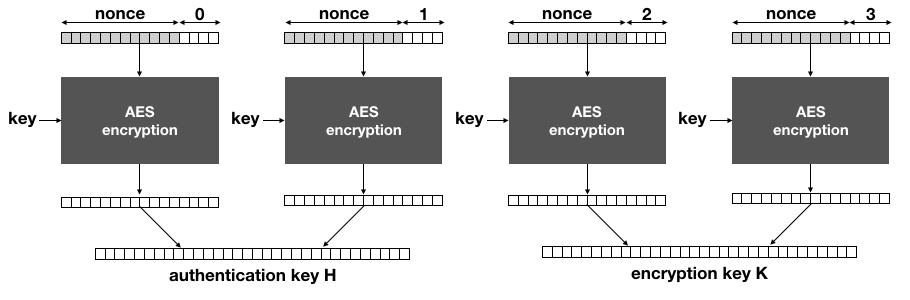
The idea of AES-GCM-SIV is to generate the encryption and authentication keys separately via a main key every time a message has to be encrypted (or decrypted). This is done by producing a keystream long enough with AES-CTR, the main key and a nonce:
The main key of AES-GCM-SIV is used solely with AES-CTR to derive the encryption key K and the authentication key H.
Notice that if the same nonce is used to encrypt two different messages, the same keys will be derived here.
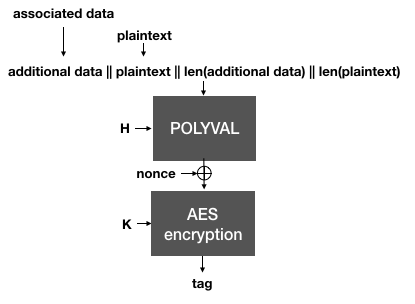
Next, AES-GCM-SIV authenticates the plaintext, instead of the ciphertexts as we have seen in the previous schemes. This creates an authentication tag over the associated data and the plaintext (and their respective lengths). Instead of GMAC, AES-GCM-SIV defines a new MAC called Polyval. It is quite similar and only attempts to optimize some of GMAC's operations.
The Polyval function is used to hash the plaintext and the associated data. It is then encrypted with the encryption key K to produce an authentication tag.
Importantly, notice that if the same nonce is reused, two different messages will of course produce two different tags. This is important because in AES-GCM-SIV, the tag is then used as a nonce to AES-CTR in order to encrypt the plaintext.
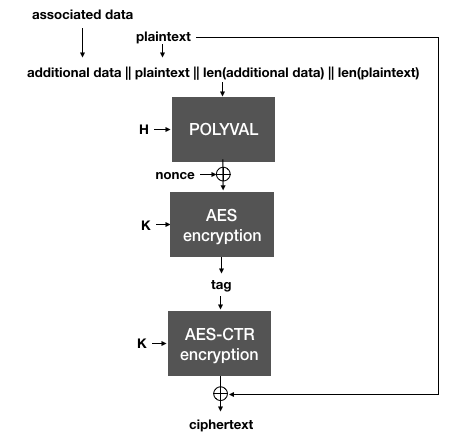
AES-GCM-SIV uses the authentication tag (created with Polyval over the plaintext and the associated data) as a nonce for AES-CTR to encrypt the plaintext.
This is the trick behind SIV: the nonce used to encrypt in the AEAD is generated from the plaintext itself, which makes it highly unlikely that two different plaintexts will end up being encrypted under the same nonce. To decrypt, the same process is done in reverse:
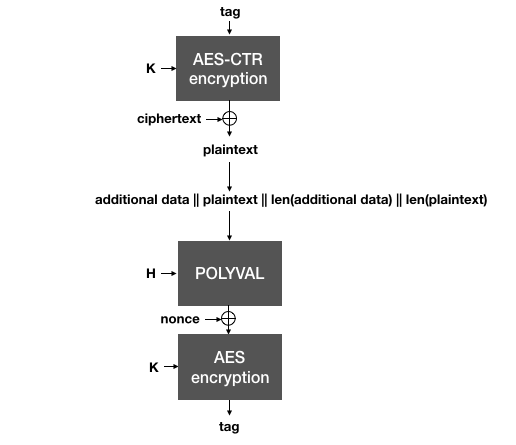
AES-GCM-SIV decrypts a ciphertext by using the authentication as a nonce for AES-CTR. The plaintext recovered is then used along with the associated data to validate the authentication tag. Both tags need to be compared (in constant-time) before releasing the plaintext to the application.
