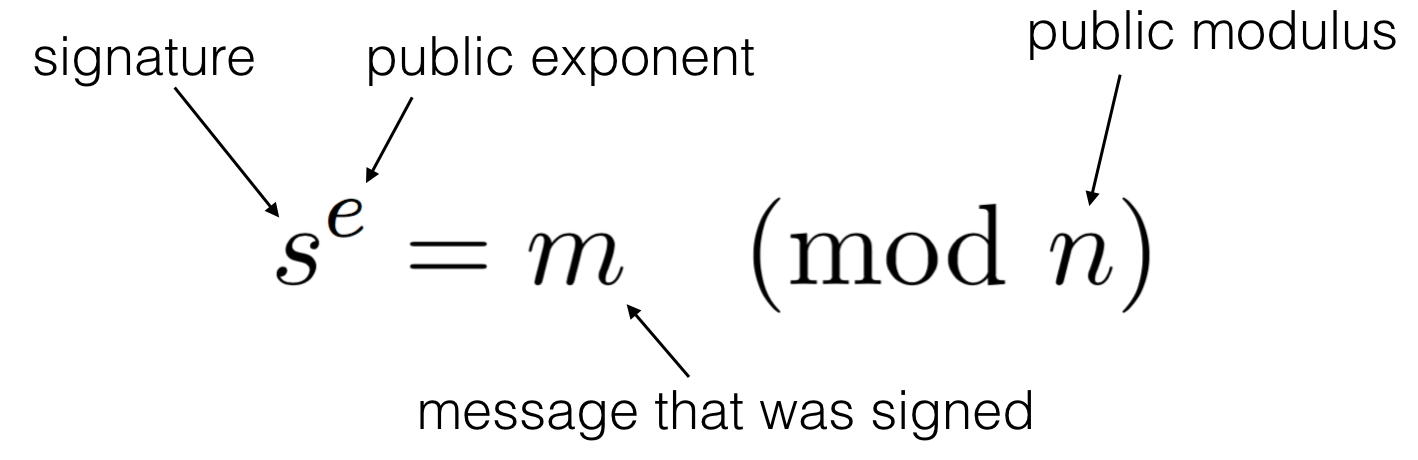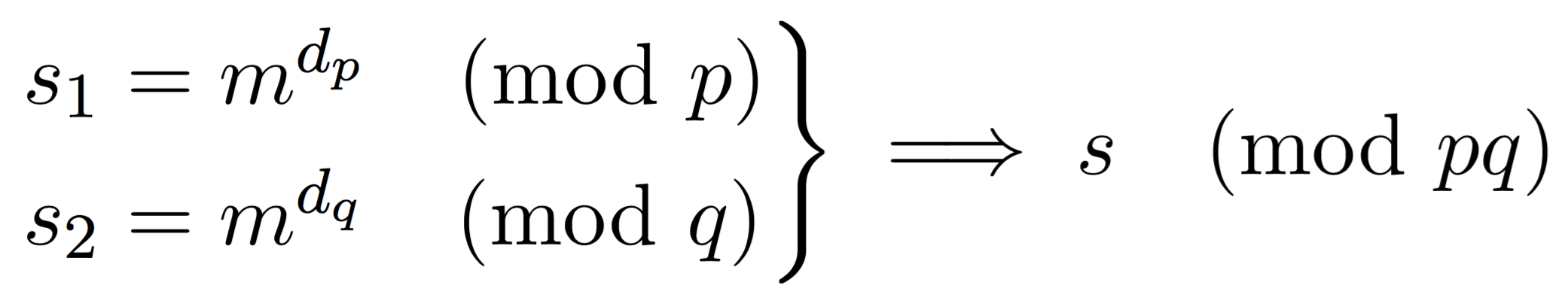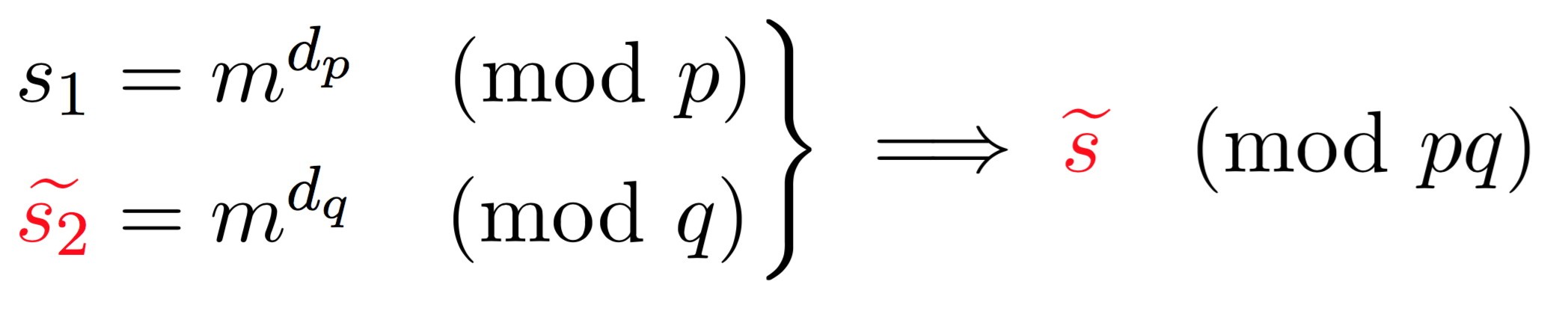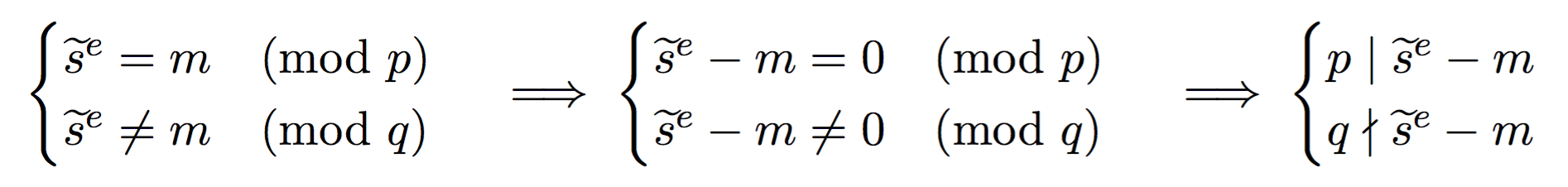Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
I see some discussions on some mailing lists about what parameters to use for Diffie-Hellman (DH).
It seems like the recent line of papers about weak Diffie-Hellman parameters (Logjam) and Diffie-Hellman backdoors (socat, the RFC 5114, the special primes, ...) has troubled more than one.
This is a non-problem. We don't need a RFC to choose Diffie-Hellman groups. A simple openssl gendh -out keyfile -2 2048 will generate a 2048-bit safe prime along with correct DH parameters for you to use. If you're worried about "special primes" issues, either make it yourself with this command, or pick a larger (let's say 4096-bit safe prime) from a list and verify that it's a safe prime. You can use this tool for that.
But since some people really don't want to do the work, here are some safe parameters you can use.
2048-bit parameters for Diffie-Hellman
Here's is the .pem file containing the parameters:
The Cryptography Services team of NCC Group is looking for a summer 2017 intern!
We are looking for you if you're into cryptography and security! The internship would allow you to follow consultants on the job as well as lead your own research project.
Who are we? We are consultants! Big companies come to us and ask us to hack their stuff (legally), review their code and advise on their design. If we're not doing that, we spend our time reading papers, researching, attending conferences, giving talks and teaching classes, ... whatever floats our boat. Not one week is like the other! If you've spent some time doing cryptopals challenges you will probably like what we are doing.
