Quick access to articles on this page:
more on the next page...
The Let's Encrypt Accident
On August 11th, 2015, Andrew Ayer posted the following email to the IETF mailing list:
I recently reviewed draft-barnes-acme-04 and found vulnerabilities in the DNS, DVSNI, and Simple HTTP challenges that would allow an attacker to fraudulently complete these challenges.
(The author has since then written a more complete explanation of the attack.)
The draft-barnes-acme-04 mentioned by Andrew Ayer is a document specifying ACME, one of the protocols behind the Let's Encrypt Certificate Authority. The thing that your browser trust and that signs the public keys of websites you visit.
The attack was found merely 6 weeks before major browsers were supposed to ship with Let's Encrypt's public keys in their trust store. The draft has since become RFC 8555: Automatic Certificate Management Environment (ACME), mitigating the issues. Since then no cryptographic attacks are known on the protocol.
But how did we get there? What's the deal with signature schemes these days? and are all of our protocols doomed? This is what this blog post will answer.
Let's Encrypt Use Of Signatures
Let's Encrypt is a pretty big deal. Created in 2014, it is a certificate authority ran as a non-profit, and currently providing trust to ~200 million of websites.
(You can read my article Let's Encrypt Overview to learn more about it.)
The key to Let's Encrypt's success are two folds:
- It is free. Before Let's Encrypt most certificate authorities charged fees from webmasters who wanted to obtain certificates.
- It is automated. If you follow their standardized protocol, you can request, renew and even revoke certificates via an API. Contrast that to other certificate authorities who did most processing manually, and took time to issue certificates.
If a webmaster wants her website example.com to provide a secure connection to her users (via HTTPS), she can request a certificate from Let's Encrypt, and after proving that she owns the domain example.com and getting her certificate issued, she will be able to use it to negotiate a secure connection with any browser trusting Let's Encrypt.
That's the theory.
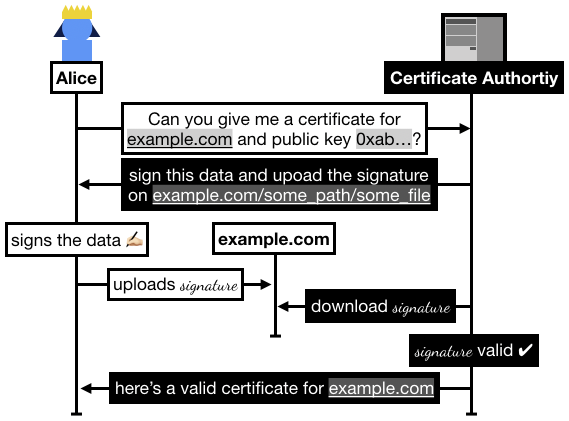
In practice the flow is the following:
- Alice registers on Let's Encrypt with an RSA public key.
- Alice asks Let's Encrypt for a certificate for
example.com.
- Let's Encrypt asks Alice to prove that she owns
example.com, for this she has to sign some data and upload it to example.com/.well-known/acme-challenge/some_file.
- Once Alice has signed and uploaded the signature, she asks Let's Encrypt to go check it.
- Let's Encrypt checks if it can access the file on
example.com, if it successfully downloaded the signature and the signature is valid then Let's Encrypt issues a certificate to Alice.
I recapitulate some of this flow in the following figure:
Now, you might be wondering, what if Alice does not own example.com and manage to man-in-the-middle Let's Encrypt in step 5? That's a real issue that's been bothering me ever since Let's Encrypt launched, and turns out a team of researchers at Princeton demonstrated exactly this in Bamboozling Certificate Authorities with BGP:
We perform the first real-world demonstration of BGP attacks to obtain bogus certificates from top CAs in an ethical manner. To assess the vulnerability of the PKI, we collect a dataset of 1.8 million certificates and find that an adversary would be capable of gaining a bogus certificate for the vast majority of domains
The paper continues and proposes two solutions to sort of remediate, or at least reduce the risk of these attacks:
Finally, we propose and evaluate two countermeasures to secure the PKI: 1) CAs verifying domains from multiple vantage points to make it harder to launch a successful attack, and 2) a BGP monitoring system for CAs to detect suspicious BGP routes and delay certificate issuance to give network operators time to react to BGP attacks.
Recently Let's Encrypt implemented the first solution multi-perspective domain validation, which changes the way step 5 of the above flow is performed: now Let's Encrypt downloads the proof from example.com from multiple places.
How Did The Let's Encrypt Attack Worked
But let's get back to what I was talking about, the attack that Andrew Ayer found in 2015.
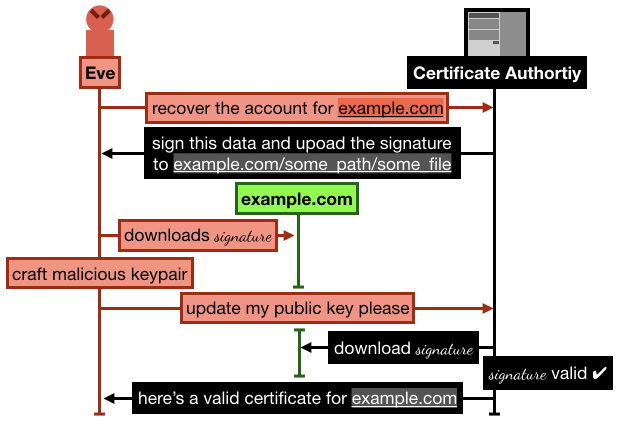
In it, Andrew proposes a way to gain control of a Let's Encrypt account that has already validated a domain (let's say example.com)
The attack goes like this:
- Alice registers and goes through the process of verifying her domain
example.com by uploading some signature over some data on example.com/.well-known/acme-challenge/some_file. She then successfully manages to obtain a certificate from Let's Encrypt.
- Later, Eve signs up to Let's Encrypt with a new account and new RSA public key, and request to recover the
example.com domain
- Let's Encrypt asks Eve to sign some new data, and upload it to
example.com/.well-known/acme-challenge/some_file (note that the file is still lingering there from Alice's previous domain validation)
- Eve crafts a new malicious keypair, and updates her public key on Let's Encrypt. She then asks Let's Encrypt to check the signature
- Let's Encrypt obtains the signature file from
example.com, the signature matches, Eve is granted ownership of the domain example.com.