As the authentication tag is computed over the plaintext, the ciphertext must first be decrypted (using the tag as an effective nonce). Then, the plaintext must be validated against the authentication tag. Because of that, one must realize two things:
The plaintext is released by the algorithm before it can be authenticated. For this reason it is extremely important that nothing is done with the plaintext, until it is actually deemed valid by the authentication tag verification.
Since the algorithm works by decrypting the ciphertext (respectively encrypting the plaintext) as well as authenticating the plaintext, we say that it is two-pass -- it must go over the data twice. Because of this, it usually is slower than its counterpart AES-GCM.
// sign a message
hash, _ := hex.DecodeString("ffffffff00000000ffffffffffffffffbce6faada7179e84f3b9cac2fc632552")
r, s, err := ecdsa.Sign(rand.Reader, privateKey, hash[:])
if err != nil {
panic(err)
}
// print the signature
signature := r.Bytes()
signature = append(signature, s.Bytes()...)
fmt.Println("signature:", hex.EncodeToString(signature))
// verify the signature
if !ecdsa.Verify(&privateKey.PublicKey, hash[:], r, s) {
panic("wrong signature")
} else {
fmt.Println("signature valid for", hex.EncodeToString(hash[:]))
}
// I modify the message, this should invalidate the signature
var hash2 [32]byte
hash2[31] = 1
if !ecdsa.Verify(&privateKey.PublicKey, hash2[:], r, s) {
panic("wrong signature")
} else {
fmt.Println("signature valid for", hex.EncodeToString(hash2[:]))
}
this should print out:
signature: 4f3e60dc53ab470d23e82567909f01557f01d521a0b2ae96a111d107741d8ebb885332d790f0691bdc900661bf40c595a07750fa21946ed6b88c61c43fbfc1f3
signature valid for ffffffff00000000ffffffffffffffffbce6faada7179e84f3b9cac2fc632552
signature valid for 0000000000000000000000000000000000000000000000000000000000000001
Can you tell what's the problem? Is ECDSA broken? Is Golang's standard library broken? Is everything fine?
On August 11th, 2015, Andrew Ayer sent an email to the IETF mailing list starting with the following words:
I recently reviewed draft-barnes-acme-04 and found vulnerabilities in the DNS, DVSNI, and Simple HTTP challenges that would allow an attacker to fraudulently complete these challenges.
The draft-barnes-acme-04 mentioned by Andrew Ayer is a document specifying ACME, one of the protocols behind the Let's Encrypt certificate authority.
A certificate authority is the thing that your browser trusts and that signs the public keys of websites you visit.
It is called a "certificate" authority due to the fact that it does not sign public keys, but certificates.
A certificate is just a blob of data bundling a website's public key, its domain name, and some other relevant metadata.
The attack was found merely 6 weeks before major browsers were supposed to start trusting Let's Encrypt's public key. The draft has since become RFC 8555: Automatic Certificate Management Environment (ACME),
mitigating the issues.
Since then no cryptographic attacks are known on the protocol.
This blog post will go over the accident, and explain why it happened, why it was a surprising bug, and what you should watch for when using signatures in cryptography.
How Let's Encrypt used signatures
Let's Encrypt is a pretty big deal. Created in 2014, it is a certificate authority run as a nonprofit, providing trust to hundreds of millions of websites.
The key to Let's Encrypt's success are twofold:
It is free. Before Let's Encrypt most certificate authorities charged fees from webmasters who wanted to obtain certificates.