We can't say much about who are the clients we work for, except for the public audits we sometimes do. For example we've performed public audits for TrueCrypt, OpenSSL, Let's Encrypt, Docker and more recently Zcash.
I was myself the first intern of Cryptography Services and I'd be happy to answer any question you might have =)
I wrote a gist here on certificate validation/creation pitfalls. I don't know if it is up for release but I figured I would get more input, and things to add to it, if I would just released it. So, go check it out and give me your feedback here!
Here's a copy of the current version:
Certificate validation/creation pitfalls
A x509 certificate, and in particular the latest version 3, is the standard for authentication in Public Key Infrastructures (PKIs). Think about Google proving that he's Google before you can communicate with him.
So. Heh. This x509 thing is a tad complicated. Trying to parse such a thing usually end up in the creation of a lot of different vulnerabilities. I won't talk about that here. I will talk about the other complicated thing about them: using them correctly!
So here's a list of pitfalls in the creation of such certificates, but also in the validation and use of them when encountering them in the wild wild web (or in your favorite infrastructure).
explanation: keyUsage is a field inside a x509 v3 certificate that limits the power of the public key inside the certificate. Can you only use it to sign? Or can it be used as part of a key Exchange as well (ECDH)? etc...
best practice: Specify the KeyUsage at creation, verify the keyUsage when encountering the certificate. keyCertSign should be used if the certificate is a CA, keyAgreement should be used if a key exchange can be done with the public key of the certificate.