I recapitulate the attack in the following figure:
Wait what?
What happened there?
Key Substitution Attack With RSA
In the above attack Eve managed to create a valid public key that validates a given signature and message.
This is because, as Andrew Ayer wrote:
A digital signature does not uniquely identify a key or a message
If you remember how RSA works, this is actually not too hard to understand.
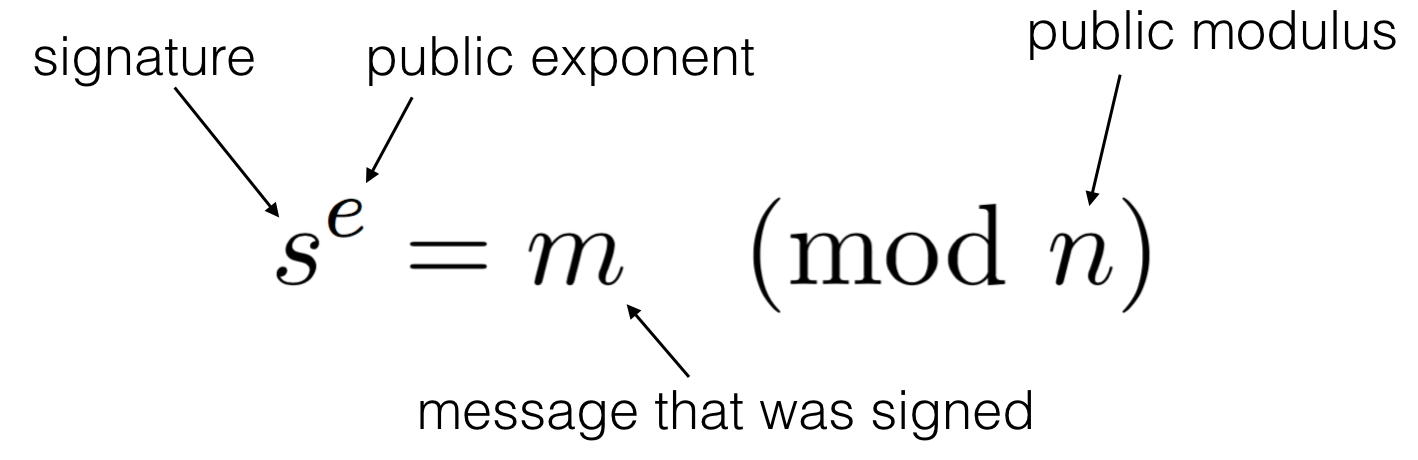
For a fixed signature and (PKCS#1 v1.5 padded) message, a public key (e, N) must satisfy the following equation to validate the signature:
\(\text{signature} = \text{message}^e \pmod{N}\)
One can easily craft a public key that will (most of the time) satisfy the equation:
- \(e = 1\)
- \(N = \text{signature} - \text{message}\)
You can easily verify that the validation works:
$$
\begin{align}
&\text{signature} = \text{message}^e \pmod{N}\\
\iff&\text{signature} = \text{message} \pmod{\text{signature} - \text{message}}\\
\iff&\text{signature} - \text{message} = 0 \pmod{\text{signature} - \text{message}}
\end{align}
$$
By definition the last line is true.
Security of Cryptographic Signatures
Is this issue surprising?
It should be.
And if so why?
This is because of the gap that exists between the theoretical world and the applied world, between the security proofs and the implemented protocol.
Signatures in cryptography are usually analyzed with the EUF-CMA model, which stands for Existential Unforgeability under Adaptive Chosen Message Attack.
In this model YOU generated a key pair, and then I request YOU to sign a number of arbitrary messages. While I observe the signatures you produce, I win if I can at some point in time produce a valid signature over a message I hadn't requested.
Unfortunately, even though our modern signature schemes seem to pass the EUF-CMA test fine, they tend to exhibit some surprising properties.
Subtle Behaviors of Signature Schemes
The excellent paper Seems Legit: Automated Analysis of Subtle Attacks on Protocols that Use Signatures by Dennis Jackson, Cas Cremers, Katriel Cohn-Gordon, and Ralf Sasse attempts to list these surprising properties and the signature schemes affected by them (and then find a bunch of these in protocols using formal verification, it's a cool paper read it).

Let me briefly describe each properties:
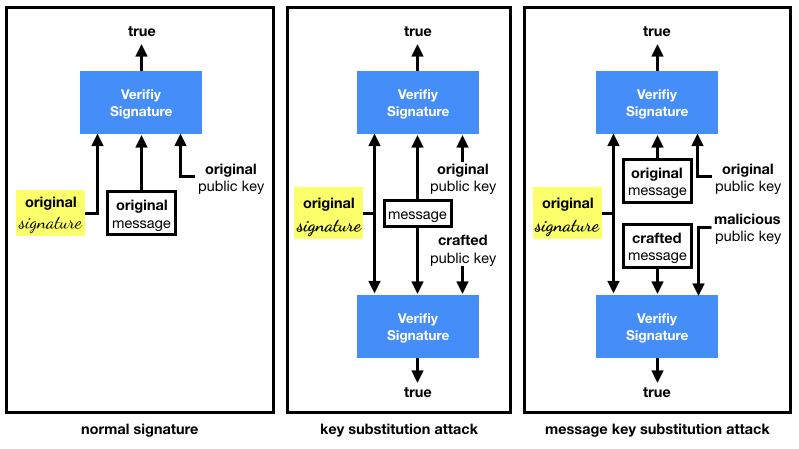
Conservative Exclusive Ownership (CEO)/Destructive Exclusive Ownership (DEO). This refers to what Koblitz and Menezes used to call Duplicate Signature Key Selection (DSKS). In total honesty, I don't think any of these terms are self-explanatory. I find these attacks easier to remember if thought of as the following two variants:
- key substitution attacks (CEO), where a different keypair or public key is used to validate a given signature over a given message.
- message key substitution attacks (DEO), where a different keypair or public key is used to validate given signature over a new message.
To recap: the first attack fixes both the message and the signature, the second one only fixes the signature.