It is automated. If you follow their standardized protocol, you can request, renew and even revoke certificates via a web interface. Contrast that to other certificate authorities who did most processing manually, and took time to issue certificates.
If a webmaster wants her website example.com to provide a secure connection to her users (via HTTPS), she can request a certificate from Let's Encrypt (essentially a signature over its domain name and public key), and after proving that she owns the domain example.com and getting her certificate issued, she will be able to use it to negotiate a secure connection with any browser trusting Let's Encrypt.
That's the theory.
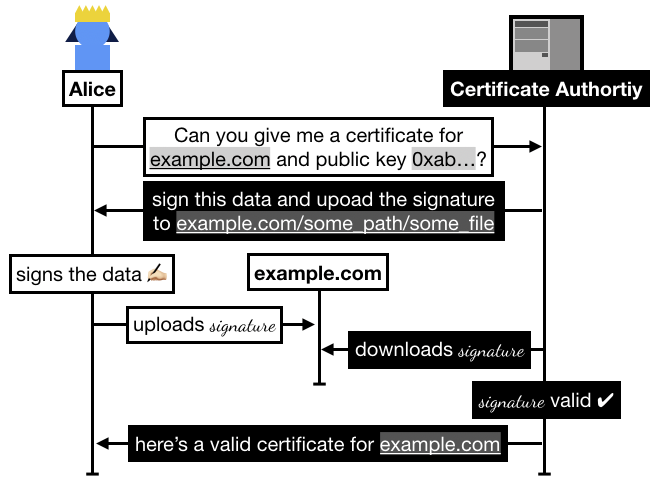
In practice the flow goes like this:
Alice registers on Let's Encrypt with an RSA public key.
Alice asks Let's Encrypt for a certificate for example.com.
Let's Encrypt asks Alice to prove that she owns example.com, for this she has to sign some data and upload it to example.com/.well-known/acme-challenge/some_file.
Once Alice has signed and uploaded the signature, she asks Let's Encrypt to go check it.
Let's Encrypt checks if it can access the file on example.com, if it successfully downloaded the signature and the signature is valid then Let's Encrypt issues a certificate to Alice.
In 2015, Alice could request a signed certificate from Let's Encrypt by uploading a signature (from the key she registered with) on her domain. The certificate authority verifies that Alice owns the domain by downloading the signature from the domain and verifying it. If it is valid, the authority signs a certificate (which contains the domain's public key, the domain name example.com, and some other metadata) and sends it to Alice who can then use it to secure her website in a protocol called TLS.
Let's see next how the attack worked.
How did the Let's Encrypt attack work?
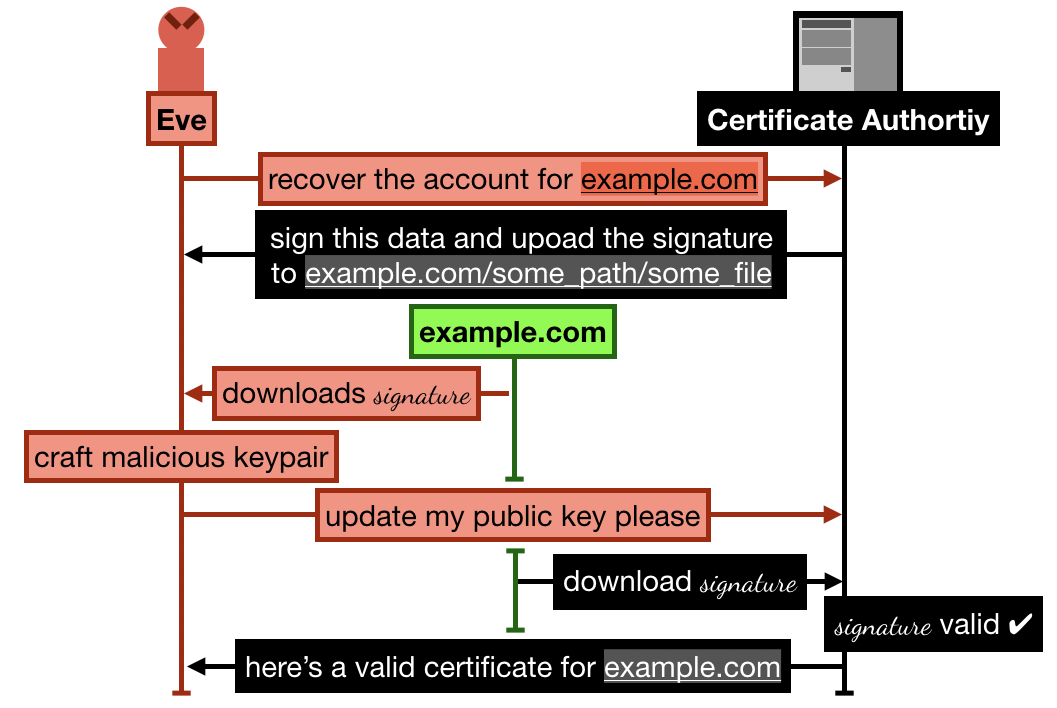
In the attack that Andrew Ayer found in 2015, Andrew proposes a way to gain control of a Let's Encrypt account that has already validated a domain (let's pick example.com as an example)
The attack goes something like this (keep in mind that I'm simplifying):
Alice registers and goes through the process of verifying her domain example.com by uploading some signature over some data on example.com/.well-known/acme-challenge/some_file. She then successfully manages to obtain a certificate from Let's Encrypt.
Later, Eve signs up to Let's Encrypt with a new account and an RSA public key, and request to recover the example.com domain
Let's Encrypt asks Eve to sign some new data, and upload it to example.com/.well-known/acme-challenge/some_file (note that the file is still lingering there from Alice's previous domain validation)