Validity ::= SEQUENCE {
notBefore Time,
notAfter Time }
best practice: Reject certificates that have a notBefore date posterior to the current date, or that have a notAfter date anterior to the current date.
Critical extensions
explanation: x509 certificate is an evolving standard, exactly like TLS, through extensions. To preserve backward compatibility, not being able to parse an extension is often considered OK, that is unless the extension is considered critical (important).
Extension ::= SEQUENCE {
extnID OBJECT IDENTIFIER,
critical BOOLEAN DEFAULT FALSE,
extnValue OCTET STRING
-- contains the DER encoding of an ASN.1 value
-- corresponding to the extension type identified
-- by extnID
}
best practice: at creation mark every important extensions as critical. At verification make sure to process every critical extensions. If a critical extension is not recognized, the certificate MUST be rejected.
Hostname Validation
explanation:
Knowing who you're talking to is really important. A x509 certificate is tied to a specific domain/organization/email/... if you don't check who it is tied to, you are prone to impersonation attacks. Because of reasons, these things can be seen in different places in the subject field or in the Subject Alternative Name (SAN) extension. For TLS, things are standardized differently and it will always need to be checked in the latter field.
This is one of the trickier issues in this list as hostname validation is protocol specific (as you can see TLS does things differently) and left to the application. To quote OpenSSL:
One common mistake made by users of OpenSSL is to assume that OpenSSL will validate the hostname in the server's certificate
Often, implementations will just check if the subject Name contains the string mywebsite.com, or will use a vulnerable regex that either accept mywebsite.com.evil.com or evil subdomains. Check moxie's presentation (null bytes) to hear more about hostname validation failures.
best practice: During creation, check for the subject as well as the subject alternative name fields. During verification, check that the leaf certificate matches the domain/person you are talking to. If TLS is the protocol being used, check that in the subject alternative name field, only one level of wildcard is allowed and it must be on the leftmost position (*.domain.com is allowed, sub.*.domain.com is forbidden). Consult RFC 6125 for more information.
explanation: the BasicConstraints extension dictates if a certificate is a CA (can sign others) or not. If it is, it also says how many CAs can follow it before a leaf certificate.
best practice: set this field to the relevant value when creating a certificate. When validating a certificate chain, make sure that the pathLen is valid and the cA field is set to TRUE for each non-leaf certificate.
Name Constraints
explanation: the NameConstraints extension contains a set of limitations for CA certificates, on what kind of certificates can follow them in the chain.
best practice: when creating a CA certificate, be aware of the constraints chained certificates should have and document it in the NameConstraints field. When verifying a CA certificate, verify that each certificate in the certificate chain is valid according to the requirements of upper certificates.
You might have heard of KCI attacks on TLS: an attacker gets to install a client certificate on your device and can then impersonate websites to you. I had thought the attack was a highly impractical one, but looking at the video of the attack (done against facebook.com at the time) it seemed to contradict my first instinct.
I skimmed the paper and it answered some of my questions and doubts. So here's a tl;dr of it.
The issue is pretty easy to comprehend once you understand how a Diffie-Hellman key exchange works.
Imagine that you navigate to myCompany.com and you do a key exchange with both of your public keys.
your public key: \(g^a \pmod{n}\)
your company's public key: \(g^b \pmod{n}\)
where \(g\) and \(n\) are public parameters that you agreed on. Let's ignore \(n\) from now on: here, both ends can create the shared secret by doing either \((g^b)^a\) or \((g^a)^b\).
In other words, shared secret = (other dude's public key)(my private key)
If you know either one of them's private key, you can observe the other public key (it's public!) and compute the shared secret. Then you have enough to replace one of the end in the TLS communication.
That's the theory.
If you replace the client's certificate with your own keypair, or know the private key of the certificate, you can break whatever key exchange they try to do with that certificate. What I mean by "break": from a key exchange you can compute the session keys and replace any party during the following communications.
My doubts had originally came from the fact that most implementations rarely use plain Diffie-Hellman, instead they usually offer ephemeral DH or RSA-based key exchanges (which are not vulnerable to this attack). The paper brought me back to reality:
Support for fixed DH client authentication has been very recently added to the OpenSSL 1.0.2 branch.