Malleability. Most signature schemes are malleable, meaning that if you give me a valid signature I can tamper with it so that it becomes a different but still valid signature. Note that if I'm the signer I can usually create different signatures for the same message, but here malleability refers to the fact that someone who has zero knowledge of the private key can also create a new valid signature for the same signed message. It is not clear if this has any impact on any real world protocol, eventhough the bitcoin MtGox exchange blamed their loss of funds on this one. From the paper Bitcoin Transaction Malleability and MtGox:
In February 2014 MtGox, once the largest Bitcoin exchange, closed and filed for bankruptcy claiming that attackers used malleability attacks to drain its accounts.
Note that a newer security model called SUF-CMA (for strong EUF-CMA) attempts to include this behavior in the security definition of signature schemes, and some recent standards (like RFC 8032 that specifies Ed25519) are mitigating malleability attacks on their signature schemes.
Re-signability. This one is simple to explain. To validate a signature over message you often don't need the message itself but its digest. This would allow anyone to re-sign the message with their own keys without knowing the message itself. How is this impactful in real world protocols? Not sure, but we never know.
Collidability. This is another not-so-clear if it'll bite you one day: some schemes allow you to craft signatures that will validate under several messages. Worse, Ed25519 as designed allows one to craft a public key and a signature that would validate any message with high probability. (This has been fixed in some implementations like libsodium.)
I recapitulate the substitution attacks in the diagram below:
What to do with all of this information?
Well, for one signature schemes are definitely not broken, and you probably shouldn't worry if your use of them are mainstream.
But if you're designing cryptographic protocols, or if you're implementing something that's more complicated than the every day use of cryptography you might want to keep these in the back of your mind.
 Did you like this content? This is part of a book about how to apply modern cryptography in real world applications. Check it out!
Did you like this content? This is part of a book about how to apply modern cryptography in real world applications. Check it out!
(part 1 is here)
Writing about real world cryptography, it seems like what I end up writing a lot about is protocols and how they solve origin/identity authentication.
Don't get me wrong, confidentiality has interesting problems to (e.g. how to bring confidentiality to a blockchain), but authentication is most of what applied cryptography is about, for realz.
Do I need to convince you?
If you think about it, most protocols are about finding ways to provide authentication to different scenarios. And that's why they can get complicated!
I'll take my life for example, here is the authentication problems and solutions that I use:
- insecure → one-side authenticated. Every day I use HTTPS, which uses the web public-key infrastructure (web PKI) to allow my browser to authenticate any websites on the web. It's a mess, but that's how you scale machine-to-machine authentication nowadays.
- one-side authenticated → mutually-authenticated. Whenever I log into a website, over a secure HTTPS connection, this is what happens. A machine asks me to present some password (in clear, or oblivious via an asymmetric password-authenticated key exchange), or maybe a one-time password (via TOTP), or maybe I'll have to press my thumb on a yubikey (FIDO 2), or maybe I'll have to do a combination of several things (MFA). These are usually machine authenticating humans-type of flow.
- insecure → mutually-authenticated. Whenever I talk to someone on Signal, or connect to a new WiFi, or pair a bluetooth device (like my phone with a car), I go from an insecure connection to a mutually-authenticated connection. There is a bit more nuance here, as sometimes I'll authenticate a machine (a WiFi access point for example) and sometimes I'll authenticate a human (end-to-end encryption). So different techniques work best depending on the type of peer you're trying to talk to.
In the end, I think these are the main three big categories of origin authentication.
Can you think of a better classification?
There is a whole field of authentication in cryptography that is often under-discussed (at least in my opinion).
See, we often like to talk about how key exchanges can also be authenticated, by mean of public-key infrastructures (e.g. HTTPS) or by pre-exchanging secrets (e.g. my previous post on sPAKE), but we seldom talk about post-handshake authentication.
Post-handshake authentication is the idea that you can connect to something (often a hardware device) insecurely, and then "augment" the connection via some information provided in a special out-of-band channel.
But enough blabla, let me give you a real-world example: you link your phone with your car and are then asked to compare a few digits (this pairing method is called "numeric comparison" in the bluetooth spec). Here:
- Out-of-band channel. you are in your car, looking at your screen, this is your out-of-band channel. It provides integrity (you know you can trust the numbers displayed on the screen) but do not necessarily provide confidentiality (someone could look at the screen through your window).
- Short authenticated string (SAS). The same digits displayed on the car's screen and on your phone are the SAS! If they match you know that the connection is secure.
This SAS thing is extremely practical and usable, as it works without having to provision devices with long secrets, or having the user compare long strings of unintelligible characters.
How to do this? You're probably thinking "easy!". An indeed it seems like we could just do a key exchange, and then pass the output in some KDF to create this SAS.
NOPE.
This has been discussed long-and-large on the internet: with key exchange protocols like X25519 it doesn't work.
The reason is that X25519 does not have contributory behavior: I can send you a public key that will lead to a predictable shared secret. In other words: your public key does not contribute (or very little) to the output of the algorithm.
The correct™ solution here is to give more than just the key exchange output to your KDF: give it your protocol transcript. All the messages sent and received. This puts any man-in-the-middle attempts in the protocol to a stop. (And the lesson is that you shouldn't naively customize a key exchange protocol, it can lead to real world failures.)
The next question is, what's more to SAS-based protocols? After all, Sylvain Pasini wrote a 300-page thesis on the subject. I'll answer that in my next post.
have you heard of sPAKE (or bPAKE)?
a sPAKE is first and foremost a PAKE, which stands for Password-Authenticated Key Exchange.
This simply means that authentication in the key exchange is provided via the knowledge of a password.
The s (resp. b) in front means symmetric (resp. balanced). This indicates that both sides know the password.

Other PAKEs where only one side knows the password exist, these are called aPAKE for asymmetric (or augmented) PAKEs.
Yes I know the nomenclature is a bit confusing :)
The most promising sPAKE scheme currently seems to be SPAKE2, which is in the process of being standardized here.
There are other sPAKEs, like Dragonfly which is used in WPA3, but they don't seem to provide as strong properties as SPAKE2.