Eve crafts a new malicious keypair, and updates her public key on Let's Encrypt. She then asks Let's Encrypt to check the signature
Let's Encrypt obtains the signature file from example.com, the signature matches, Eve is granted ownership of the domain example.com. She can then ask Let's Encrypt to issue valid certificates for this domain and any public key.
The 2015 Let's Encrypt attack allowed an attacker (here Eve) to successfully recover an already approved account on the certificate authority. To do this, she simply forges a new keypair that can validate the already existing signature and data from the previous valid flow.
Take a few minutes to understand the attack.
It should be quite surprising to you.
Next, let's see how Eve could craft a new keypair that worked like the original one did.
Key substitution attacks on RSA
In the previously discussed attack, Eve managed to create a valid public key that validates a given signature and message.
This is quite a surprising property of RSA, so let's see how this works.
A digital signature does not uniquely identify a key or a message. -- Andrew Ayer, Duplicate Signature Key Selection Attack in Let's Encrypt (2015)
Here is the problem given to the attacker:
for a fixed signature and (PKCS#1 v1.5 padded) message, a public key $(e, N)$ must satisfy the following equation to validate the signature:
$$signature = message^e \pmod{N}$$
One can easily craft a key pair that will (most of the time) satisfy the equation:
a public exponent $e = 1$
a private exponent $d = 1$
a public modulus $N = \text{signature} - \text{message}$
You can easily verify that the validation works with this keypair:
This property called "key substitution" comes from the fact that there exists a gap between the theoretical cryptography world and the applied cryptography world, between the security proofs and the implemented protocols.
Signatures in cryptography are usually analyzed with the EUF-CMA model, which stands for Existential Unforgeability under Adaptive Chosen Message Attack.
In this model YOU generate a key pair, and then I request YOU to sign a number of arbitrary messages.
While I observe the signatures you produce, I win if I can at some point in time produce a valid signature over a message I hadn't requested.
Unfortunately, even though our modern signature schemes seem to pass the EUF-CMA test fine, they tend to exhibit some surprising properties like the key substitution one.
To learn more about key substitution attack and other signature shenanigans, take a look at my book Real-World Cryptography.