But then how would you make the client do such a un-used key exchange? The paper washed me from doubts once again:
the attacker, under the hood, interferes with the connection initialization to facebook, and forces the client to use an insecure handshake with client authentication, requesting the previously installed certificate from the system.
Now a couple of questions come to my mind.
How does facebook have these non-ephemeral DH ciphersuites?
→ from the paper, the server doesn't even need to use a static DH ciphersuite. If it has an ECDSA certificate, and didn't specify that it's only to be used to sign then you can use it for the attack (the keyUsage field in the certificate is apparently never used correctly, the few values listed in this RFC tell you how to correctly limit the authorized usages of your public key)
How can you trigger the client to use this ciphersuite?
→ just reply with a serverHello only displaying static ECDH in its ciphersuite list (contrarily to ECDHE, notice the last E for ephemeral). Then show the real ECDSA certificate (the client will interpret that as a ECDH cert because of the fake ciphersuites) and then ask the client for the specific cert you know the private key of.
In addition to the ECDSA → ECDH trumpery, this is all possible because none of these messages are signed at that moment. They are later authenticated via the shared secret, but it is too late =) I don't know if TLS 1.3 is doing a better job in this regard.
It also seems to me that in the attack, instead of installing a client cert you could just install a CA cert and MITM ALL TLS connections (except the pinned ones). But then, this attack is more sneaky, and it's another way of doing exactly this. So I appreciate that.
Facebook was organizing a CTF last week and they needed some crypto challenge. I obliged, missed a connecting flight in Phoenix while building it, and eventually provided them with one idea I had wanted to try for quite some time. Unfortunately, as with the last challenge I wrote for a CTF, someone solved it with a tool instead of doing it by hand (like in the good ol' days). You can read the quick write up there, or you can read a more involved one here.
The challenge
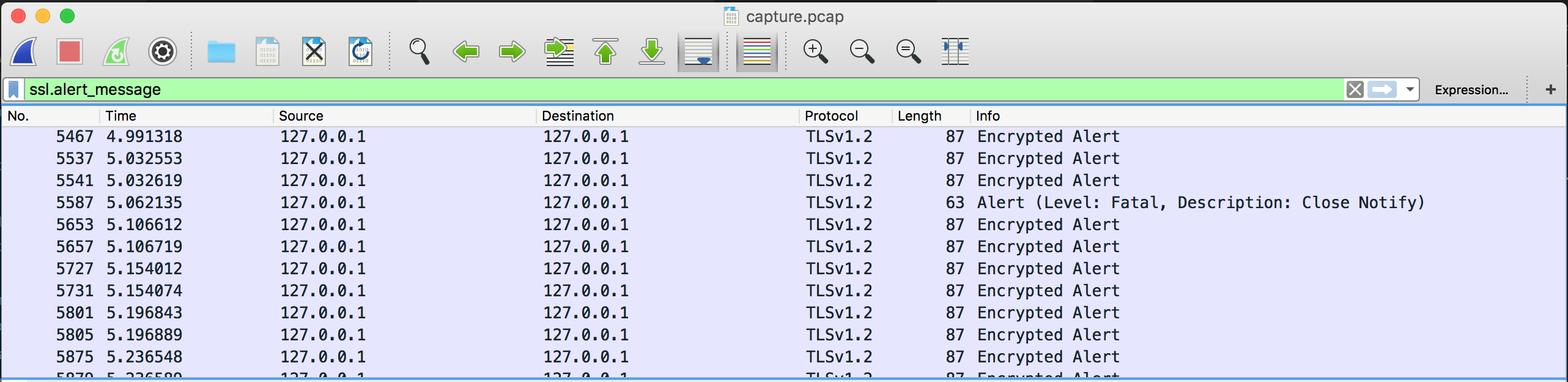
The challenge was just a file named capture.pcap. Opening it with Wireshark would reveal hundreds of TLS handshakes. One clever way to find a clue here would be to filter them with ssl.alert_message.
From that we could observe a fatal alert being sent from the client to the server, right after the server Hello Done.
Mmmm
Several hypothesis exist. One way of guessing what went wrong could be to run these packets to openssl s_client with a -debug option and see why the client decides to terminate the connection at this point of the handshake. Or if you had good intuition, you could have directly verified the signature :)
After realizing the signature was incorrect, and that it was done with RSA, one of the obvious attack here is the RSA-CRT attack! Faults happen in RSA, sometimes because of malicious reasons (lasers!) or just because of random errors that can happen in different parts of the hardware. One random bit shifting and you have a fault. If it happens at the wrong place, at the wrong time, you have a cryptographic failure!