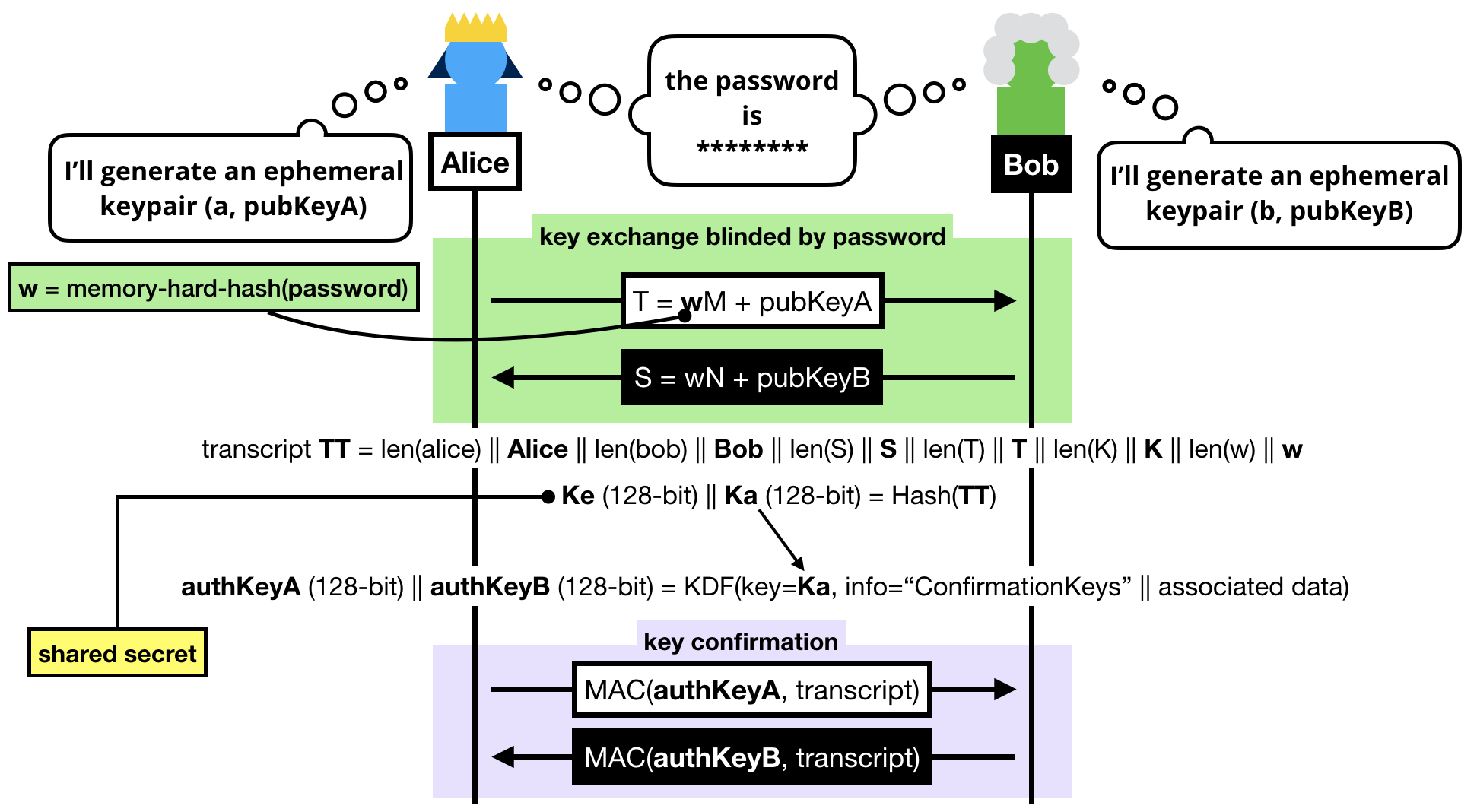
The trick to a symmetric PAKE is to use the password to blind the key exchange's ephemeral keypairs.
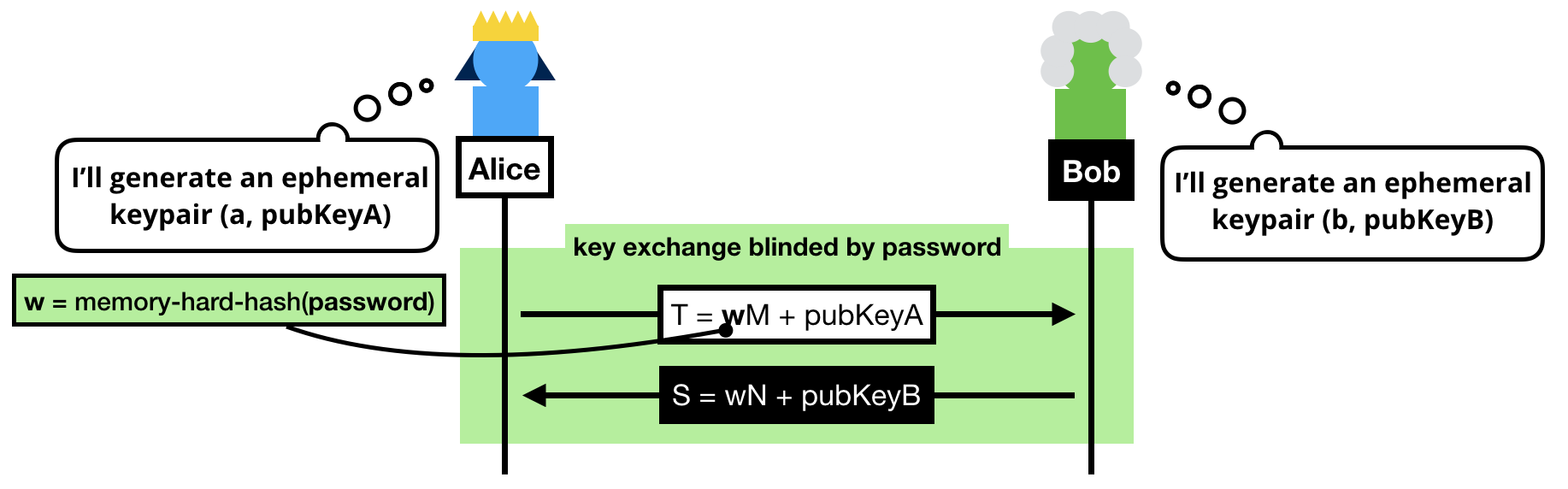
Note that we can't use the password as is, instead we:
- Pass the password into a memory-hard hash function like Argon2 to obtain
w. Can you guess why we do this? (leave a comment if you do!)