I've now spent 2 years writing my introduction on applied cryptography: Real-World Cryptography, which you can already read online here.
(If you're wondering why I'm writing another book on cryptography check this post.)
I've written all the chapters, but there's still a lot of work to be done to make sure that it's good (collecting feedback), that it's consistent (unification of diagrams, of style, etc.), and that it's well structured.
For the latter point, I thought I would leverage the fact that I'm an engineer and use a tool that's commonly used to measure performance: a flamegraph!
It looks like this, and you can click around to zoom on different chapters and sections:
How does this work?
The bottom layer shows all the chapter in order, and the width of the boxes show how lengthy they are.
The more you go up, the more you "nest" yourself into a section.
For example, clicking on the chapter 9: Secure transport, you can see that it is composed of several sections with the longest being "How does TLS work", which itself is composed of several subsections with the longest being "The TLS handshake".
What is it good for?
Using this flamegraph, I can now analyze how consistent the book is.
Distribution
The good news is that the chapters all seem pretty evenly distributed, for the exception of shorter chapters 3 (MACs), 6 (asymmetric encryption), and 16 (final remarks).
This is also expected are these chapters are much more straightforward than the rest of the book.
Too length
Looks like the bigger chapters are in order: post-quantum crypto, authenticated encryption, hardware cryptography, user authentication, secure transport.