RSA-CRT
RSA is slow-ish, as in not as fast as symmetric crypto: I can still do 414 signatures per second and verify 15775 signatures per second (according to openssl speed rsa2048).
Let's remember a RSA signature. It's basically the inverse of an encryption with RSA: you decrypt your message and use the decrypted part as a signature.
To verify a signature over a message, you do the same kind of computation on the signature using the public exponent, which gives you back the message:
We remember here that \(N\) is the public modulus used in both the signing and verifying operations. Let \(N=pq\) with \(p, q\) two large primes.
This is the basis of RSA. Its security relies on the hardness to factor \(N\).
I won't talk more about RSA here, so check Wikipedia) if you need a recap =)
It's also obvious for a lot of you reading this that you do not sign the message directly. You first hash it (this is good especially for large files) and pad it according to some specifications. I will talk about that in the later sections, as this distinction is not immediately important to us. We have now enough background to talk about The Chinese Remainder Theorem (CRT), which is a theorem we use to speed up the above equation.
So what if we could do the calculation mod \(p\) and \(q\) instead of this huge number \(N\) (usually 2048 bits)? Let's stop with the what ifs because this is exactly what we will do:
Here we compute two partial signatures, one mod \(p\), one mod \(q\). With \(d_p = d \pmod{p-1}\) and \(d_q = d \pmod{q-1}\). After that, we can use CRT to stich these partial signatures together to obtain the complete one.
Now imagine that a fault happens in one of the equation mod \(p\) or \(q\):
Here, because one of the operation failed (\(\widetilde{s_2}\)) we obtain a faulty signature \(\widetilde{s}\). What can we do with a faulty signature you may ask? We first observe the following facts on the faulty signature.
See that? \(p\) divides this value (that we can calculate since we know both the faulty signature, the public exponent \(e\), and the message). But \(q\) does not divide this value. This means that \(\widetilde{s}^e - m\) is of the form \(pk\) with some integer \(k\). What follows is naturally that \(gcd(\widetilde{s}^e - m, N)\) will give out \(p\)! And as I said earlier, if you know the factorization of the public modulus \(N\) then it is game over.
Applying the RSA-CRT attack
Now that we got that out of the way, how do we apply the attack on TLS?
TLS has different kind of key exchanges, some basic ones and some ephemeral (forward secure) ones. The basic key exchange we've used a lot in the past is pretty straight forward: the client uses the RSA public key found in the server's certificate to encrypt the shared secret with it. Then both parties derive the session keys out of that shared secret
Now, if the client and the server agree to do a forward-secure key exchange, they will use something like Diffie-Hellman or Elliptic Curve Diffie-Hellman and the server will sign his ephemeral (EC)DH public key with his long term key. In our case, his public key is a RSA key, and the fault happens during that particular signature.
Now what's the message being signed? We need to check TLS 1.2's RFC:
the client_random can be found in the client hello message
the server_random in the server hello message
the ServerDHParams are the different parameters of the server's ephemeral public key, from the same TLS 1.2 RFC:
struct {
opaque dh_p<1..2^16-1>;
opaque dh_g<1..2^16-1>;
opaque dh_Ys<1..2^16-1>;
} ServerDHParams; /* Ephemeral DH parameters */
dh_p
The prime modulus used for the Diffie-Hellman operation.
dh_g
The generator used for the Diffie-Hellman operation.
dh_Ys
The server's Diffie-Hellman public value (g^X mod p).