- Convert it to a group element. To do this we simply consider
w a scalar and do a scalar multiplication with a generator of our subgroup (M or N depending if you're the client or the server, can you guess why we use different generators?)
NOTE: If you know BLS or OPAQUE, you might be wondering why we don't use a "hash-to-curve" algorithm, this is because we don't need to obtain a group element with an unknown discrete logarithm in SPAKE2.
Once the blinded (with the password) public keys have been exchanged, both sides can compute a shared group element:
- Alice computes
K = h × alice_private_key × (S - w × N)
- Bob computes
K = h × bob_private_key × (T - w × M)
Spend a bit of your time to understand these equations.
What happens is that both Alice and Bob first unblind the public key they've received, then perform a key exchange with it, then multiply it with the value h. What's this value h? The cofactor, or simply put: the other annoying subgroup.
Finally Alice and Bob hash the whole transcript, which is the concatenation of:
- Alice's identity.
- Bob's identity.
- The message Bob sent
S.
- The message Alice sent
T.
- The shared group element
K.
- The hardened password
w.
The hash of this transcript gives us two things:
- A shared secret !
- A key that is further expanded (via a KDF) to obtain two authentication keys.
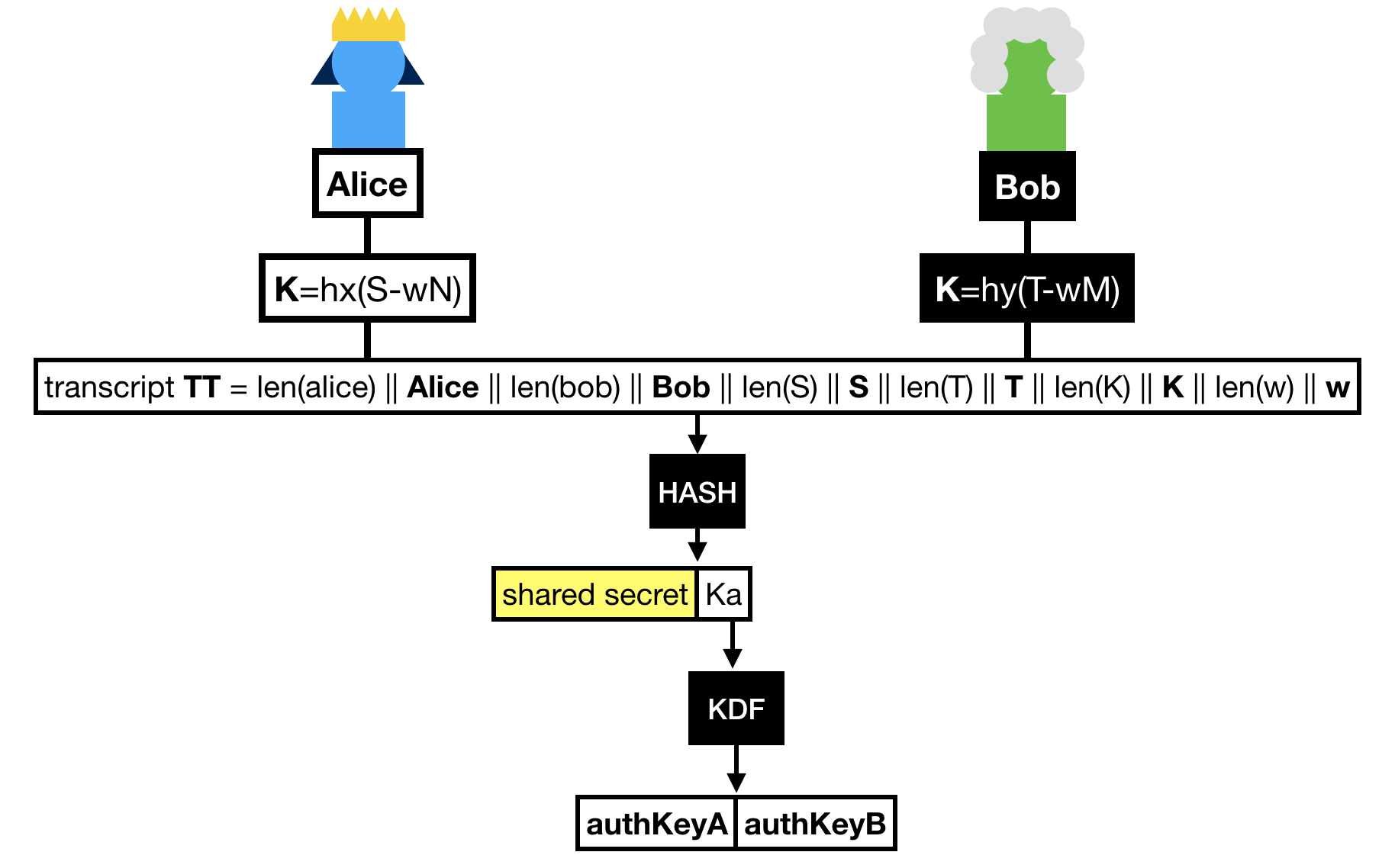
These authentication keys sole purpose is to provide key confirmation in the last round-trip of messages.
That is to say at this point, if we don't do anything, we don't know if either Alice or Bob truly managed to compute the shared secret.
Key confirmation is pretty simple, both sides just have to compute an authentication tag with one of the authentication key produced over the transcript.
The final protocol looks a bit dense, but you should be able to decipher it if you've read this far.
Authentication is an overloaded word in cryptography.
In the context of cryptographic primitives like message authentication codes (MACs) and authenticated encryption with associated data (AEAD), authentication really refers to authenticity or integrity. And as the Cambridge dictionary says:
Authenticity. the quality of being real or true.
The poems are supposed to be by Sappho, but they are actually of doubtful authenticity.
The authenticity of her story is beyond doubt.