This is not great, as post-quantum crypto is supposed to be a chapter for the curious people who get to the end of the book, not a chapter to make the book bigger...
The other chapters are also unnecessary long.
My goal is going to be to reduce these chapters' length in the coming weeks.
Too nested
This flamegraph is also useful to quickly see if there are sections that are way too nested. For example, Chapter 9 on secure transport has a lot of mini sections on TLS.
Also, look at some of the section in chapter 5: Key exchanges > Key exchange standards > ECDH > ECDH standard. That's too much.
Not nested enough
Some chapters have almost no nested sections at all. For example, chapter 8 (randomness) and 16 (conclusion) are just successions of depth-1 sections. Is this a bad thing? Not necessarily, but if a section becomes too large it makes sense to either split it into several sections, or have subsections in it.
I've noticed, for example, that the first section of chapter 3 on MACs titled "What is a MAC?" is quite long, and doesn't have subsections.
(Same for section 6.2 asymmetric encryption in practice and section 8.2 what is a PRNG)
Errors
I also managed to spot some errors in nested sections by doing this! So that was pretty cool as well :)
EDIT: If you're interested in doing something like this with your own project, I published the script here.
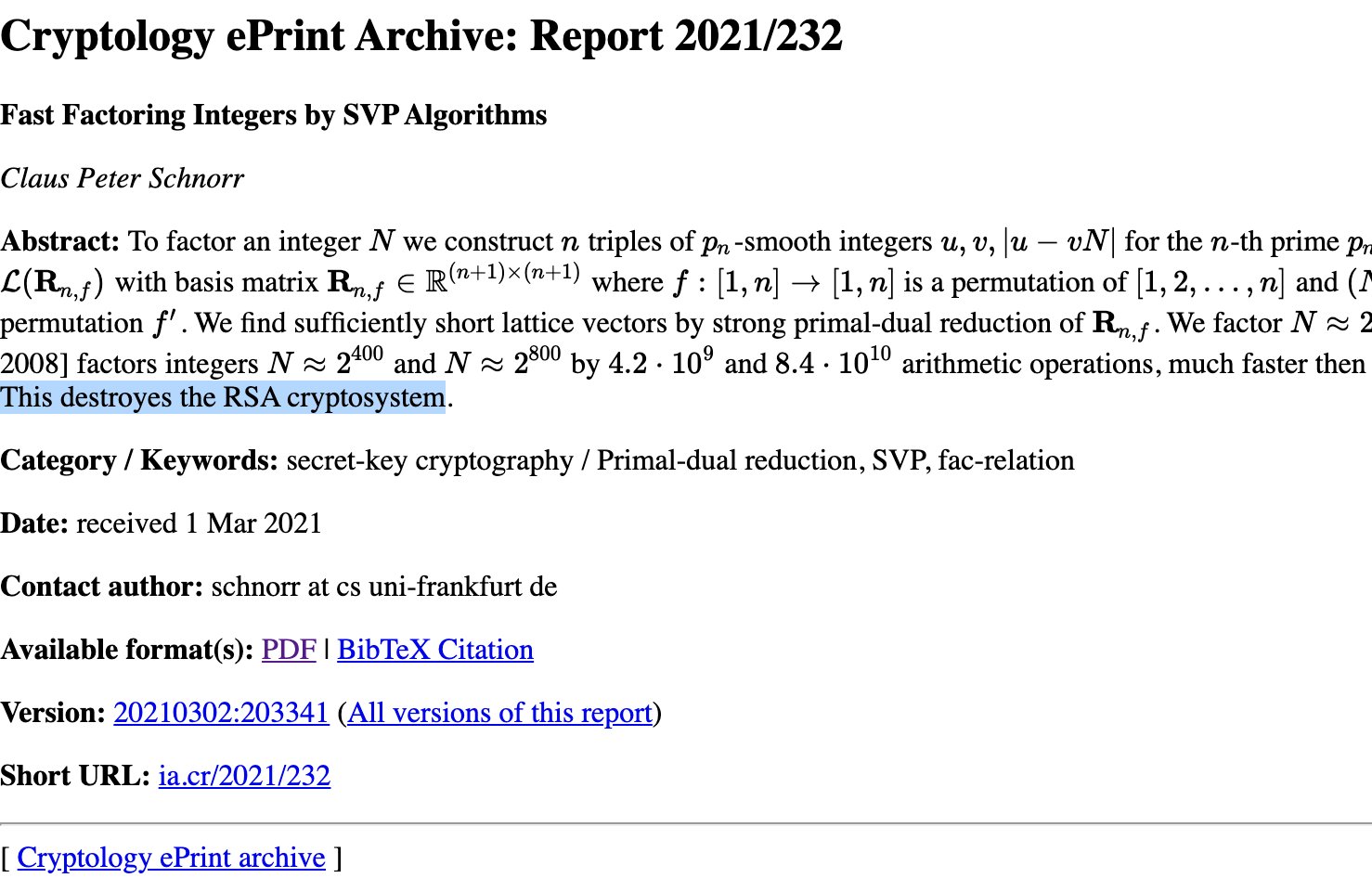
Schnorr just released a new paper Fast Factoring Integers by SVP Algorithms with the words "This destroyes the RSA cryptosystem." (spelling included) in the abstract.