TLS is old, they use a non provably secure scheme to sign: PKCS#1 v1.5. Instead they should be using RSA-PSS but it's a whole different story :)
PKCS#1 v1.5's padding is pretty straight forward:
The ff part shall be long enough to make the bitsize of that padded message as long as the bitsize of \(N\)
The hash prefix part is a hexstring representing the hash function being used to sign
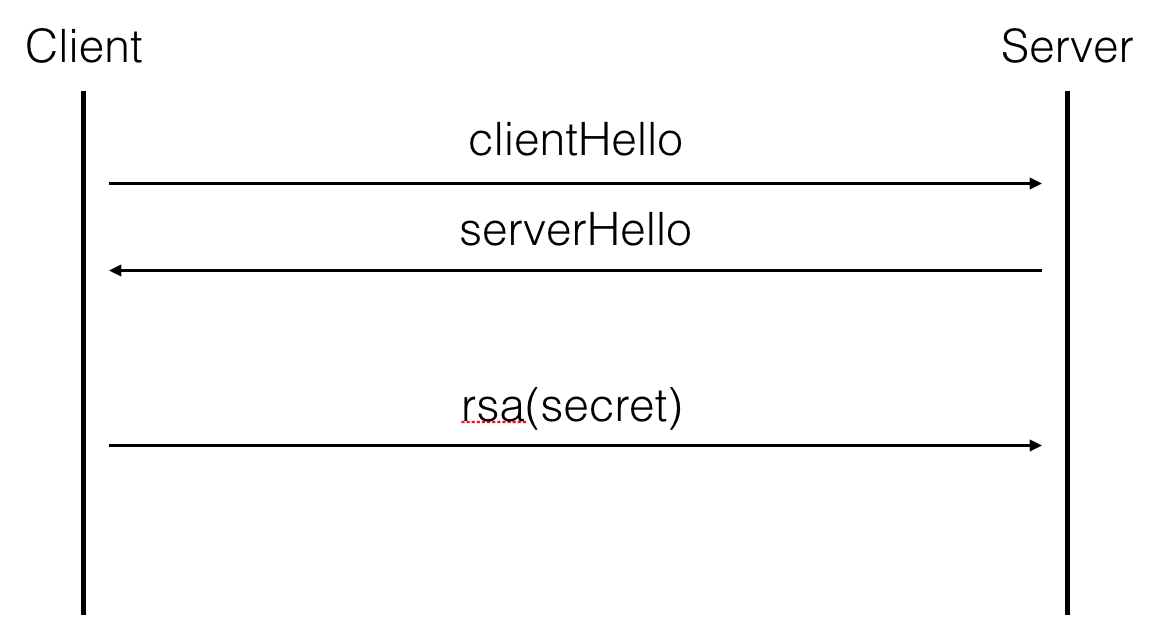
Now what? You have a private key, but that's not the flag we're looking for... After a bit of inspection you realize that the last handshake made in our capture.pcap file has a different key exchange: a RSA key exchange!!!
What follows is then pretty simple, Wireshark can decrypt conversations for you, you just need a private key file. From the previous section we retrieved the private key, to make a .pem file out of it (see this article to know what a .pem is) you can use rsatool.
There is a new attack/paper from the INRIA (Matthew Green has a good explanation on the attack) that continues the trend introduced by rc4nomore of long attacks. The paper is branded as "Sweet32" which is a collision attack playing on the birthday paradox (hence the cake in the logo) to break 64-bit ciphers like 3DES or Blowfish in TLS.
Rc4nomore was showing off with numbers like 52 hours to decrypt a cookie. This new attack needed more queries (\(2^{32}\), hence the 32 in the name) and so it took longer in practice: 75 hours. And if the numbers are correct, this should answer the question I raised in one of my blogpost a few weeks ago:
the nonce is the part that should be different for every different message you encrypt. Some increment it like a counter, some others generate them at random. This is interesting to us because the birthday paradox tells us that we'll have more than 50% chance of seeing a nonce repeat after \(2^{32}\) messages. Isn't that pretty low?
The number of queries here are the same for these 64-bit ciphers and AES-GCM. As the AES-GCM attack pointed:
we discovered over 70,000 HTTPS servers using random nonces
Does this means that 70,000 HTTPS servers are vulnerable to a 75 hours BEAST-style attack on AES-GCM?
Fortunately not, As the sweet32 paper points out, Not every server will allow a connection to be kept alive for that long. (It also seems like no browser place a limit on the amount of time a connection can be kept alive.) An interesting project would be to figure out how many of these 70,000 HTTPS servers are allowing long-lived connections.
It's good to note that these two attacks have different results as well. The sweet32 attack targets 64-bit ciphers like 3DES and Blowfish that really nobody use. The attack is completely impractical in that sense. Whereas AES-GCM is THE cipher commonly negociated. On the other hand, while both of them are Beast-style attacks, The sweet32 attack results in decrypting a cookie whereas the AES-GCM attack only allows you to redirect the user to a valid (but tampered) https page of the misbehaving website. In this sense the sweet32 attack has directly heavier consequences.
PS: Both Sean Devlin and Hanno Bock told me that the attacks are quite different in that the 64-bit one needs a collision on the IV or on a previous ciphertext. Whereas AES-GCM needs a collision on the nonce. This means that in the 64-bit case you can request for longer messages instead of querying for more messages, you also get more information with a minimum sized query than in a AES-GCM attack. This should make the AES-GCM even less practical, especially in the case of re-keying happening around the birthday bound.