The proof is in the pudding. When talking about the security properties of primitives like MACs, cryptography talks about unforgeability, which does relate to authenticity.
So whenever you hear things like "is this payload authenticated with HMAC?", think authenticity, think integrity.
In the context of protocols though (e.g. TLS) authentication refers to identification: the concept of proving who you are.
So whenever you hear things like "Is the server authenticated?", think "identities are being proven".
This dual sense really annoys me, but in the end this ambiguity is encompassed in the definition of authentication:
the process or action of proving or showing something to be true, genuine, or valid.
Diego F. Aranha proposes a clever way to disambiguate the two:
- origin/entity authentication. You're proving that an entity really is who they say they are.
- message authentication. You're proving that a message is genuine.
Note that an argument against this distinction is the following: to authenticate a message, you need a key. This key comes from somewhere (it's your context, or your "who"). So when you authenticate a message, you are really authenticating the context. This falls short in scenarios where for example you trust the root hash of a merkle tree, which authenticates all of its leaves.
The bottom line is, authentication is about proving that something is what it is supposed to be. And that thing can be a person, or a message, or maybe even something else.
This is not all. In the security world people are confused with authorization vs authentication :)
(part 2 is here)
I've been following the Messaging Layer Security (MLS) standardization a bit.
I really appreciate what the people are doing there, and what they are trying to solve.
I think group messaging is currently a huge mess, as every application I have seen/audited seemed to invent a new way to implement group chat.
A common standard and guidelines would greatly help.
MLS' goal is to provide a solution to end-to-end encryption for group chats. A solution that scales.
If you don't know how the MLS protocol works, I advise you to read Michael Rosenberg's blog post or to watch the Real World Crypto talk on the subject (might not be available at the moment).
Thinking about the standard, I have two questions:
- Does a group chat loses any notion of privacy/confidentiality after it gets too large? For example, if you are in a Hong Kong group trying to organize a protest and there are more than 1,000 people in the group, what are the odds that one of them is a cop?
- Would a group chat protocol targeting groups with small numbers of participant (let's say 50 at most) be able to provide better security insurances efficiently?
For example, here are two security properties (taken from SoK: Secure Messaging) that MLS does not provide:
Speaker Consistency: All participants agree on the sequence of messages sent by each participant.
This means that if Alice (who is part of a group chat with Bob and Eve) colludes with the server, she can send "I like cats" to Bob and "I like dogs" to Eve.
Global Transcript: All participants see all messages in the same order. Note that this implies speaker consistency
This means that if Alice sends the following messages:
- you must decide
- your path
a server could re-order these messages so that Bob would see them in the same order, but Eve would see:
- your path
- you must decide

I have the following open questions:
- Are these attacks important to protect against?
- Is there an efficient protocol to prevent these attacks for groups of reasonable size?
- If we cannot prevent them, can we detect them and warm the users?
- If we are willing to change the protocol when going from 2 participants to 3 participants, would be willing to change the protocol when going from N to N+1 participants (where N is the number of participants threshold where confidentiality/privacy fades away)?
This is were everything starts, we now have an open peer-to-peer protocol that everyone on the internet can use to communicate.
- 1991
- The US government introduces the 1991 Senate Bill 266, which attempts to allow "the Government to obtain the plain text contents of voice, data, and other communications when appropriately authorized by law" from "providers of electronic communications services and manufacturers of electronic communications service equipment". The bill fails to pass into law.
- Pretty Good Privacy (PGP) - released by Phil Zimmermann.
- 1993 - The US Government launches a criminal investigation against Phil Zimmermann for sharing a cryptographic tool to the world (at the time crypto exporting laws are a thing).
- 1995 - Zimmermann publishes PGP's source code in a book via MIT Press, dodging the criminal investigation by using the first ammendment's protection of books.
That's it, PGP is out there, people now have a weapon to fight government surveillance. As Zimmermann puts it:
PGP empowers people to take their privacy into their own hands. There's a growing social need for it. That's why I wrote it.
- 1995 - The RSA Data Security company proposes S/MIME as an alternative to PGP.
- 1996
- 1997
- GNU Privacy Guard (GPG) - version 0.0.0 released by Werner Koch.
- PGP 5 is released.
The original agreement between Viacrypt and the Zimmermann team had been that Viacrypt would have even-numbered versions and Zimmermann odd-numbered versions. Viacrypt, thus, created a new version (based on PGP 2) that they called PGP 4. To remove confusion about how it could be that PGP 3 was the successor to PGP 4, PGP 3 was renamed and released as PGP 5 in May 1997
- 1997 - PGP Inc is acquired by Network Associates
- 1998 - RFC 2440 - OpenPGP Message Format
OpenPGP - This is a definition for security software that uses PGP 5.x as a basis.
- 1999
- GPG version 1.0 released
- Extensible Messaging and Presence Protocol (XMPP) is developed by the open source community. XMPP is a federated chat protocol (users can run their own servers) that does not have end-to-end encryption and requires communications to be synchronous (both users have to be online).
- 2002 - PGP Corporation is formed by ex-PGP members and the PGP license/assets are bought back from Network Associates
- 2004 - Off-The-Record (OTR) is introduced by Nikita Borisov, Ian Avrum Goldberg, and Eric A. Brewer as an extension of the XMPP chat protocol in "Off-the-Record Communication, or, Why Not To Use PGP"
We argue that [...] the encryption must provide perfect forward secrecy to protect from future compromises [...] the authentication mechanism must offer repudiation, so that the communications remain personal and unverifiable to third parties
We now have an interesting development: messaging (which is seen as a different way of communication for most people) is getting the same security treatment as email.
- 2006 - GPG version 2.0 released
- 2007 - RFC 4880 - OpenPGP Message Format
- 2010 - Symantec purchases the rights for PGP for $300 million.
- 2011 - Cryptocat is released.
- 2013 - The TextSecure (now Signal) application is introduced, built on top of the TextSecure protocol with Axolotl (now the Signal protocol with the double ratchet) as an evolution of OTR and SCIMP. It provides asynchronous communication unlike other messaging protocols, closing the gap between messaging and email.
- 2014
PGP becomes increasingly criticized, as Matt Green puts it in 2014:
It’s time for PGP to die.