What does this really mean? The paper is honestly quite dense to read and there's no conclusion in there.
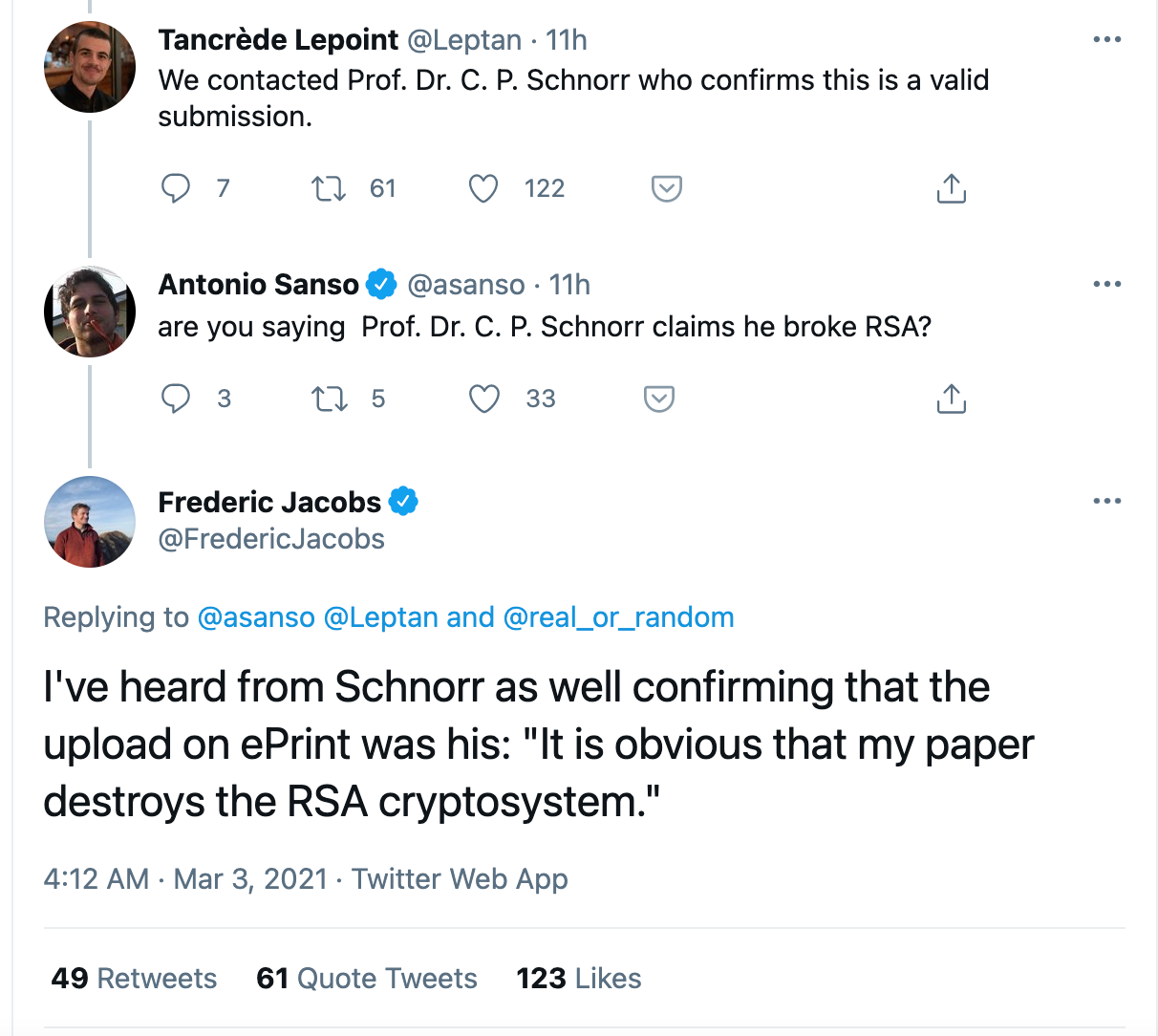
UPDATE: Several people have pointed out that the "This destroyes the RSA cryptosystem" is not present in the paper itself, that is until the paper was updated to include the sentence without the typo.
UPDATE: There was some discussion about a potential fake, but several people in the industry are confirming that this is from Schnorr himself:
According to the claims in Schnorr’s paper, it should be practical to set significant new factoring records. There is a convenient 862-bit RSA challenge that has not been factored yet. Posting its factors, as done for the CADO-NFS team’s records, would lend credence to Schnorr’s paper and encourage more review of the methodology.
UPDATE: Geoffroy Couteau thinks the claim is wrong:
several top experts on SVP and CVP algorithms have looked at the paper and concluded that it is incorrect (I cannot provide names, since it was in the context of anonymous reviews).
Schnorr is 78 years old. I am not gerontophobic (being 50 I am approaching that age) but: Atiyah claimed the Riemann Hypothesis, Hironaka has claimed full resolution of singularities in any characteristic... And I am speaking of Fields medalists.
So: you do really need peer-review for strong arguments.
I was on the Technoculture podcast (or videocast?) to talk about cryptography in general.
The host Federica Bressan is releasing excerpts bit by bit.
You can watch the first part (Theoretical vs. Real-World Cryptography) here:
And here's the rest that I will update as they get posted