- 2015
- 2016
- Filippo Valsorda - I'm giving up on PGP
All in all, I should be the perfect user for PGP. Competent, enthusiast, embedded in a similar community. But it just didn't work.
- WhatsApp now uses the Signal protocol, adding end-to-end encryption for its billions of users.
Another unexpected development: security professionals are now giving up on encrypted emails, and are moving to secure messaging.
Is messaging going to replace email, even though it feels like a different mean of communication?
Moxie's quotes are quite interesting:
In the 1990s, I was excited about the future, and I dreamed of a world where everyone would install GPG. Now I’m still excited about the future, but I dream of a world where I can uninstall it.
In addition to the design philosophy, the technology itself is also a product of that era. As Matthew Green has noted, “poking through an OpenPGP implementation is like visiting a museum of 1990s crypto.” The protocol reflects layers of cruft built up over the 20 years that it took for cryptography (and software engineering) to really come of age, and the fundamental architecture of PGP also leaves no room for now critical concepts like forward secrecy.
In 1997, at the dawn of the internet’s potential, the working hypothesis for privacy enhancing technology was simple: we’d develop really flexible power tools for ourselves, and then teach everyone to be like us. Everyone sending messages to each other would just need to understand the basic principles of cryptography. [...]
The GnuPG man page is over sixteen thousand words long; for comparison, the novel Fahrenheit 451 is only 40k words. [...]
Worse, it turns out that nobody else found all this stuff to be fascinating. Even though GPG has been around for almost 20 years, there are only ~50,000 keys in the “strong set,” and less than 4 million keys have ever been published to the SKS keyserver pool ever. By today’s standards, that’s a shockingly small user base for a month of activity, much less 20 years.
- 2018
- the first draft of Messaging Layer Security (MLS) is published, a standard for end-to-end encrypted group chat protocols.
- EFAIL releases damaging vulnerabilities against most popular PGP and S/Mime implementations.
In a nutshell, EFAIL abuses active content of HTML emails, for example externally loaded images or styles, to exfiltrate plaintext through requested URLs. To create these exfiltration channels, the attacker first needs access to the encrypted emails, for example, by eavesdropping on network traffic, compromising email accounts, email servers, backup systems or client computers. The emails could even have been collected years ago.
- 2019 - Latacora - The PGP Problem
Why do people keep telling me to use PGP? The answer is that they shouldn’t be telling you that, because PGP is bad and needs to go away.
EFAIL is the straw that broke the camel's back. PGP is officially dead.
- 2019
- Matrix is out of beta and working on making end-to-end encryption the default.
- Moxie gives a controversial talk at CCC arguing that advancements in security, privacy, censorship resistance, etc. are incompatible with slow moving decentralized protocols. Today, most serious end-to-end encrypted messaging apps use the Signal protocol (Signal, Facebook Messenger, WhatsApp, Skype, etc.)
- XMPP's response: Re: the ecosystem is moving
- Matrix's response: On privacy versus freedom
did you like this? This will part of a book on cryptography! Check it out here.
That title is a mouthful! But so is the field.
Let me introduce the problem: Alice owns a private key which can sign transactions. The problem is that she has a lot of money, and she is scared that someone will target her to steal all of her funds.
Cryptography offers some solutions to avoid this being a key management problem.
The first one is called Shamir Secret Sharing (SSS), which is simply about splitting the signing private key into n shares.
Alice can then split the shares among her friends. When Alice wants to sign a transaction, she would then have to ask her friends to give her back the shares, that she can use to recreate the signing private key. Note that SSS has many many variants, for example VSSS allows participants to verify that malicious shares are not being used, and PSSS allows participants to proactively rotate their shares.
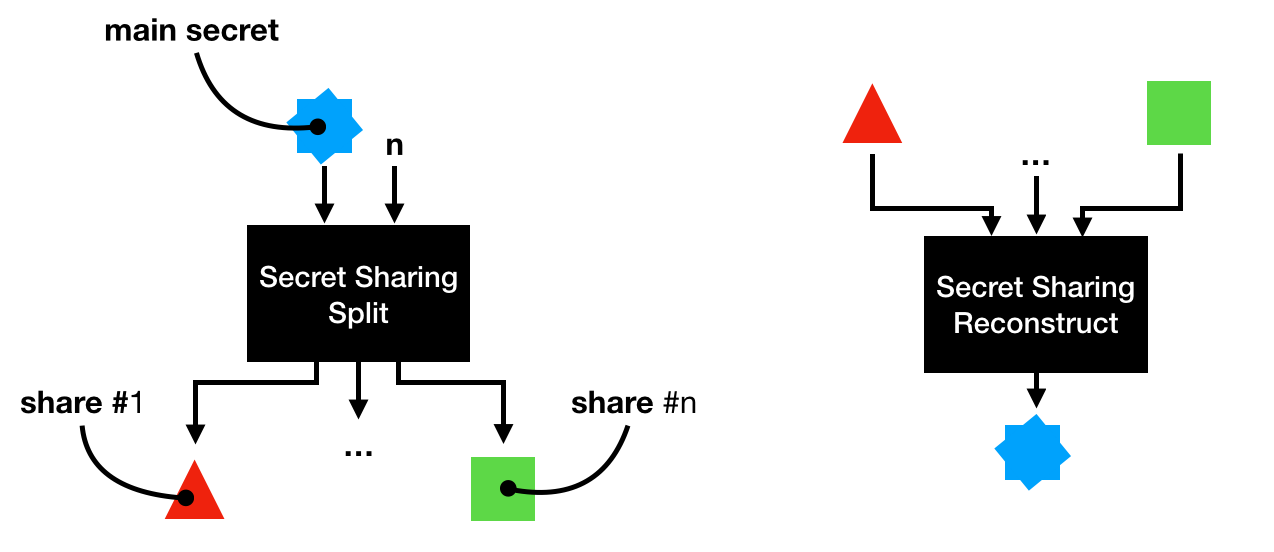
This is not great though, as there is a small timeframe in which Alice is the single point of failure again (the moment she holds all the shares).
A logical next step is to change the system, so that Alice cannot sign a transaction by herself.
A multi-signature system (or multisig) would require n participants to sign the same transaction and send the n signatures to the system.
This is much better, except for the fact that n signatures means that the transaction size increases linearly with the number of signers required.
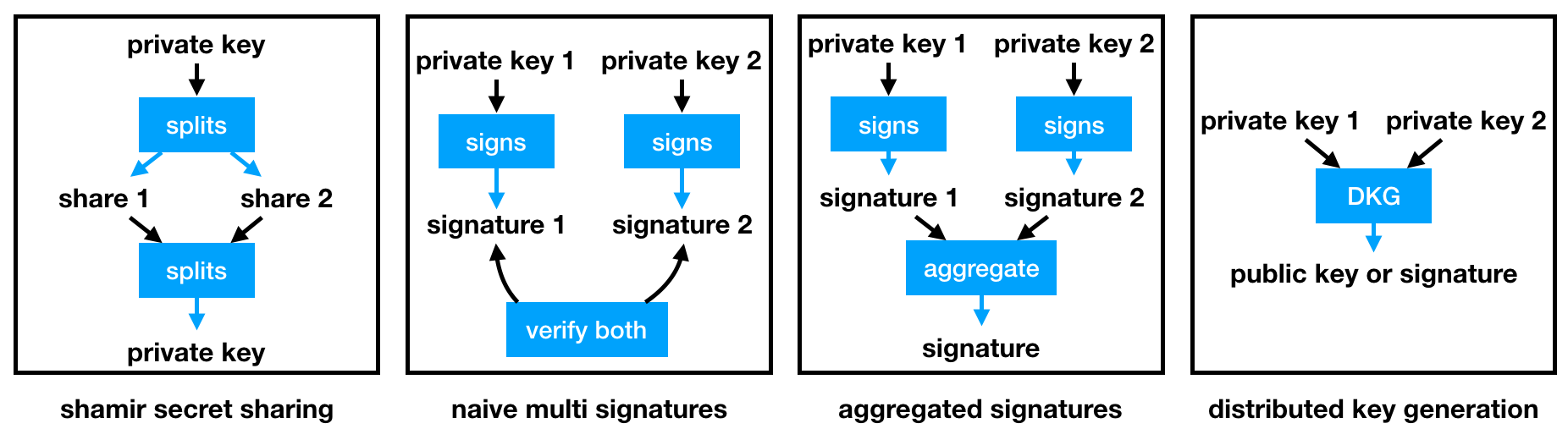
We can do better: a multi-signature system with aggregated signatures. Signature schemes like BLS allow you to compress the n signatures in a single signature. Note that it is currently much slower than popular signature schemes like ECDSA and EdDSA, so there must be a trade off between speed and size.
We can do even better though!
So far one still has to maintain a set of n public keys so that a signature can be verified. Distributed Key Generation (DKG) allows a set of participant to collaborate on the construction of a key pair, and on signing operations.
This is very similar to SSS, except that there is never a single point of failure. This makes DKG a Multi-Party Computation (MPC) algorithm.
The BLS signature scheme can also aggregate public keys into a single key that will verify their aggregated signatures, which allows the construction of a DKG scheme as well.
Interestingly, you can do this with schnorr signatures too! The following diagram explains a simplified version of the scheme:
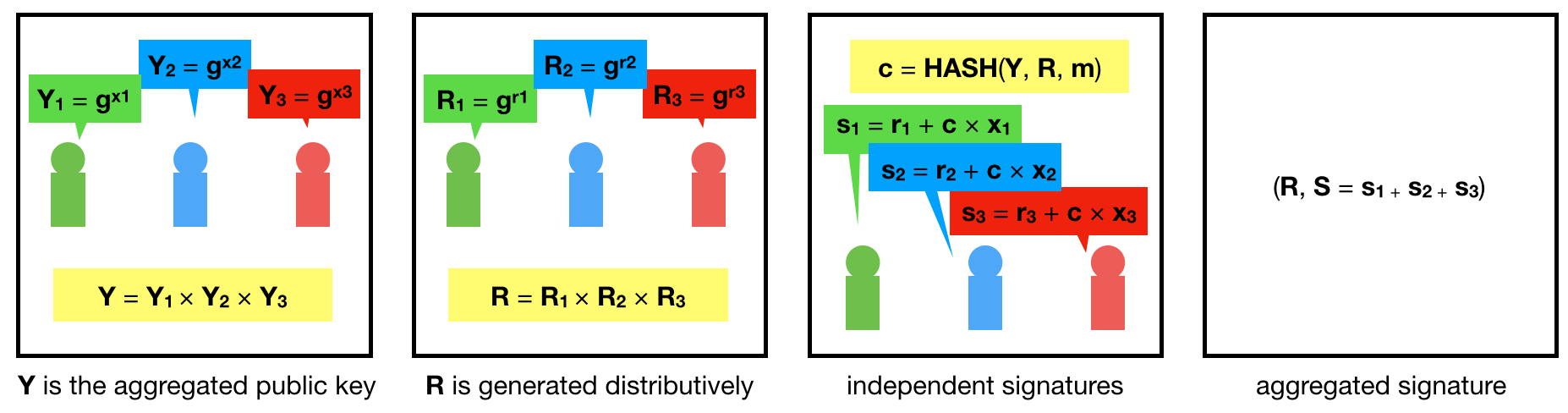
Note two things:
- All these schemes can be augmented to become threshold schemes: we don't need n signatures from the n signers anymore, but only a threshold m of n. (Having said that, when people talk about threshold signatures, they often mean the threshold version of DKG.) This way if someone loses their keys, or is on holiday, we can still sign.
- Most of these schemes assume that all participants are honest and by default don't tolerate malicious participants. More complicated schemes made to tolerate malicious participants exist.
Unfortunately all of this is pretty new, and as an active field of study no standard has been decided on one algorithm so far.
That's the difference!
One last thing: there's been some recent ideas to use zero knowledge proofs (ZKP) to do what aggregated signatures do but for multiple messages (because all the previous solutions all signed the same message). The idea is to release a proof that you have verified all the signatures associated to a set of messages. If the zero knowledge proof is shorter than all the signatures, it did its job!
did you like this? This will part of a book on cryptography! Check it out here.
EDIT: thanks to Dowhile and bascule for pointing errors in the post.
